
Machine Learning - Supervised & Unsupervised Machine Learning

Machine Learning - Supervised & Unsupervised Machine Learning
Supervised Machine Learning 시리즈 (2 / 7)
- AI(ML/DL) 조사 보고서
- Machine Learning - Supervised & Unsupervised Machine Learning
- Machine Learning - Linear Regression
- Machine Learning - Cost Function
- Machine Learning - Gradient Descent
- Machine Learning - Multiple Linear Regression
- Machine Learning - Feature Scaling & Learning Rate

해당 포스트는 Andrew Ng 교수님의 Machine Learning Specialization 특화 과정에 대한 정리 내용을 참고하였습니다.
목차
Supervised Learning - 지도 학습
- 지도학습은 x -> y 형태의 입력과 출력의 mapping 을 학습하는 알고리즘을 뜻한다.
- 주어진 입력 x에 대해 올바른 레이블 y를 정답으로 지정하고 입력 x와 원하는 출력 레이블 y의 올바른 쌍을 보면 학습 알고리즘이 결국 출력 레이블 없이 입력값만 취하도록 학습하여 출력값을 합리적으로 정확하게 예측하거나 추측할 수 있다.
- supervised learning 은 크게 두 가지 주요 유형으로 나뉜다. Regression 회귀, Classificiation 분류.
Supervised Learning - 1. Regression 회귀
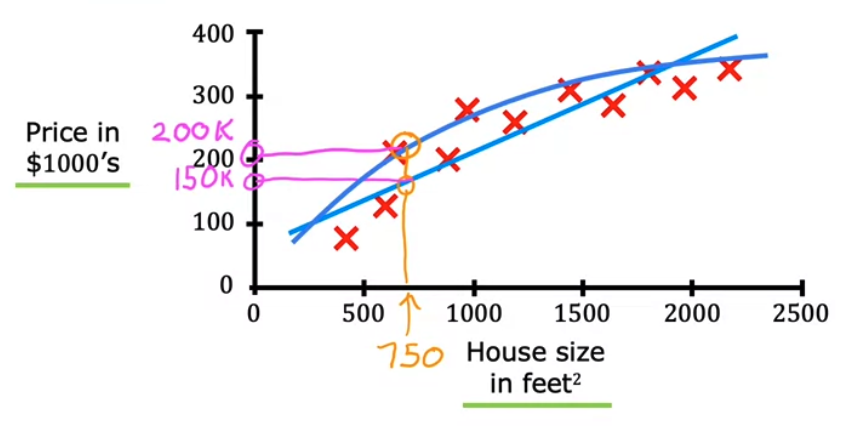
- 구체적인 예시를 들면, 주택 크기를 기준으로 주택 가격을 예측한다고 가정해보자, 몇 가지 데이터를 수집한 다음 데이터를 도표화 하면 위와 같다.
가로축은 집의 크기(평방 피트), 세로 축은 주택 가격 (달러) 라고 했을 때, 친구의 집인 750 평방 피트의 주택가격이 얼마인지 알고 싶어한다고 가정해보자.
- 데이터에 가장 적합한 선이나 곡선 또는 다른 것을 체계적으로 선택하는 알고리즘을 얻어 예측할 수 있을 것이다.
만약 선형적인 피팅값으로 예측을하면 750 평방피트에 대응하는 가격은 150k 달러 일 것이고, 곡선에 피팅을 했다면 200k 달러가 될 것이다.
- 이처럼 주택 가격을 예측하는 것을 Regression (회귀)라고 하며 이는 특정한 유형의 supervised learning 이다.
- 또한 Regression Anlaysis (회귀분석)이란 가능한 무한한 숫자로 특정 숫자를 예측하려는 것이다.
Supervised Learning - 2. Classification 분류

- 유방암을 진단하는 머신 러닝 시스템이 있다고 하자, 환자의 의료 기록들을 사용하여 종양이 malignant(악성)인지 benign(양성)인지 알아 내려고 한다.
- input을 diameter(직경)으로 두고 output label 이 benign, malignant type1, type2 가 있다. classification 알고리즘은 category(or class)즉 범주를 예측한다.
- 또한 Regression 과의 차이점은 Classification 에서는 possible outputs 가능한 결과의 수가 매우 작다.
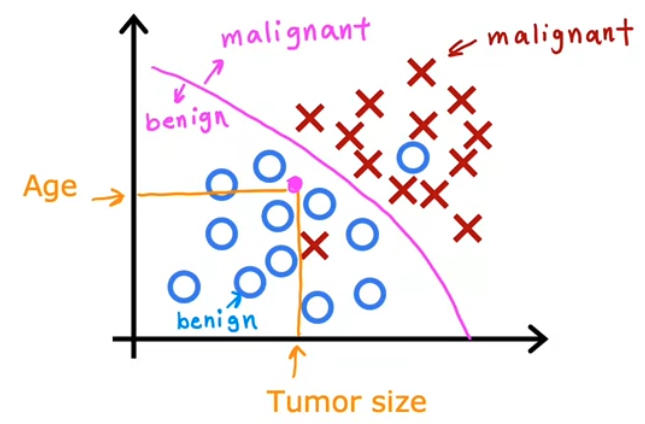
- 만약 input 이 위 처럼 diameter, age 두 개일 경우 (2차원) 종양이 악성인지 양성인지 어떻게 예측할 수 있을까?
- 악성 종양과 양성 종양을 구분할 수 있는 경계를 찾는 방법이 있다. 즉, 데이터를 통해 경계선을 맞추는 방법을 결정해야한다.
Unsupervised Learning - 비지도 학습
- supervised learning 다음으로 가장 널리 사용되는 머신 러닝 형태는 unsupervised learning 이다.
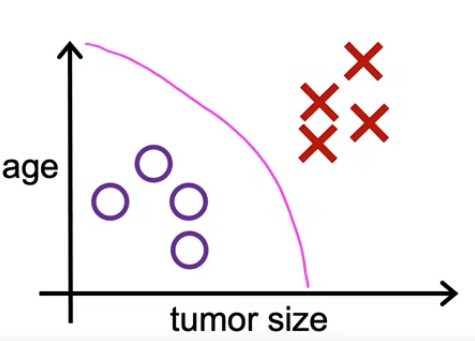
- 좌측 사진을 보면 종양이 양성인지 악성인지에 대한 정확한 output label 인 y 가 존재하지만, 우측 사진을 보면 label 이 없는 종양들만 있을 뿐이다.
- 이처럼 알 수없는 데이터 집합들에서 구조나 어떤 패턴을 찾거나 흥미로운 점을 찾는 것이 Unsupervised Learning 이다.
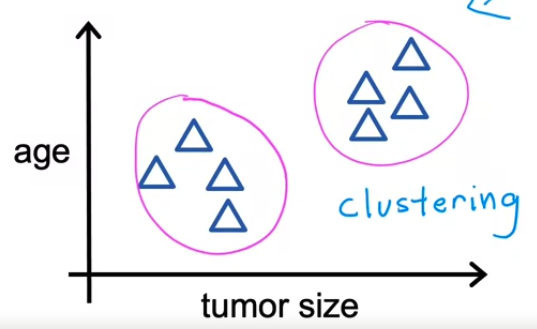
Unsupervised Learning - Clustering Algorithm
- unsupervised learning algorithm 은 위 사진 처럼 데이터를 서로 다른 두 그룹 또는 두 군집에 할당할 수 있다고 결정한다.
- 즉 요약하자면 label 이 없는 데이터를 가져와서 자동으로 Cluster로 나누어 그룹화 한다.
Unsupervised Learning - Anomaly Detection 예외 항목 탐지
- 특이한 사건이나 비정상적인 거래가 사기의 징후인지 탐지하거나 예측하는 시스템을 금융 시스템이나 기타 어플리케이션에서 매우 중요한 역할을 하기도 한다.
Unsupervised Learning - Dimensionality Reduction 차원 축소
- 큰 데이터 집합을 가져와서 최대한 정보 손실을 줄이고 더 작은 데이터 집합으로 압축하는 방법이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.