
Unity Profiler 최적화
- Unity 어드레서블 최적화 방법
- Unity Profiler 최적화
- Unity 모바일 최적화 실전 가이드 - 프로파일러부터 메모리 구조까지
- 유니티 & iOS 메모리 구조에 대해

목차
유니티 프로파일러
- 에디터 환경에서 or 빌드를 통해서 간편하게 최적화를 진행할 수 있는 툴이다.
프로파일러의 구성
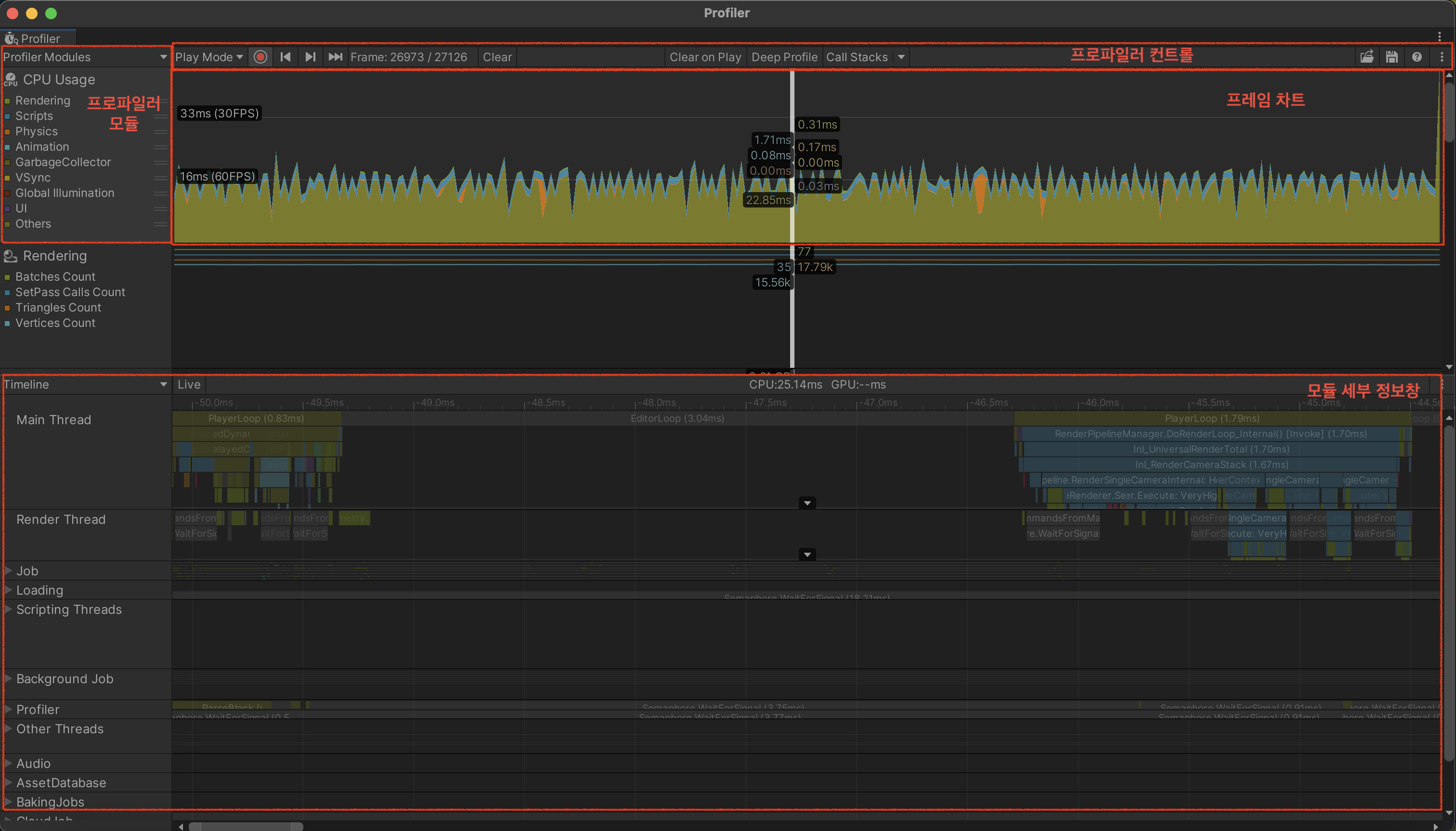
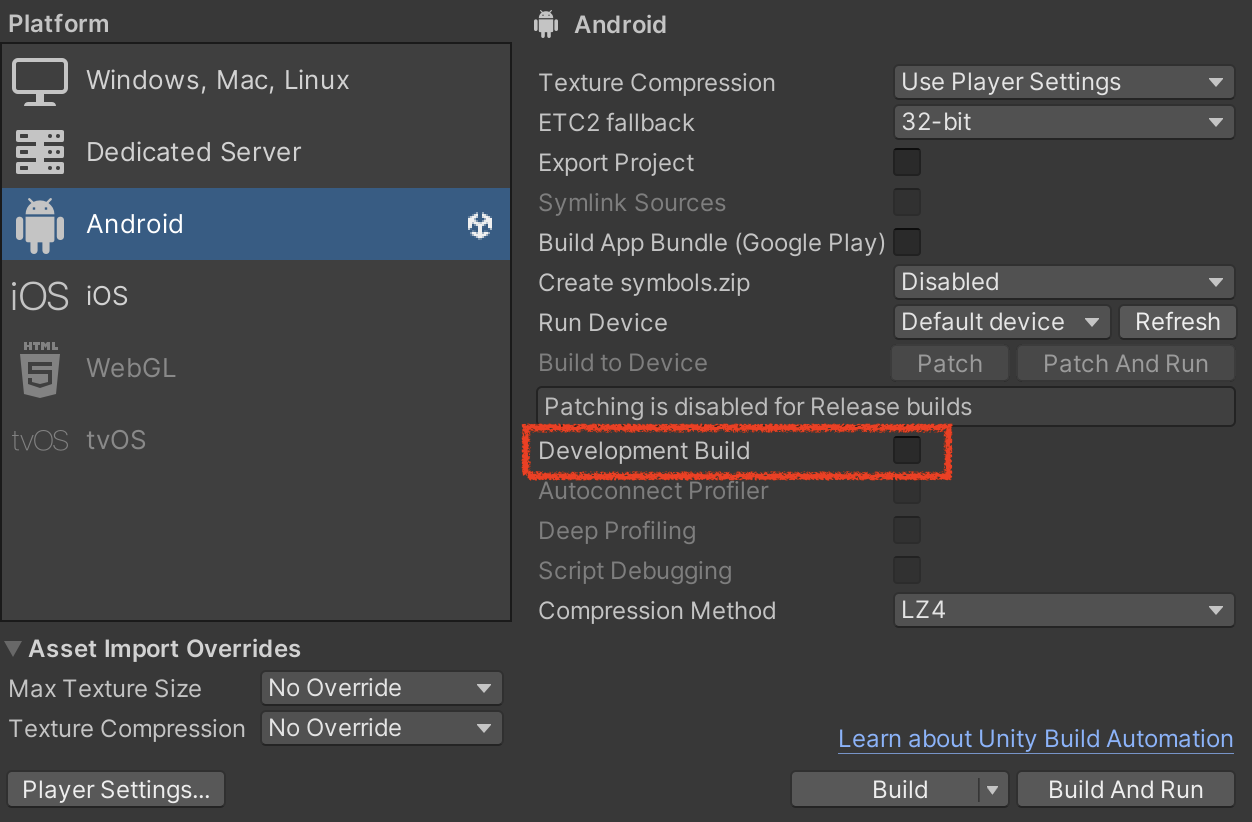
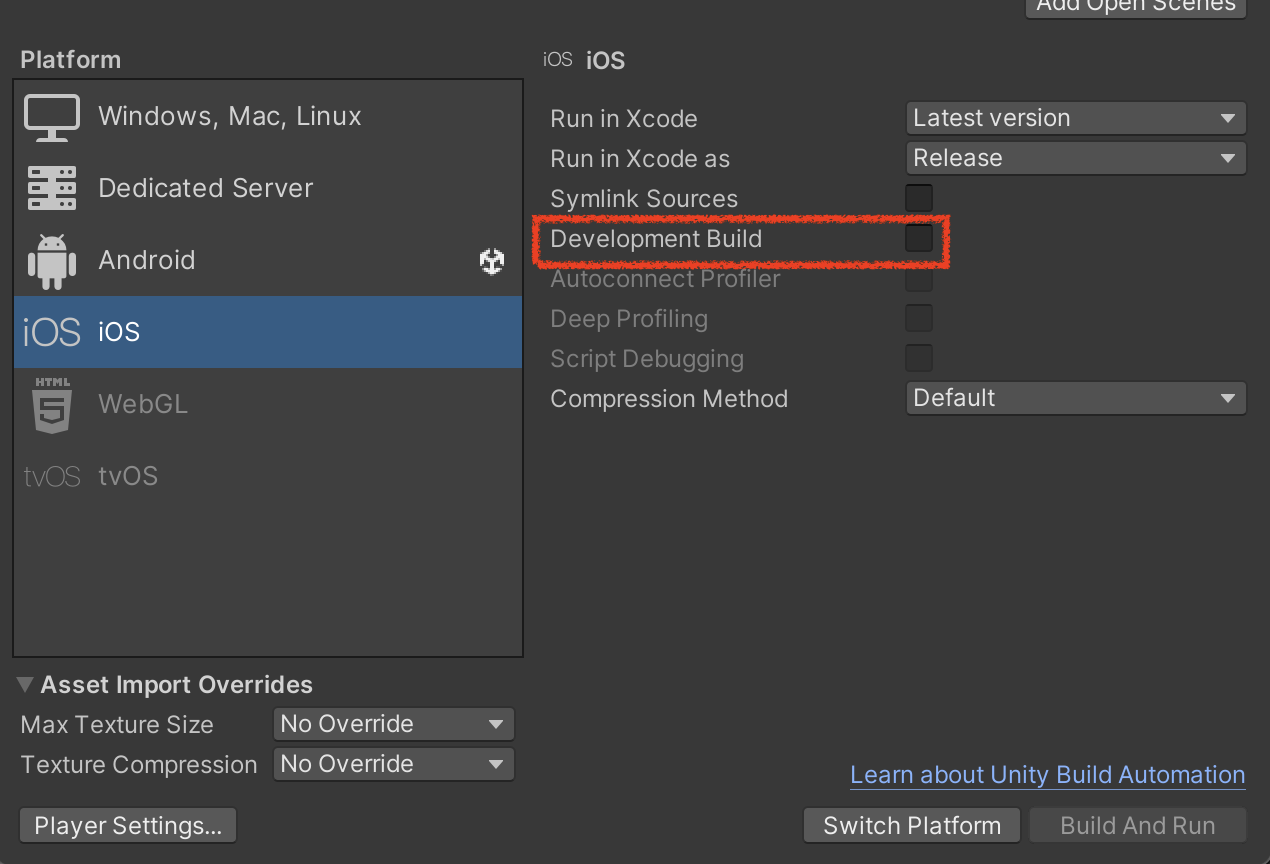
Development Build 옵션을 체크하자.
- 추가 옵션은 대부분 불필요하다. 추가옵션은 프로파일러 자동연결, 딥 프로파일링 등을 지원한다.
- 다만 여기서 자동연결은 해당 컴퓨터의 ip를 베이크하기 때문에 빌드한 컴퓨터에서만 자동연결이 가능하다.
프로파일러 - CPU 모듈
- 샘플 단위로 볼 수 있음.
- 각 처리가 CPU 시간을 얼마나 소비했는지 확인 가능.
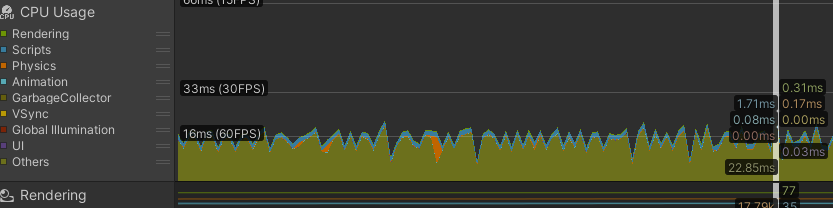
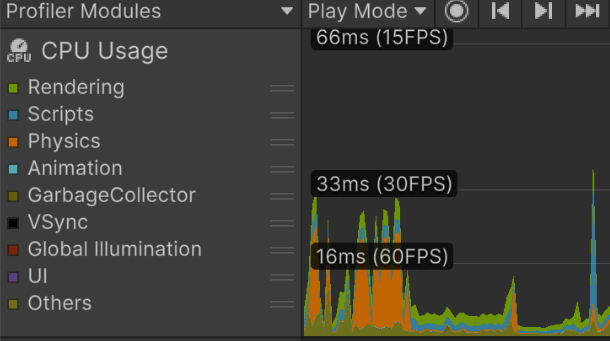
프로파일러 - 차트 창
- 평균적으로 프로젝트에서 설정한 타겟 FPS보다 빠르게 처리하는지 확인! -> 60fps 의 경우 대부분 16ms 내에 모든 처리가 끝나야한다. 30fps 는 33ms
- 그래프 과부하(스파이크)가 발생하는지 확인하자.
- vsync가 켜져있을 경우 모든 차트가 강제로 60fps 16ms로 세팅된다. 따라서 프로파일링 할 때는 vsync를 끄고 돌리자.
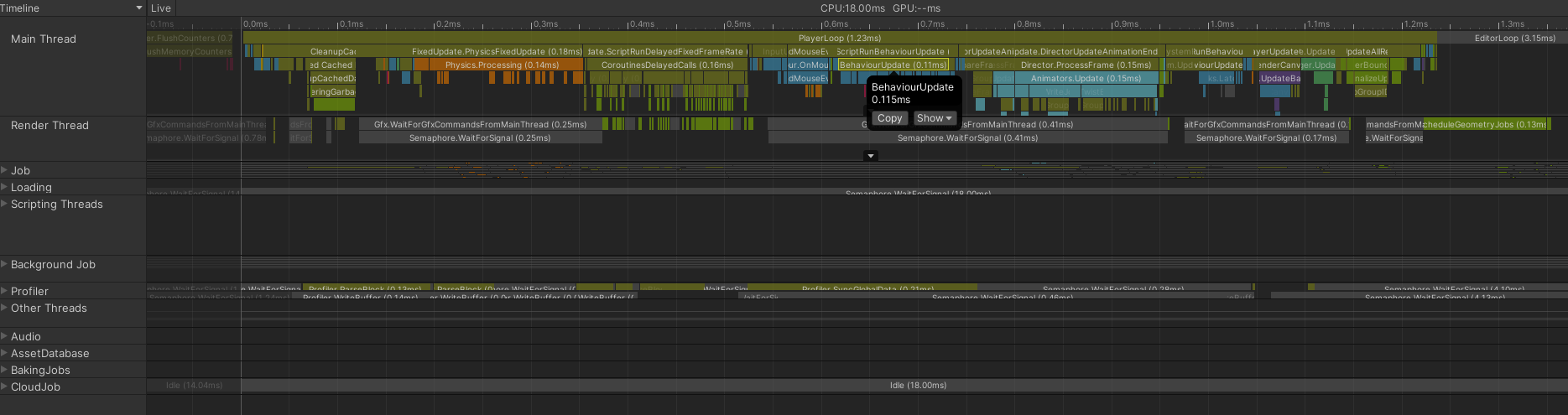
프로파일러 - 상세 창, 타임라인 뷰
- CPU 사용시간을 직관적으로 파악이 가능하다.
- 모든 스레드를 한 눈에 파악
- 함수들의 타이밍과 실행 순서 관계를 선형적으로 파악가능하다.
프로파일러 - 상세창, 계층 뷰
- 부모<->자식 호출 관계 파악
- 원하는 지표를 기준으로 정렬이 가능
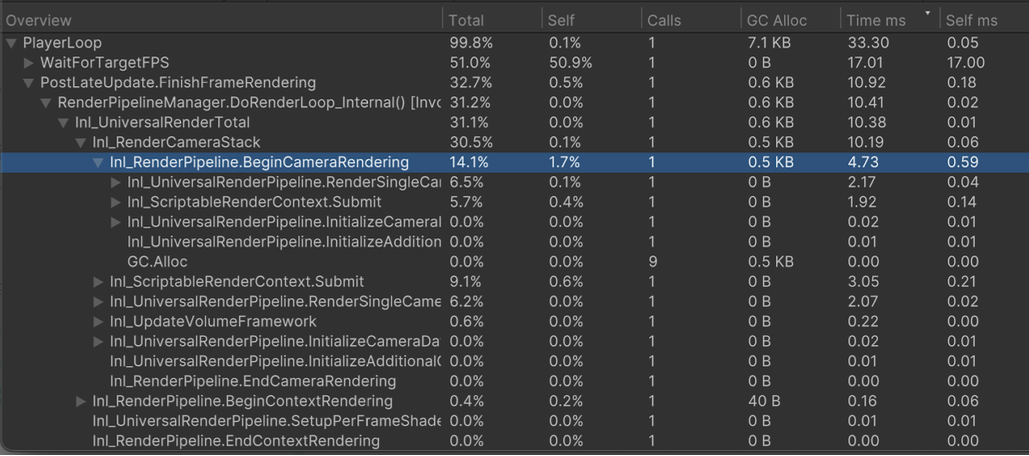
- 가장 실행시간이 긴 샘플들 부터 해결하면 된다.
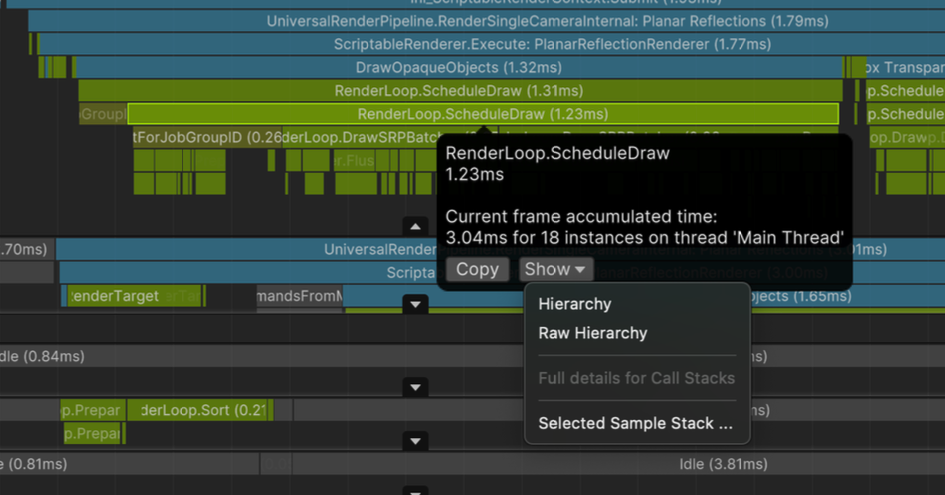
프로파일러 - 스레드들
- 메인 스레드
- 유니티 Player Loop (Awake, Start..) 가 일어남
- MonoBehaviour 스크립트들이 일차적으로 동작한다
- 렌더 스레드
- GPU에게 전달할 명령어를 조립하는 스레드 실질적인 GPU에게 전달할 그래픽스 명령어를 조립하고 메인 스레드에서 드로우콜이 발생 -> 렌더 스레드에서 실행
- 워커 스레드 (잡 스레드)
- 잡 시스템 등으로 비동기 병렬 실행한 처리들
- 애니메이션 / 물리 등 연산 집약 처리들이 이곳에서 실행 메인 스레드에서 잡을 예약 -> 워커 스레드에서 처리
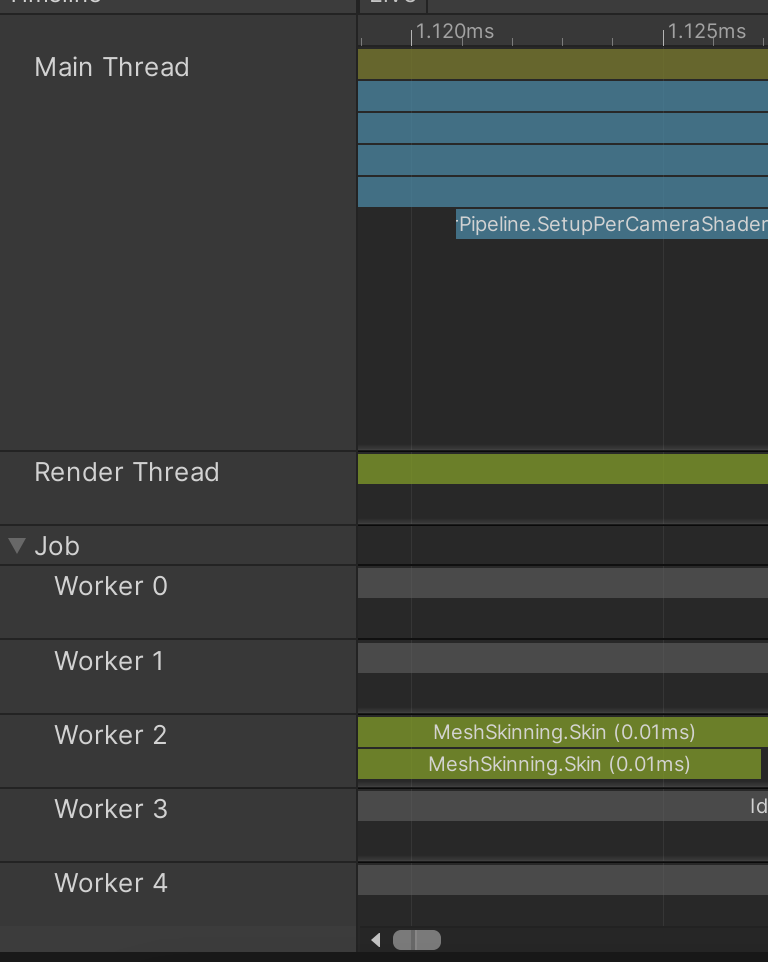
- 서로 다른 스레드에서, 서로 직접 호출하지 않는 메소드 실행 사이에 인과관계가 있을 수 있다.
ex1. 잡 예약 > 워커 스레드에서 처리
ex2. 메인 스레드의 메시 렌더러가 Draw() 실행 > 렌더 스레드에서 그래픽스 명령어 조합
메인스레드의 처리들이 지연되면 렌더 스레드가 놀 수 있다.
- Show Flow Events 설정 활성화 : 실행 순서, 인과 관계 확인 가능.
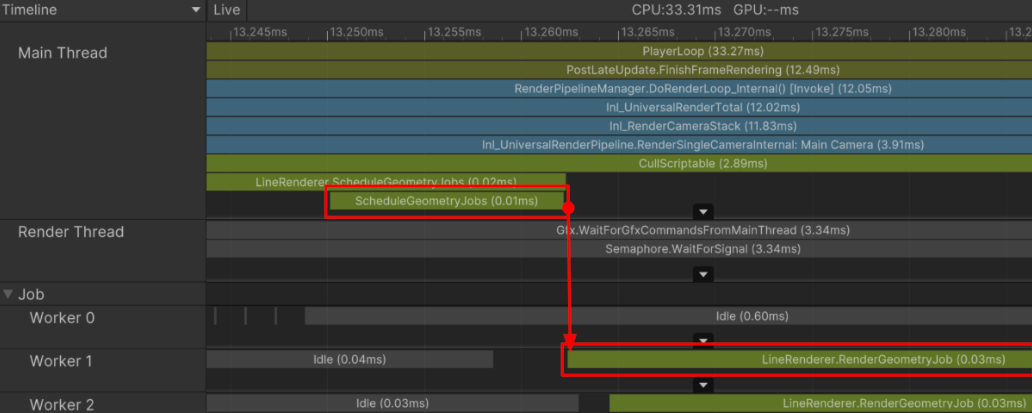
샘플 스택과 콜 스택 차이

- 샘플 스택과 콜 스택의 차이가 존재한다. 샘플 스택은 청크 단위로 정리되고 마크된 C# 메서드, 코드 블록만 실행한다.
- 이 이유 때문에 크게 하나로 묶여서 샘플링이 처리가 된다. -> 모든 C# 메서드 호출을 샘플링 하지 않음. 마크된 C# 메서드와 코드 블록만 샘플링.(유니티에서 미리 주요 실행들에 대해 마크해 둠.)
딥 프로파일링 시 주의 사항
딥 프로파일링 시 -> 모든 C# 호출 (생성자, 프로퍼티 포함) 마크
프로파일링 그 자체의 과도한 오버헤드가 발생 -> 부정확한 데이터
- 따라서 딥 프로파일링 시 아주 제한적인 스코프 내에서 한정된 시간내에서만 사용하는 것을 권장한다.
콜 스택 설정 하는 방법
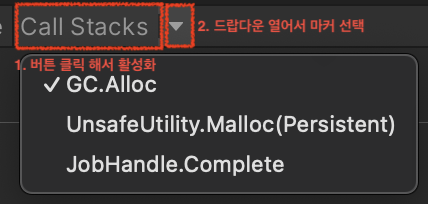
- 콜 스택 버튼을 눌러서 활성화 시켜야함!! (음영 생김)
- 콜 스택 드롭다운 -> 원하는 마커 선택하여 클릭

- 특정 샘플에 대해서는 콜스택 전체를 기록 할 수 있다.
- GC.Alloc : 동적 할당이 일어나는 경우
- UnsafeUtility.Malloc : 관리되지 않는 할당 - 메모리를 직접 해제해야하는 할당을 했을 때
- Jobhandle.Complete : 잡 동기 완료, 메인 스레드에서 잡 스레드를 강제로 동기완료 했을 때
- 권장하지 않고 제한적으로 사용 가능.
마커에 대해 알아보자
1. 메인 루프 마커
PlayerLoop : 플레이어 루프에 맞춰 실행되는 샘플들의 루트
BeahvourUpdate : Update() 샘플들의 홀더
FixedBehaviourUpdate : FixedUpdate() 샘플들의 홀더
EditorLoop : 에디터 전용, 에디터 루프
2. 그래픽스 마커 (메인 스레드)
- WaitForTargetFPS
Vsync, 목표 프레임 레이트를 기다리는 시간
- Gfx.WaitForPresentOnGfxThread
렌더 스레드가 GPU를 기다리고 있어서 생기는 마커 렌더 스레드가 바빠서 메인 스레드도 같이 대기해야하는 경우
- Gfx.PresnetFrame
GPU가 현재 프레임을 렌더하는 시간을 기다림
이것이 길면 GPU 처리가 늦어짐 - GPU.WaitForCommands
렌더 스래드는 새로운 커맨드 받을 준비 완료. 메인 스레드에서 렌더 스레드에게 못 넘겨주고 있는 상황 메인 스레드가 대기중
병목 지점 찾기
- 그래픽스 마커는 GPU / CPU 바운드 판단에 유용하다.
- 메인 스레드에서 렌더 스레드를 기다리는 중일 때 -> 메인 스레드에서 병목현상이 발생하고 LateUpdate 단에서 렌더 스레드에서 명령어를 생성
- 즉 gpu cpu 병목을 파악하는게 아닌 스레드간의 병목을 파악해야한다.
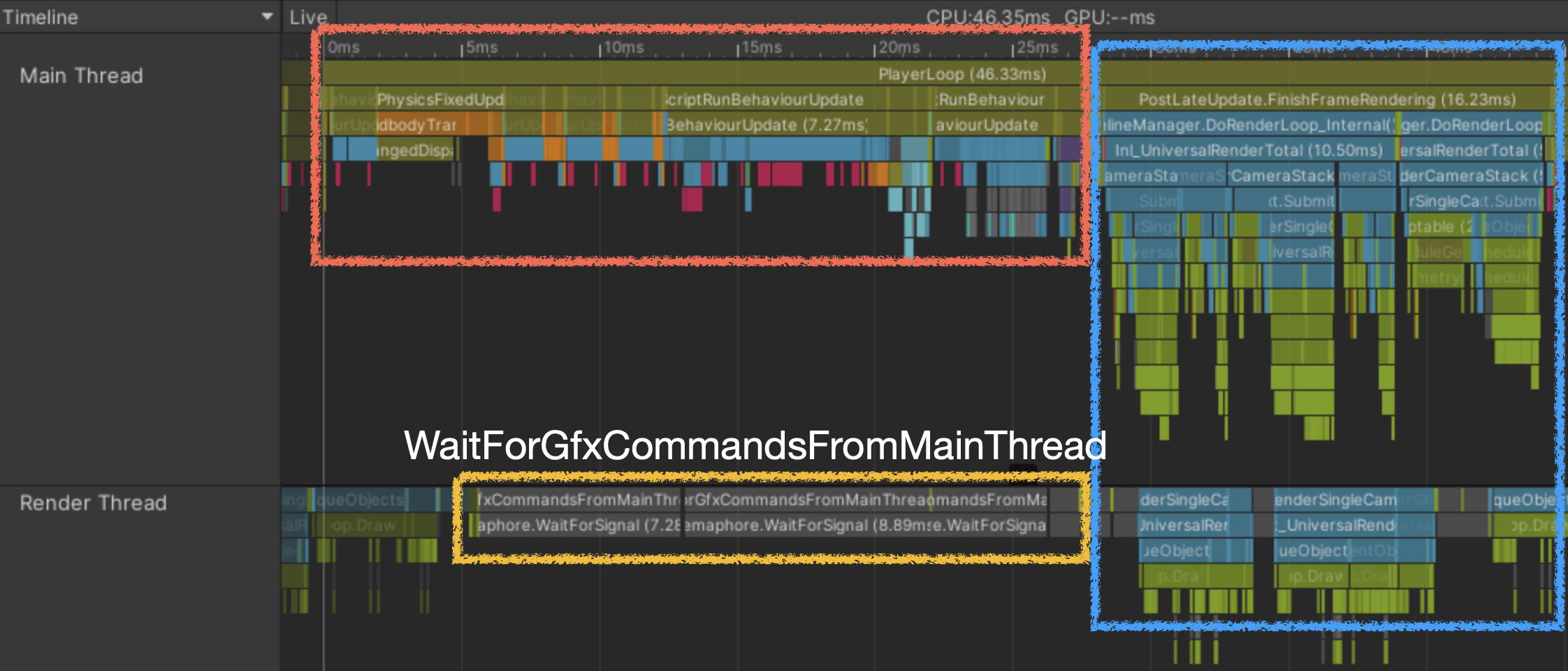
- CPU 메인스레드 바운드
메인스레드 처리가 늦어서 렏더 스레드를 대기
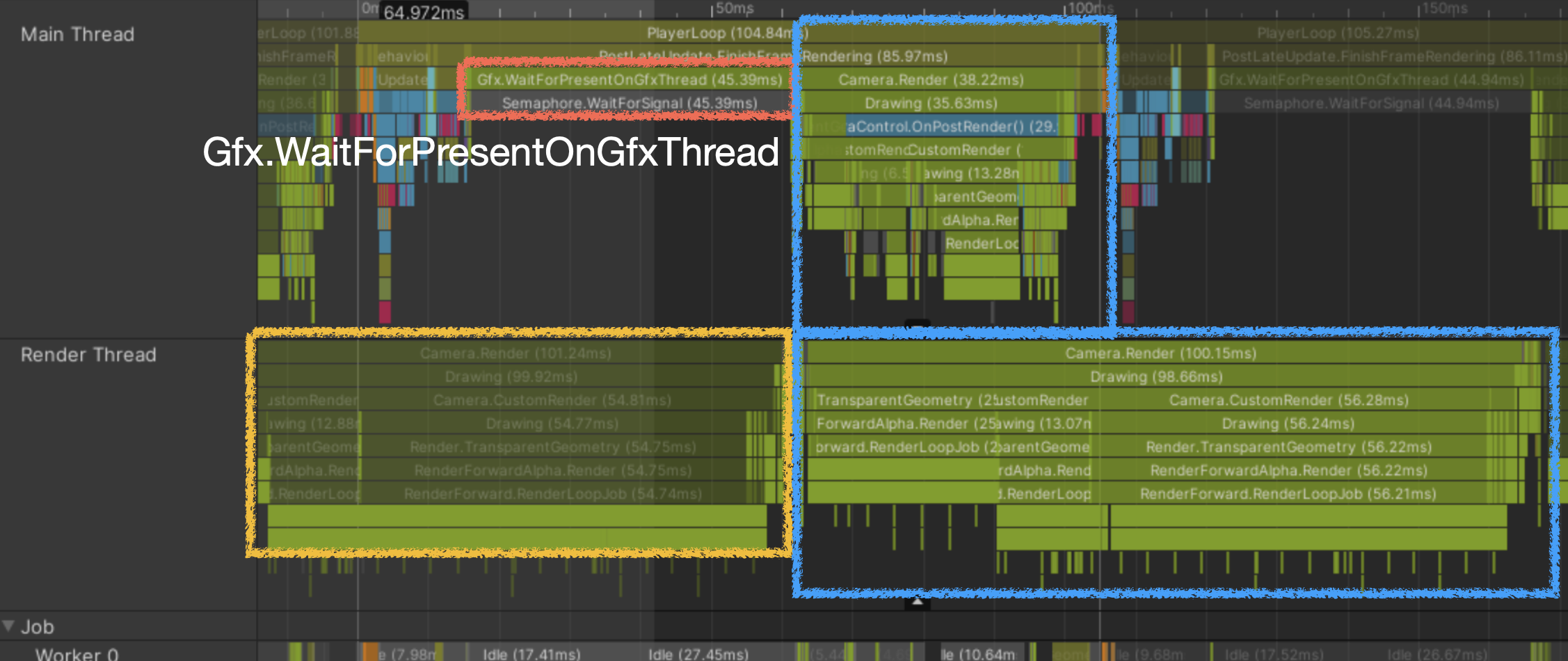
- 렌더스레드 바운드
직전 프레임을 그리기 위한 드로우콜 명령어를 아직도 보내는 중
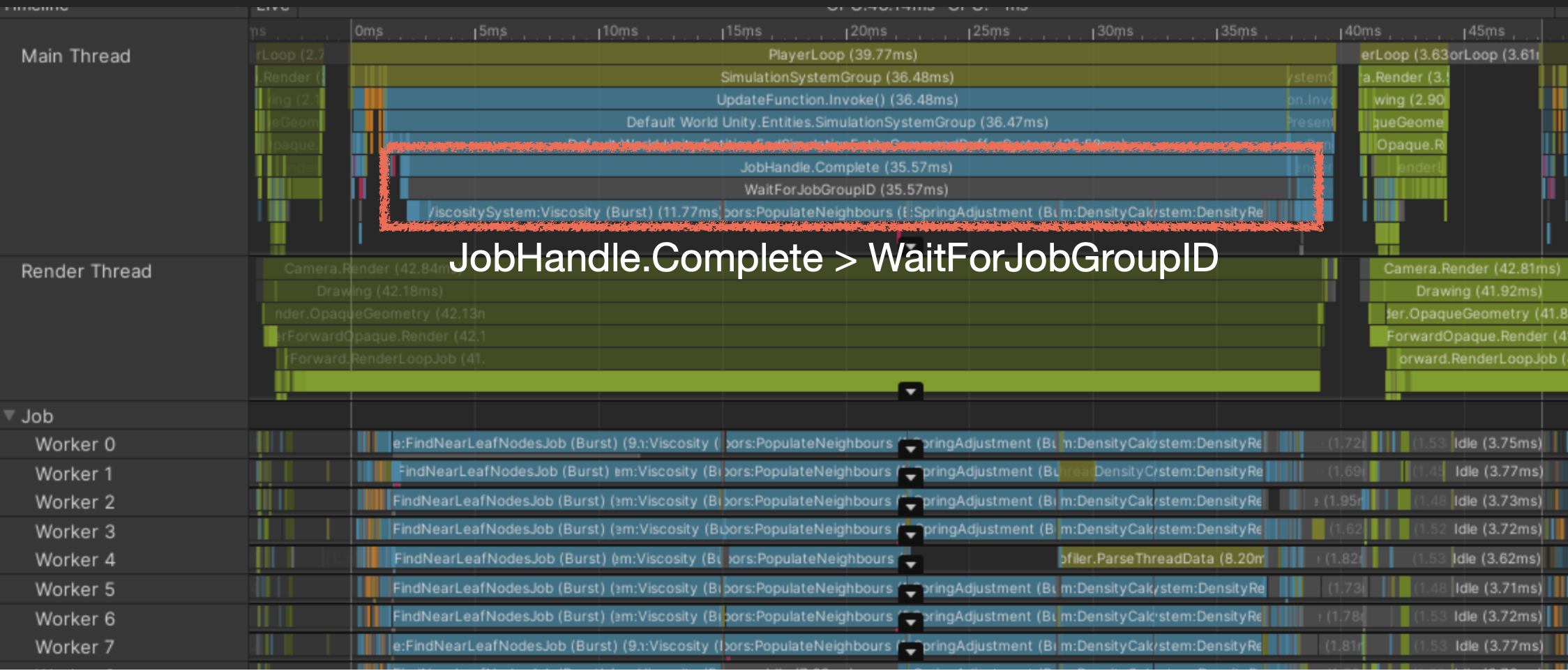
- 워커스레드 바운드
잡 완료를 동기로 대기중
- Xcode Frame Debugger, 2023 프로파일러는 GPU CPU바운드 표기 해줌
병목에는 크게 4가지 병목이 존재한다.
- CPU 메인 스레드 바운드
- CPU 워커 스레드 바운드 (물리, 애니메이션, 잡 시스템)
- CPU 렌더 스레드 바운드 (그래픽카드의 병목이 아닌 CPU에서 그래픽카드로 작업 즉 명령어 조립 넘기는것에 대한 병목)
- GPU 바운드
- 병목을 찾는 흐름
메인 스레드 병목 ? 플레이어 루프 최적화
아닐경우 물리, 애니메이션, 잡 시스템 집중
이거도 아니면 렌더 스레드 병목 GPuU 인지 CPU인지 또 파악
- 렌더 스레드 CPU 병목인 경우
- CPU그래픽스 최적화
카메라, 컬링 최적화
Setpass call 줄이기 (batching) 가능한 그래픽스 배칭 - SRP 배칭, Dynamic 배칭, Static 배칭, GPU 인스턴싱
범용적인 사실
- 배칭에 대해 설명하기 전 짚고 넘어가기.
- 그래픽스 처리 지연들
요즘 그래픽카드가 좋아졌기 때문에 GPU성능에 문제가 있다라기 보단, CPU가 명령어를 구성하는데에서 지연 -> GPU성능을 제대로 활용을 못하고 있다.
CPU->GPU로 명령어, 리소스를 업로드하는 데에서의 지연
GPU 내에서의 처리 지연이 있을 수 있다. - 드로우콜 CPU -> GPU에게 렌더 실행 명령을 내림
드로우콜 보단 렌더 상태 변경에서 발생하는 CPU 성능 소모/업로드 지연이 크다.
- 그리라는 명령 보단 그리라는 명령하기 직전
- GPU는 다수의 작은 메시보다 대량의 정점을 가직 메시를 빠르게 그린다.
- GPU의 계산 성능이 떨어지는 것보단 GPU를 효율적으로 사용하지 못해서 발생
GPU는 다수의 작은 메시보다 한번에 대량의 정점을 가진 메시를 더 빠르게 그린다
대부분의 랜더링 문제는 GPU의 계산 성능이 떨어지는 것 보다
GPU를 효율적으로 못쓰는데서 많이 발생한다
정점수가 작은 메시를 전달 > GPU의 처리 단위(Wavefront/Warp)를 낭비
예시로는 256개의 버텍스를 한 프레임당 처리하는데, 128개 버텍스를 요청하면 낭비가 발생
그래픽스 배칭
1. SRP 배칭 (URP, HDRP)
- 드로우 명령어보다, 이에 앞서 매번 서로 다른 렌더 스테이트(서로 다른 쉐이더)를 셋업하는게 비용이 더 크다
- 동일한 셰이더 & 머티리얼을 사용하는 메시들을 모으기
- 하나의 SetPass Call(동일한 셰이더 베리언트) 아래에 다수의 드로우콜을 묶음
- 머티리얼별 데이터 : 거대한 리스트에 넣어 초기에 업로드
- 오브젝트별 데이터 : 거대한 리스트에 넣어 매프레임 업로드
- 인덱스/오프셋을 통해 리스트로부터 메시를 지정하고 Draw()
- 프로젝트에서 사용하는 셰이더 수를 줄이면 최적화가 가능하다.
2. 정적 배칭 (Static)
- GPU는 한번에 큰 메시를 그리는 것을 좋아한다. 적은 데이터 전송 이라는 컨셉
- 움직이지 않는 메시들을 미리 합쳐서 베이크함 -> GPU 에게 미리 업로드 -> 각 렌더러에서 DrawIndexed()호출
- 매우 빠른 CPU/GPU 처리 속도
- 유니티 에디터가 앱을 빌드할 때 만 베이크
- 단점, 기존 메시들을 합쳐 새로운 유니크한 메시가 만들어지므로 메모리 사용량 증가
3. 다이나믹 배칭 (Dynamic)
- GPU는 한번에 큰 메시를 그리는 것을 좋아한다. 적은 데이터 전송 이라는 컨셉 -> 별로 권장하지 않음.
- 매 프레임 메시들을 합침 > Draw() 한번 실행
- GPU측에서는 최적화
GPU 측이 받는 것은 한개의 메시/드로우 명령이므로 매우 빠른 처리
- CPU에서는 매프레임 메시를 합쳐줘야한다.
드로우 명령어는 적게 사용하지만, 메시를 합치는 과정에서 성능 소모
- 매 프레임 베이크 > 드로우콜이 많은 것보다, 메시를 합치는 것이 더 성능 소모가 심할 수 있음
4. GPU 인스턴싱
- CPU에서 GPU로 명령 전달을 아끼자.
- 동일한 메시에 완전히 동일한 셰이더와 머티리얼을 쓰는 경우
- 메시 데이터를 GPU에 한번만 업로드
인스턴스별 유니크한 데이터(오브젝트 to 월드 행렬)는 배열로 전달
- 동일 객체를 다수 그릴때 매우 빠른 CPU 속도
- •(500개 미만)정점 수가 너무 작은 메시는 효율이 떨어진다
GPU는 거대한 메시를 그리는 것이 성능이 더 좋다. 버텍스가 256 이하인 메시는 효율이 떨어진다.
정리
- 일반적인 효율 : SRP 배칭, 정적 배칭 > GPU 인스턴싱 > 다이나믹 배칭
- 드로우콜보다 드로우콜 직전의 렌더 상태 셋업이 더 큰 CPU 비용 발생
- 드로우콜보단 SetPass 콜을 줄이는데 집중하는게 좋다 (SRP배칭) -> 물론 드로우콜 최적화도 중요하다.
- 드로우콜 줄이기(GPU 인스턴싱, 다이나믹 배칭)에 앞서 우선 SRP 배치를 켜고 셰이더 종류 줄이기가 가장 효과적
SRP 배칭 켜고 셰이더 종류를 줄이는게 가장 효과적이다. 셰이더 종류를 줄여야한다..
SetPass call 을 줄이자!!
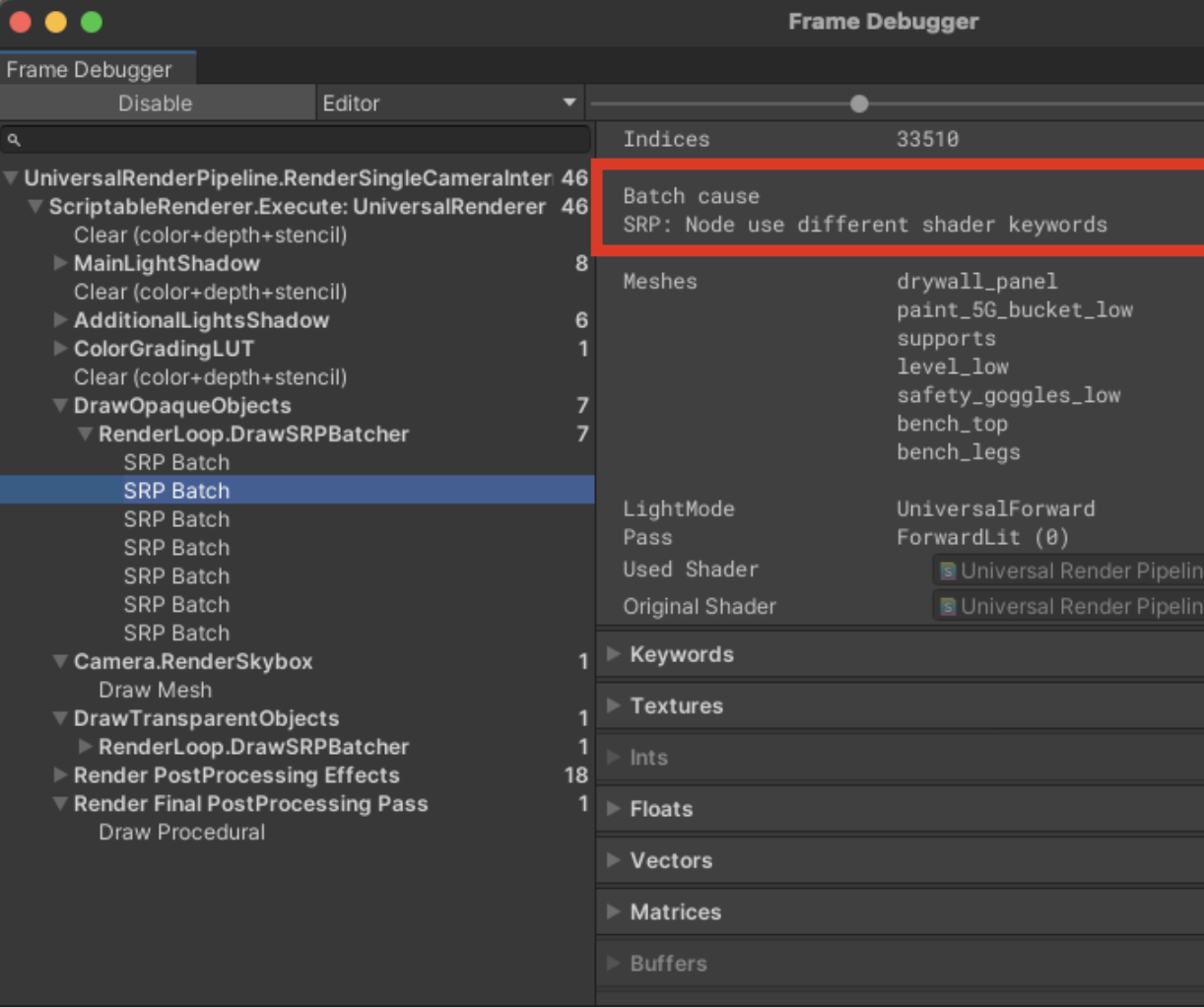
- Frame Debugger로 Setpass call 합쳐지지 않는 이유를 볼 수가 있다.
- SetPass Call 을 300 미만으로 목표 설정.
GPU 렌더 병목인 경우
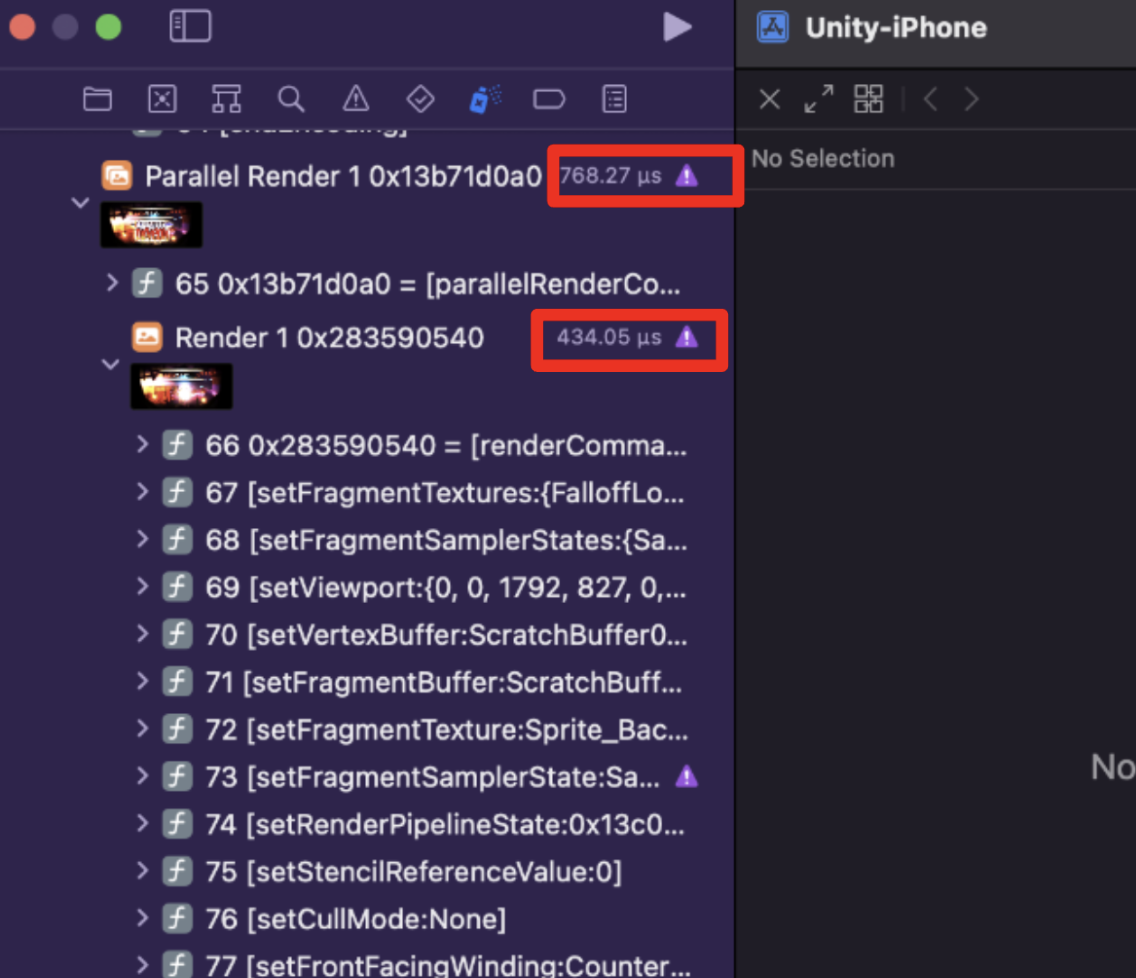
- Xcode GPU 프레임 캡쳐
- 명령어들이 쭉 나열되어있다. 각각의 렌더 단계에서 시간 소모를 확인하자.
- 비정상적으로 시간 소모하는 드로우를 찾을 수 있다 -> 해당 드로우 명령어가 사용하는 셰이더, 메시를 찾아서 최적화 진행.
- Reference
이제민(Retro 유니티 파트너십 엔지니어) 님의 강의에서 얻은 자료입니다.
이제민님 깃허브