
CS 로드맵 (3) — 해시 테이블: O(1) 조회의 조건과 한계

- 해시 테이블은 키를 정수로 변환(해시 함수)한 뒤 배열 인덱스로 매핑하여 O(1) 조회를 달성하며, 해시 함수의 품질이 전체 성능을 결정한다
- 충돌 해결의 두 전략 — 체이닝은 구현이 단순하지만 포인터 추적으로 캐시 미스가 발생하고, 오픈 어드레싱(특히 Linear Probing)은 연속 메모리 접근으로 캐시 친화적이다
- Linear Probing 기준 로드 팩터(α)가 0.7을 넘으면 충돌 확률이 급증하여 성능이 O(1)에서 O(n)으로 퇴화하며, 충돌 해결 전략에 따라 허용 가능한 로드 팩터가 다르다
- Robin Hood Hashing은 '부자에게서 빼앗아 가난한 자에게 주는' 전략으로 탐색 거리의 분산을 줄여, Rust HashMap과 현대 고성능 해시 테이블의 기반이 되었다

서론
이 문서는 CS 로드맵 시리즈의 3번째 편입니다.
“이 키로 값을 찾아라.”
프로그래밍에서 가장 빈번한 질문이다. 몬스터 ID로 스탯을 조회하고, 문자열 키로 설정값을 가져오고, 좌표로 타일 데이터를 찾는다. 이 질문에 O(1)로 답하는 자료구조가 해시 테이블(Hash Table)이다.
1편에서 배열이 인덱스로 O(1) 접근을 제공하는 것을 보았다. 해시 테이블의 핵심 아이디어는 단순하다: 임의의 키를 배열 인덱스로 변환하면, 배열의 O(1) 접근을 그대로 활용할 수 있다. 이 변환을 수행하는 것이 해시 함수(Hash Function)다.
단순한 아이디어지만, 악마는 디테일에 있다. 서로 다른 키가 같은 인덱스로 변환되면(충돌) 어떻게 하는가? 해시 함수는 어떻게 설계하는가? 배열이 꽉 차면? 이 질문들에 대한 답이 해시 테이블의 본질이다.
C# Dictionary, Java HashMap 등 언어별 구체적 구현은 별도 포스트(C# 자료구조 - Dictionary와 SortedList)에서 다루고 있다. 이 글은 언어에 무관한 해시 테이블의 근본 원리에 집중한다.
이후 시리즈 구성:
| 편 | 주제 | 핵심 질문 |
|---|---|---|
| 3편 (이번 글) | 해시 테이블 | O(1)은 어떻게 가능하며, 그 대가는 무엇인가? |
| 4편 | 트리 | BST, Red-Black Tree, B-Tree는 왜 필요한가? |
| 5편 | 그래프 | 탐색, 최단 경로, 위상 정렬의 원리는? |
| 6편 | 메모리 관리 | 스택/힙, GC, 수동 메모리 관리의 트레이드오프는? |
Part 1: 해시 함수 — 키를 숫자로 바꾸는 기술
해시 테이블의 기본 구조
해시 테이블은 세 가지 요소로 구성된다:
- 배열(버킷 배열): 데이터를 저장하는 고정 크기 배열
- 해시 함수: 키 → 정수로 변환
- 충돌 해결 전략: 두 키가 같은 인덱스를 가리킬 때의 처리
1
2
3
4
5
6
Key "MOB_001" → hash("MOB_001") = 374821 → 374821 % 8 = 5 → bucket[5]
┌───────┬───────┬───────┬───────┬───────┬─────────────┬───────┬───────┐
│ [0] │ [1] │ [2] │ [3] │ [4] │ [5] │ [6] │ [7] │
│ empty │ empty │ empty │ empty │ empty │ MOB_001:고블린│ empty │ empty │
└───────┴───────┴───────┴───────┴───────┴─────────────┴───────┴───────┘
조회할 때도 동일한 경로: 키 → 해시 함수 → 인덱스 → 배열 접근. 배열 접근이 O(1)이므로, 해시 함수가 O(1)이면 전체가 O(1)이다.
단, 엄밀하게 말하면 해시 테이블의 O(1)은 해시 계산 비용과 키 비교(equality) 비용이 상수라는 가정 위에 있다. 정수 키라면 이 가정이 성립하지만, 문자열 키는 해시 계산이 O(L), 비교도 O(L)이므로 실질적으로는 O(L)이다. 이 점은 뒤에서 더 자세히 다룬다.
해시와 동등성의 계약(Hash-Equality Contract)
해시 테이블이 올바르게 동작하려면 해시 함수와 동등성 비교 사이에 반드시 지켜야 할 계약이 있다:
a == b이면 반드시hash(a) == hash(b)여야 한다.
역은 성립하지 않아도 된다 — hash(a) == hash(b)이지만 a != b인 경우가 충돌이다. 하지만 정방향 규칙을 어기면 해시 테이블이 깨진다. 같은 키를 넣었는데 다른 버킷에 저장되므로, 조회 시 찾을 수 없다.
실전에서 자주 발생하는 실수:
1
2
3
4
5
6
// 위험: 가변 객체를 키로 사용
var enemy = new Enemy { Id = 1, Hp = 100 };
dict[enemy] = "goblin";
enemy.Hp = 50; // 키 객체의 상태가 변경됨!
dict[enemy]; // KeyNotFoundException! 해시 값이 달라져서 다른 버킷을 탐색
따라서 해시 테이블의 키는 불변(immutable)이어야 한다. C#에서 GetHashCode()를 오버라이드하면 반드시 Equals()도 함께 오버라이드해야 하고, Java에서 hashCode()를 오버라이드하면 equals()도 함께 오버라이드해야 한다. Bloch의 Effective Java Item 11이 이 원칙을 상세히 설명한다.
게임 개발에서의 교훈: 몬스터 ID, 아이템 ID 같은 불변 식별자를 키로 쓰는 것이 안전하다. 게임 오브젝트 자체를 키로 쓰면 상태 변경 시 해시 테이블이 깨질 수 있다.
좋은 해시 함수의 조건
Knuth는 The Art of Computer Programming Vol. 3에서 해시 함수의 핵심 조건을 이렇게 정리했다:
- 결정적(Deterministic): 같은 키는 항상 같은 해시 값을 반환해야 한다
- 균일 분포(Uniform Distribution): 해시 값이 가능한 범위에 고르게 퍼져야 한다
- 효율적 계산: 해시 함수 자체가 빨라야 한다 — O(1) 또는 키 길이에 비례
2번이 핵심이다. 해시 값이 한쪽으로 몰리면 충돌이 집중되고, 성능이 O(n)으로 퇴화한다.
정수 키의 해시: 나눗셈법과 곱셈법
나눗셈법(Division Method):
\[h(k) = k \mod m\]가장 직관적이다. 키 k를 테이블 크기 m으로 나눈 나머지. 단, m의 선택이 중요하다:
- m이 2의 거듭제곱이면 위험하다. $k \mod 2^p$는 k의 하위 p비트만 사용한다. 키의 상위 비트 정보가 모두 버려진다.
- m이 소수(prime)면 좋다. 키의 비트 패턴에 관계없이 고른 분포를 얻는다. .NET
Dictionary가 소수 크기를 사용하는 이유다.
곱셈법(Multiplication Method):
\[h(k) = \lfloor m \cdot (k \cdot A \mod 1) \rfloor, \quad 0 < A < 1\]Knuth가 제안한 A 값은 황금비의 역수 $A = \frac{\sqrt{5} - 1}{2} \approx 0.6180339887$이다. 이 값은 1차원 균일 분포에서 이론적으로 가장 “고르게 퍼지는” 상수다.
곱셈법의 장점은 m을 자유롭게 선택할 수 있다는 것이다. 특히 m을 2의 거듭제곱으로 선택하면 모듈러 연산을 비트마스크(AND)로 대체할 수 있어 빠르다. 예를 들어 hash % 16은 hash & 0xF와 동일하다 — 2편에서 링 버퍼의 & (capacity - 1) 트릭과 같은 원리다.
잠깐, 이건 짚고 넘어가자
Q. 왜 2의 거듭제곱 모듈러가 위험한가, 구체적으로?
게임 오브젝트의 ID가 8의 배수(메모리 정렬 때문에 흔하다)라고 하자. $k = 8, 16, 24, 32, …$일 때 $k \mod 16$은 항상 0 또는 8이다. 16개 버킷 중 2개에만 모든 데이터가 몰린다. 소수 m=17이면 $8 \mod 17 = 8$, $16 \mod 17 = 16$, $24 \mod 17 = 7$, $32 \mod 17 = 15$ — 고르게 퍼진다.
단, Java
HashMap처럼 해시 값 자체를 추가 교란(perturbation)하면 2의 거듭제곱 테이블도 안전하게 사용할 수 있다. Java는 해시 값의 상위 16비트를 하위 16비트에 XOR하여 섞는다.
문자열 키의 해시
문자열은 가변 길이이므로 각 문자를 누적하여 해시를 만든다. 가장 널리 쓰이는 방식:
다항식 해시(Polynomial Rolling Hash):
\[h(s) = s[0] \cdot p^{n-1} + s[1] \cdot p^{n-2} + \cdots + s[n-1] \cdot p^0\]여기서 p는 소수(보통 31 또는 37). Java의 String.hashCode()가 이 방식이다:
1
2
3
4
5
// Java String.hashCode() — 약간 변형된 다항식 해시
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash = 31 * hash + str.charAt(i);
}
왜 31인가? $31 = 2^5 - 1$이므로 31 * x를 (x << 5) - x로 컴파일러가 최적화할 수 있다. Bloch의 Effective Java에서 이를 권장한 이후로 사실상 표준이 되었다.
더 현대적인 해시 함수들:
| 해시 함수 | 속도 | 품질 | 사용처 |
|---|---|---|---|
| FNV-1a | 빠름 | 보통 | 일반 용도, 간단한 구현 |
| MurmurHash3 | 매우 빠름 | 좋음 | 일반 해시 테이블, Cassandra, Elasticsearch |
| xxHash | 극한 빠름 | 좋음 | 체크섬, 데이터 처리 |
| SipHash | 보통 | 좋음 + DoS 방어 | Rust HashMap, Python dict, Redis, Ruby |
| wyhash | 극한 빠름 | 좋음 | Go map (1.17~1.23) |
게임 개발에서 문자열 키가 자주 쓰이는 곳: 리소스 경로, 애니메이션 이름, 이벤트 이름. 문자열 해시 계산은 문자열 길이에 비례(O(L))하므로, 매 프레임 호출되는 곳에서는 해시를 캐시하거나 문자열 인터닝(string interning)을 고려해야 한다.
Part 2: 충돌 해결 — 체이닝
비둘기집 원리
해시 함수가 아무리 좋아도, 충돌은 필연이다.
비둘기집 원리(Pigeonhole Principle): n개의 비둘기를 m개의 집에 넣을 때, $n > m$이면 최소 한 집에 두 마리 이상이 들어간다.
키의 가능한 값은 사실상 무한(문자열만 해도)한데, 배열의 크기 m은 유한하다. 따라서 서로 다른 키가 같은 인덱스에 매핑되는 충돌은 피할 수 없다.
Birthday Paradox(생일 문제)는 이 상황을 더 극적으로 보여준다. 365개 버킷에 23개 키만 넣어도 충돌 확률이 50%를 초과한다. 일반적으로 m개 버킷에 $\sqrt{m}$개 키를 넣으면 충돌이 발생할 확률이 약 50%다.
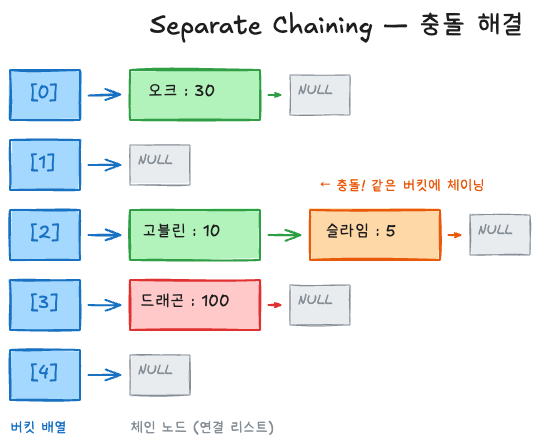
체이닝(Separate Chaining)
가장 직관적인 충돌 해결 방법. 같은 인덱스에 매핑된 원소들을 연결 리스트(또는 다른 자료구조)로 연결한다.
1
2
3
4
5
6
buckets:
[0] → (K="오크", V=30) → NULL
[1] → NULL
[2] → (K="고블린", V=10) → (K="슬라임", V=5) → NULL
[3] → (K="드래곤", V=100) → NULL
[4] → NULL
버킷 2에서 “슬라임”을 찾으려면: 버킷 2의 리스트를 순회하면서 키를 비교한다.
시간 복잡도:
- 평균: O(1 + α), 여기서 α = n/m (로드 팩터)
- 최악: O(n) — 모든 키가 한 버킷에 몰리면
장점:
- 구현이 단순하다
- 로드 팩터가 1을 초과해도 동작한다
- 삭제가 간단하다 (연결 리스트에서 노드 제거)
단점 — 캐시 성능:
1편에서 배운 교훈을 여기에 적용하자. 체이닝의 각 노드는 별도 힙 할당이다. 노드들이 메모리에 흩어져 있으므로, 체인을 따라갈 때마다 캐시 미스가 발생할 가능성이 높다.
1
2
3
4
5
6
메모리 공간:
0x1000: [bucket 배열]
...
0x3040: [Node: 고블린] ← 캐시 미스
...
0x7820: [Node: 슬라임] ← 또 캐시 미스
이것이 “O(1)인데 왜 느린가?”의 답이다. Big-O의 상수에 캐시 미스 비용이 숨어 있다.
체이닝의 개선: 배열 내 체이닝
.NET Dictionary는 이 문제를 영리하게 해결한다. 별도 노드 대신 entries 배열 내부에서 next 인덱스로 체이닝한다:
1
2
3
4
5
6
7
8
9
10
entries[] (연속 배열):
[0] hash=9284 next=-1 Key="고블린" Val=10
[1] hash=3507 next=-1 Key="슬라임" Val=5
[2] hash=3500 next=1 Key="오크" Val=30 ← next=1로 [1]을 가리킴
[3] hash=7423 next=-1 Key="드래곤" Val=100
buckets[]:
[0] → 0 // entries[0]
[2] → 2 // entries[2] → entries[2].next=1 → entries[1]
[3] → 3
모든 엔트리가 하나의 연속 배열에 있으므로, 같은 버킷의 체인을 따라가도 배열 내부에서 이동하는 것이라 캐시 지역성이 보존된다. 전통적인 연결 리스트 체이닝과 근본적으로 다른 점이다.
Part 3: 충돌 해결 — 오픈 어드레싱
오픈 어드레싱의 기본 아이디어
체이닝과 완전히 다른 접근: 외부 구조 없이 배열 자체에서 빈 자리를 찾는다.
충돌이 발생하면 미리 정해진 탐색 규칙(probing sequence)에 따라 다음 빈 슬롯을 찾는다. 모든 데이터가 하나의 배열 안에 존재한다.
Linear Probing — 가장 단순하고 가장 캐시 친화적
충돌 시 다음 칸, 그 다음 칸, … 순서대로 빈 자리를 찾는다.
\[h(k, i) = (h(k) + i) \mod m, \quad i = 0, 1, 2, \ldots\]1
2
3
4
5
6
7
8
9
10
삽입 과정: h("오크")=2, h("슬라임")=2(충돌!), h("트롤")=3
Step 1: "오크" → index 2 (비어있음) → 삽입
[ ] [ ] [오크] [ ] [ ] [ ] [ ] [ ]
Step 2: "슬라임" → index 2 (충돌!) → 3 (비어있음) → 삽입
[ ] [ ] [오크] [슬라임] [ ] [ ] [ ] [ ]
Step 3: "트롤" → index 3 (충돌!) → 4 (비어있음) → 삽입
[ ] [ ] [오크] [슬라임] [트롤] [ ] [ ] [ ]
캐시 성능이 뛰어나다. 탐색이 연속된 메모리를 순차적으로 접근하므로, 1편에서 배운 공간 지역성(spatial locality)의 혜택을 최대로 받는다. 캐시 라인 하나(64바이트)에 여러 슬롯이 들어가므로, 탐색의 대부분이 L1 캐시에서 해결된다.
클러스터링(Clustering) 문제:
Linear probing의 약점이다. 충돌이 발생하면 그 옆에 데이터가 쌓이고, 쌓인 데이터가 또 충돌을 유발하여 클러스터가 커진다. 이것을 Primary Clustering이라 한다.
1
2
3
4
클러스터 형성 과정:
[ ][ ][██][██][██][██][ ][ ] ← 4칸 클러스터
이 근처에 해시되는 키는 모두 여기 합류
[ ][ ][██][██][██][██][██][ ] ← 5칸으로 성장
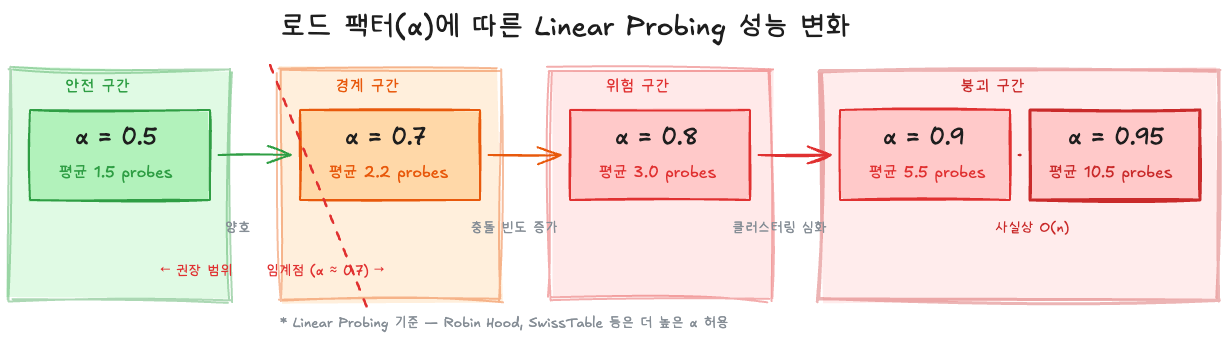
Knuth는 TAOCP Vol. 3에서 linear probing의 평균 탐색 길이를 분석했다:
성공적 탐색 (키가 존재할 때):
\[E[\text{probes}] = \frac{1}{2}\left(1 + \frac{1}{1 - \alpha}\right)\]실패한 탐색 (키가 없을 때):
\[E[\text{probes}] = \frac{1}{2}\left(1 + \frac{1}{(1 - \alpha)^2}\right)\]| 로드 팩터 α | 성공 탐색 (평균) | 실패 탐색 (평균) |
|---|---|---|
| 0.50 | 1.5회 | 2.5회 |
| 0.70 | 2.2회 | 6.1회 |
| 0.80 | 3.0회 | 13.0회 |
| 0.90 | 5.5회 | 50.5회 |
| 0.95 | 10.5회 | 200.5회 |
Linear probing에서는 α = 0.7을 넘으면 성능이 급격히 나빠진다. 특히 실패 탐색(키가 없는 경우)은 빈 슬롯을 만날 때까지 계속 탐색해야 하므로 더 민감하다. 이 수치가 linear probing에 적용되는 이유는 클러스터링 때문이다 — 충돌이 발생하면 바로 옆에 쌓이고, 쌓인 것이 또 충돌을 유발하는 양성 피드백이 작용한다.
그러나 모든 오픈 어드레싱이 이 수치에 묶이는 것은 아니다. Quadratic probing은 탐색이 제곱 간격으로 퍼지므로 클러스터가 덜 형성되고, Robin Hood Hashing은 탐색 거리의 분산을 줄여 최악의 경우를 억제한다. SwissTable은 SIMD로 16개 슬롯을 한 번에 비교하여 탐색 비용 자체를 줄인다. 이런 기법들 덕분에 Rust HashMap은 α=0.875, Go map은 버킷당 6.5개(실효 α≈0.81)까지 허용할 수 있다. 뒤의 로드 팩터 비교표에서 이 차이를 확인하자.
Quadratic Probing — 클러스터 분산
Linear probing의 클러스터링을 줄이기 위해, 제곱 간격으로 탐색한다:
\[h(k, i) = (h(k) + c_1 i + c_2 i^2) \mod m\]일반적으로 $c_1 = 0, c_2 = 1$:
\[h(k, i) = (h(k) + i^2) \mod m\]탐색 순서: +1, +4, +9, +16, … 점점 멀리 뛰므로 primary clustering이 완화된다.
단점: secondary clustering — 같은 초기 해시 값을 가진 키들은 동일한 탐색 경로를 따른다. 또한 테이블 크기와 $c_1$, $c_2$를 적절히 선택하지 않으면 모든 슬롯을 방문하지 못할 수 있다. 테이블 크기가 소수이고 로드 팩터가 0.5 이하이면 안전하다.
Robin Hood Hashing — 부자에게서 빼앗아 가난한 자에게
1986년 Pedro Celis의 박사 논문에서 제안된 기법으로, linear probing의 변형이다. 핵심 아이디어:
삽입할 때, 현재 슬롯의 기존 원소보다 내가 더 멀리서 왔다면, 기존 원소를 밀어내고 내가 들어간다.
“이상적 위치(home position)”로부터의 거리를 DIB(Distance from Initial Bucket)라 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
삽입 "D" (home=2, 현재 탐색 위치=5, DIB=3)
[0] [1] [2] [3] [4] [5] [6] [7]
A B C E F
DIB=0 DIB=0 DIB=1 DIB=3 DIB=1
"D"의 DIB=3. 위치 5의 "F"는 DIB=1.
3 > 1이므로 "D"가 "F"를 밀어내고 위치 5에 삽입.
"F"는 밀려나서 다음 빈 자리를 찾음.
결과:
[0] [1] [2] [3] [4] [5] [6] [7]
A B C E D F
DIB=0 DIB=0 DIB=1 DIB=3 DIB=3 DIB=2
효과: 모든 원소의 DIB가 비슷해진다. 최대 탐색 거리가 줄어들고, 탐색 거리의 분산(variance)이 극적으로 감소한다. 평균은 같지만 최악이 개선된다.
| 특성 | Linear Probing | Robin Hood Hashing |
|---|---|---|
| 평균 탐색 거리 | 같음 | 같음 |
| 최대 탐색 거리 | 클 수 있음 | 크게 감소 |
| 분산 | 큼 | 작음 |
| 삽입 비용 | 낮음 | 약간 높음 (swap) |
Rust의 HashMap은 오랫동안 Robin Hood Hashing을 사용했다(현재는 SwissTable 기반 hashbrown으로 변경). 이 기법이 실전에서 효과적이라는 증거다.
잠깐, 이건 짚고 넘어가자
Q. 오픈 어드레싱에서 삭제는 어떻게 하나?
단순히 비우면 안 된다. 탐색 도중 빈 슬롯을 만나면 “없다”고 판단하기 때문이다. 삭제된 자리에 묘비(tombstone) 마커를 놓는다. 탐색 시 tombstone은 “여기를 지나가시오”로 취급하고, 삽입 시에는 “여기에 넣어도 됨”으로 취급한다.
tombstone이 누적되면 탐색 성능이 나빠지므로, 주기적으로 리사이징(또는 재삽입)하여 정리해야 한다.
Q. 체이닝 vs 오픈 어드레싱, 실전에서 어떤 게 빠른가?
대부분의 벤치마크에서 linear probing이 체이닝보다 빠르다 — 캐시 지역성 때문이다. 단, 로드 팩터가 높아지면 역전될 수 있다. 현대적 고성능 해시 테이블(Google SwissTable, Facebook F14, Rust hashbrown)은 전부 오픈 어드레싱 기반이다.
Part 4: 로드 팩터와 리사이징
로드 팩터
\[\alpha = \frac{n}{m}\]- $n$: 저장된 원소 수
- $m$: 배열(버킷) 크기
- $\alpha$: 로드 팩터(Load Factor)
로드 팩터는 해시 테이블의 밀도다. α = 0이면 완전히 비어있고, α = 1이면 꽉 찼다(오픈 어드레싱 기준). 체이닝에서는 α > 1도 가능하지만, 성능이 나빠진다.
언어별 로드 팩터 임계값
| 언어/구현 | 최대 로드 팩터 | 충돌 해결 | 리사이징 |
|---|---|---|---|
Java HashMap | 0.75 | 체이닝 (→ 트리 전환) | 2배 |
.NET Dictionary | 1.0 (entries 꽉 차면) | 배열 내 체이닝 | 소수 단위 ~2배 |
Python dict | 0.67 | 오픈 어드레싱 | 4배 (작을 때) / 2배 |
Go map (~1.23) | 6.5 (버킷당) | 체이닝 (8개 슬롯/버킷) | 2배 |
Go map (1.24+) | Swiss Tables 기반으로 전환 | 오픈 어드레싱 (Swiss Tables) | 2배 |
Rust HashMap | 0.875 | Robin Hood → SwissTable | 2배 |
Java는 특이하게, 하나의 버킷에 원소가 8개 이상 쌓이면 연결 리스트를 레드-블랙 트리로 변환한다. O(n)으로 퇴화하는 것을 O(log n)으로 막는 방어 메커니즘이다. 단, 정확히는 테이블 전체 용량이 64 이상일 때만 트리로 전환한다. 테이블이 작을 때는 트리 전환보다 리사이징(배열 확장)이 더 효과적이기 때문이다 — 버킷 수를 늘려서 충돌을 분산시키는 것이 소규모 테이블에서는 트리 구축보다 비용이 적다. OpenJDK 소스의 MIN_TREEIFY_CAPACITY = 64 상수가 이 조건이다.
리사이징의 비용
리사이징은 세 단계로 이루어진다:
- 새 배열 할당 (보통 2배 크기)
- 모든 원소를 재해싱 — 해시 값은 같지만,
hash % newSize는 달라지므로 위치가 바뀐다 - 구 배열 해제
전체 O(n). 하지만 2편에서 배운 상각 분석을 적용하면, n번 삽입의 총 리사이징 비용은 O(n)이므로 삽입당 상각 O(1)이다.
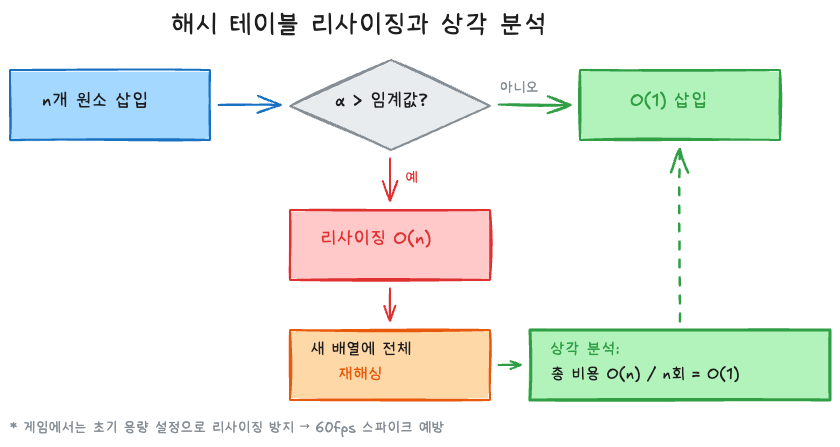
게임 개발에서의 교훈은 2편과 동일하다: 원소 개수를 미리 안다면 초기 용량을 설정하여 리사이징을 아예 방지하라. 60fps에서 16.67ms 프레임 예산 중에 해시 테이블 리사이징이 터지면 스파이크가 발생한다.
Part 5: 캐시 성능 — 체이닝 vs 오픈 어드레싱
1편에서 배열과 연결 리스트의 캐시 성능 차이를 살펴보았다. 해시 테이블의 두 전략에도 정확히 같은 원리가 적용된다.
체이닝의 메모리 접근 패턴
1
2
3
4
5
6
7
버킷 배열: [ptr0] [ptr1] [ptr2] [ptr3] [ptr4] ... ← 연속 메모리
체인 노드:
0x1000: Node(고블린) → next: 0x5040
0x5040: Node(슬라임) → next: NULL
포인터를 따라가므로 메모리 접근이 비순차적 → 캐시 미스
- 버킷 배열 접근: O(1), 캐시 히트 (배열이니까)
- 체인 노드 접근: 포인터 추적 → 캐시 미스 가능성 높음
- 노드당 추가 메모리: 포인터(8바이트) + 힙 할당 오버헤드
Linear Probing의 메모리 접근 패턴
1
2
3
슬롯 배열: [고블린][슬라임][오크][ ][ ][드래곤][ ][ ] ← 전체 연속 메모리
충돌 시 다음 칸으로 이동 → 순차적 메모리 접근 → 캐시 히트
- 모든 접근이 하나의 배열 내에서 발생
- 순차 탐색은 캐시 라인 내 이동 — L1 히트
- 추가 메모리 오버헤드: 없음 (또는 tombstone 비트 정도)
Google SwissTable의 접근
Google의 Abseil 라이브러리에 포함된 SwissTable(2017)은 현대 해시 테이블 설계의 이정표다. 핵심 아이디어:
- 메타데이터 배열(control bytes): 각 슬롯에 대해 1바이트의 제어 바이트를 별도 배열에 저장. 이 바이트의 최상위 비트(MSB)가 슬롯의 상태를 결정한다
- SIMD 탐색: 16개 제어 바이트를 SSE2 명령어 한 번으로 동시 비교
제어 바이트의 구조:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Control byte 해석:
MSB = 0 (0x00~0x7F): 슬롯이 차있음(FULL)
→ 하위 7비트 = 해시의 상위 7비트 (H2라 부른다)
→ 예: 0x31 = 차있음, H2=0x31
MSB = 1 (0x80~0xFF): 특수 상태
→ 0xFF = EMPTY (비어있음)
→ 0xFE = DELETED (삭제됨, tombstone)
Control bytes 예시 (16개 그룹):
[0x31][0xFF][0x55][0xFF][0x31][0x72][0xFF][0xFF]
[0xFF][0x1A][0xFF][0xFF][0xFF][0xFF][0xFE][0xFF]
FULL EMPTY FULL EMPTY FULL FULL EMPTY EMPTY
DEL EMPTY
키 “오크”를 조회하는 과정:
1
2
3
4
5
6
7
8
9
1. hash("오크")를 계산
2. 해시의 하위 비트로 그룹(16개 슬롯) 선택
3. 해시의 상위 7비트 추출 → H2 = 0x31
4. SIMD로 그룹의 16개 제어 바이트와 0x31을 한 번에 비교
→ index 0과 4에서 H2가 매칭!
5. 매칭된 슬롯(0, 4)에서만 실제 키 비교 수행
→ index 0: 키 불일치, index 4: "오크" 확인!
대부분의 경우: SIMD 1번 + 키 비교 1~2번으로 끝남
왜 이게 빠른가? 핵심은 비교 횟수의 극적 감소다. 기존 linear probing은 매 슬롯마다 전체 키를 비교해야 한다. SwissTable은 1바이트 제어 바이트를 SIMD로 16개 동시에 걸러낸 뒤, 실제 키 비교는 H2가 일치하는 슬롯(보통 0~2개)에서만 수행한다. 캐시 라인 하나(64바이트)에 제어 바이트 64개가 들어가므로, 메타데이터 접근은 거의 항상 L1 캐시에서 해결된다.
이 설계의 영향:
- C++ Abseil
absl::flat_hash_map - Rust
hashbrown(SwissTable 포트 → 표준 HashMap) - Go 1.24+
runtime.map(Swiss Tables 도입, 기존 버킷 체이닝에서 전환)
잠깐, 이건 짚고 넘어가자
Q. SIMD가 뭔가?
SIMD(Single Instruction, Multiple Data)는 하나의 명령어로 여러 데이터를 동시에 처리하는 CPU 기능이다. SSE2의
_mm_cmpeq_epi8은 16바이트를 한 번에 비교한다. SwissTable은 이 하드웨어 기능을 자료구조 설계에 직접 활용한 사례다. SIMD는 7단계(고급 최적화)에서 깊이 다룬다.Q. 그래서 게임 개발에서는 어떤 해시 테이블을 써야 하나?
- C#/Unity:
Dictionary<K,V>가 이미 배열 내 체이닝으로 캐시 친화적이다. 대부분의 경우 충분하다.- C++/Unreal:
TMap(기본), 고성능이 필요하면absl::flat_hash_map고려.- 커스텀 엔진: Robin Hood Hashing 또는 SwissTable 직접 구현을 고려. 오브젝트 수만 개 이상의 조회가 매 프레임 발생하는 경우 차이가 유의미하다.
Part 6: 해시 테이블의 응용 — 게임 개발에서
1. 공간 해싱(Spatial Hashing) — 충돌 감지 최적화
2D/3D 게임에서 N개 오브젝트의 충돌 감지를 순진하게 하면 O(N²) 쌍 비교가 필요하다. 공간 해싱은 이를 O(N)에 가깝게 줄인다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
공간을 격자로 나누고, 각 셀에 오브젝트를 해싱
┌──────┬──────┬──────┬──────┐
│ │ A │ │ │
│ │ │ │ │
├──────┼──────┼──────┼──────┤
│ │ B C │ D │ │ B와 C는 같은 셀
│ │ │ │ │ → 이 둘만 충돌 검사
├──────┼──────┼──────┼──────┤
│ │ │ │ E │
│ │ │ │ │
└──────┴──────┴──────┴──────┘
해시 함수: h(x, y) = (x / cellSize, y / cellSize)
해시 테이블: {(1,0): [A], (1,1): [B,C], (2,1): [D], (3,2): [E]}
같은 셀에 있는 오브젝트끼리만 충돌 검사하면 된다. 인접 셀까지 포함해도 상수 개(최대 9개, 3D면 27개)의 셀만 확인한다.
이 기법은 파티클 시스템, 군중 시뮬레이션, 물리 엔진의 broad phase에서 널리 사용된다.
2. 문자열 인터닝(String Interning)
게임에서 문자열은 곳곳에 쓰인다: 이벤트 이름, 태그, 리소스 경로. 매번 문자열을 비교하면 O(L)이다.
문자열 인터닝: 같은 내용의 문자열을 하나의 인스턴스만 유지하는 기법. 해시 테이블에 문자열을 저장하고, 동일한 내용이면 기존 인스턴스를 반환한다.
1
2
3
4
5
6
7
// 인터닝 전: 문자열 비교 = O(L), 길이에 비례
if (eventName == "OnPlayerDeath") { ... }
// 인터닝 후: 참조 비교 = O(1)
// string.Intern()은 CLR 인터닝 풀에 저장
string interned = string.Intern("OnPlayerDeath");
if (ReferenceEquals(eventName, interned)) { ... }
Unreal Engine의 FName이 정확히 이 원리다. 문자열을 해시 테이블에 저장하고, 이후에는 정수 인덱스로 비교한다. 문자열 비교 O(L) → 정수 비교 O(1).
3. 메모이제이션(Memoization) — 계산 결과 캐시
비싼 계산의 결과를 해시 테이블에 캐시:
1
2
3
4
5
6
7
8
9
10
11
// 패스파인딩 결과를 캐시
private Dictionary<(Vector2Int from, Vector2Int to), List<Vector2Int>> pathCache;
public List<Vector2Int> FindPath(Vector2Int from, Vector2Int to) {
if (pathCache.TryGetValue((from, to), out var cached))
return cached; // O(1) 캐시 히트
var path = AStar(from, to); // 비싼 계산
pathCache[(from, to)] = path;
return path;
}
4. 중복 검사
방문한 노드, 처리한 이벤트, 로드한 리소스 — “이미 했는가?”를 O(1)로 확인:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
HashSet<int> visitedNodes = new(); // 내부적으로 해시 테이블
void BFS(int start) {
var queue = new Queue<int>();
queue.Enqueue(start);
visitedNodes.Add(start);
while (queue.Count > 0) {
int current = queue.Dequeue();
foreach (int neighbor in GetNeighbors(current)) {
if (visitedNodes.Add(neighbor)) { // O(1) 중복 체크 + 삽입
queue.Enqueue(neighbor);
}
}
}
}
HashSet은 키만 있는 해시 테이블이다. 2편의 BFS에서 distance[nx, ny] == -1로 방문 여부를 확인했는데, 격자가 아닌 그래프에서는 HashSet이 필요하다.
Part 7: 해시 테이블의 한계와 보안
HashDoS — 해시 충돌 공격
2011년, Alexander Klink와 Julian Wälde가 발표한 HashDoS 공격: 의도적으로 같은 해시 값을 가지는 키를 대량으로 보내면, 해시 테이블이 O(n²)으로 퇴화한다.
웹 서버가 HTTP 파라미터를 해시 테이블에 저장하므로, 수만 개의 충돌 키를 보내면 서버가 멈춘다. 이 공격은 PHP, Java, Python, Ruby, .NET 등 거의 모든 언어의 웹 프레임워크에 영향을 미쳤다.
대응책:
- 랜덤 시드 해시(Keyed Hash): 프로세스마다 비밀 시드를 섞어 해시 함수를 예측 불가능하게. Python은 3.3부터, .NET Core는 기본으로 적용
- SipHash: Jean-Philippe Aumasson이 설계한 “짧은 입력에 안전한” 해시 함수. Rust, Python, Ruby에서 기본 사용
- 트리 전환: Java HashMap의 체인 8개 초과 시 레드-블랙 트리 전환
게임 서버에서도 유효한 위협이다. 클라이언트가 보내는 데이터를 해시 테이블에 저장한다면(인벤토리, 채팅 필터 등), HashDoS를 고려해야 한다.
해시 테이블 vs 정렬된 구조
| 특성 | 해시 테이블 | 균형 이진 트리 (4편 예고) |
|---|---|---|
| 평균 조회 | O(1) | O(log n) |
| 최악 조회 | O(n) | O(log n) |
| 순서 보장 | 없음 | 있음 |
| 범위 질의 | 불가 | 가능 |
| 메모리 오버헤드 | 중간 (빈 슬롯) | 높음 (포인터) |
| 최솟값/최댓값 | O(n) | O(log n) |
해시 테이블은 “이 키의 값은?”이라는 점 질의(point query)에 최적이다. “100~200 사이의 키를 모두 찾아라” 같은 범위 질의(range query)나, “키 순서대로 순회하라”는 요구에는 부적합하다. 이런 경우에는 4편에서 다룰 트리 구조가 필요하다.
마무리: O(1)은 공짜가 아니다
이 글에서 살펴본 핵심:
해시 테이블의 O(1)은 해시 함수의 품질에 의존한다. 나쁜 해시 함수는 충돌을 집중시키고, O(1)을 O(n)으로 만든다. 나눗셈법에서 소수를 사용하는 이유, 곱셈법에서 황금비를 사용하는 이유가 여기에 있다.
충돌은 피할 수 없다 — 비둘기집 원리와 생일 문제가 이를 수학적으로 보장한다. 충돌을 어떻게 해결하느냐가 해시 테이블의 성격을 결정한다. 체이닝은 단순하지만 캐시에 불리하고, 오픈 어드레싱(특히 linear probing)은 캐시 친화적이지만 클러스터링에 취약하다.
로드 팩터(α)가 성능의 핵심 조절자다. Linear probing 기준으로 α가 0.7을 넘으면 충돌이 급증하고, 0.9를 넘으면 사실상 사용 불가능해진다. 다만 충돌 해결 전략에 따라 허용 가능한 로드 팩터는 달라진다 — Quadratic probing, Robin Hood Hashing, SwissTable 등은 클러스터링 완화나 SIMD 병렬 비교 덕분에 더 높은 로드 팩터에서도 안정적으로 동작한다. 리사이징은 O(n)이지만 상각 O(1)이다 — 그래도 게임에서는 초기 용량 설정으로 아예 방지하는 것이 최선이다.
캐시 성능이 이론적 복잡도만큼 중요하다. 1편의 교훈이 여기서도 반복된다. Google SwissTable이 SIMD를 활용하여 16개 슬롯을 한 번에 비교하는 것은, 알고리즘의 혁신이 아니라 하드웨어 특성에 맞춘 설계의 혁신이다.
해시 테이블은 만능이 아니다. 순서가 필요하거나, 범위 질의가 필요하거나, 최악의 경우 보장이 필요하면 트리 구조가 답이다.
Knuth는 TAOCP Vol. 3에서 해싱을 이렇게 요약했다:
“Hashing is a classical example of a time-space tradeoff.”
(해싱은 시간-공간 트레이드오프의 고전적 예시다.)
빈 슬롯이라는 공간 낭비를 감수함으로써, O(1) 시간을 얻는다. 이 트레이드오프를 이해하고, 로드 팩터와 해시 함수 품질로 균형점을 찾는 것이 해시 테이블을 올바르게 사용하는 방법이다.
다음 편에서는 트리 — 순서를 유지하면서 O(log n)을 보장하는 구조, BST에서 Red-Black Tree, B-Tree까지를 다룬다.
참고 자료
핵심 논문 및 기술 문서
- Knuth, D., The Art of Computer Programming Vol. 3: Sorting and Searching, Addison-Wesley — 해싱의 고전적 분석 (Chapter 6.4), linear probing 평균 탐색 길이 증명
- Celis, P., “Robin Hood Hashing”, PhD Thesis, University of Waterloo (1986) — Robin Hood Hashing의 원전
- Aumasson, J.P. & Bernstein, D.J., “SipHash: a fast short-input PRF”, INDOCRYPT (2012) — HashDoS 방어용 해시 함수
- Klink, A. & Wälde, J., “Efficient Denial of Service Attacks on Web Application Platforms”, 28C3 (2011) — HashDoS 공격의 원전
- Abseil Team, “Swiss Tables Design Notes” — abseil.io — SwissTable의 SIMD 기반 설계
강연 및 발표
- Kulukundis, M., “Designing a Fast, Efficient, Cache-friendly Hash Table, Step by Step”, CppCon 2017 — SwissTable의 설계 과정
- Chandler Carruth, “High Performance Code 201: Hybrid Data Structures”, CppCon 2016 — 캐시 친화적 해시 테이블 설계
교재
- Cormen, T.H. et al., Introduction to Algorithms (CLRS), MIT Press — 해시 테이블 Chapter 11, Universal Hashing, Perfect Hashing
- Bryant, R. & O’Hallaron, D., Computer Systems: A Programmer’s Perspective (CS:APP), Pearson — 메모리 계층과 캐시가 자료구조 성능에 미치는 영향
- Bloch, J., Effective Java, 3rd Edition, Addison-Wesley — Item 11: hashCode 구현 가이드
- Sedgewick, R. & Wayne, K., Algorithms, 4th Edition, Addison-Wesley — Linear Probing, Separate Chaining 구현과 분석
구현 참고
- .NET
Dictionary<TKey, TValue>— dotnet/runtime 소스: 배열 내 체이닝, 소수 기반 리사이징 - Java
HashMap— OpenJDK 소스: 체이닝 → 트리 전환, perturbation - Rust
hashbrown— crates.io: SwissTable 포트, Rust 표준 HashMap의 기반 - Google
absl::flat_hash_map— Abseil 라이브러리: SwissTable의 C++ 참조 구현 - Facebook
folly::F14— github.com/facebook/folly: SIMD 기반 오픈 어드레싱