
AGENTS.md는 정말 도움이 될까? - 코딩 에이전트의 컨텍스트 파일 효과를 검증한 논문 분석

- 실전 데이터로 보는 게임 개발자의 AI 활용법 - 2,165 메시지의 기록
- Claude Opus 4.5 → 4.6 전환기 - 게임 개발자가 체감한 성능, 토큰, 워크플로우의 변화
- AGENTS.md는 정말 도움이 될까? - 코딩 에이전트의 컨텍스트 파일 효과를 검증한 논문 분석
- Claude 메모리 무료 개방과 /simplify, /batch — 그리고 CLAUDE.md의 숨겨진 비용
- Windows에서 Claude Code 설치 완전 가이드 — 실전 트러블슈팅 포함
- 게임 기획자를 위한 Claude Code 완전 활용 가이드 — 사양서부터 밸런싱까지
- macOS에서 Claude Code C# LSP 완벽 세팅 가이드 — csharp-ls 설치부터 트러블슈팅까지
- C# LSP vs JetBrains MCP — 토큰 효율성 분석 리포트
- Claude Skills 2.0 완전 정복 — Skill Creator, 벤치마킹, 트리거 최적화까지
- Claude의 기억 시스템 심층 분석 — Auto Memory, Auto Dream, 그리고 Sleep-time Compute
- Claude Code 아키텍처 심층 분석 — AI 코딩 에이전트의 설계 원리를 추론하다
- AI 에이전트 하네스 엔지니어링 심층 해부 — 오케스트레이션 설계 원리와 C# 재구축
- AGENTS.md, CLAUDE.md 같은 컨텍스트 파일이 6만 개 이상의 레포에 채택되었지만, LLM이 자동 생성한 컨텍스트 파일은 성능을 오히려 떨어뜨리고 비용만 20% 이상 늘린다
- 핵심 원인은 기존 문서와의 중복 — 문서를 제거하면 컨텍스트 파일이 +2.7% 성능 향상을 보여, 정보 과잉이 문제임을 입증했다
- 개발자가 직접 작성한 최소한의 컨텍스트 파일만이 소폭의 효과를 보이며, 일반적인 코드베이스 개요보다 구체적인 툴링 요구사항이 더 유용하다

서론
Claude Code를 사용하면서 CLAUDE.md를 작성하는 것은 이제 거의 기본 워크플로우처럼 자리 잡았다. OpenAI의 Codex는 AGENTS.md를, Anthropic의 Claude Code는 CLAUDE.md를 권장하고, 이런 컨텍스트 파일은 현재 6만 개 이상의 오픈소스 레포지토리에 채택되어 있다.
하지만 이 파일들이 정말로 에이전트의 성능을 높여줄까? ETH Zurich와 Anthropic 연구진이 이 질문에 대해 최초의 대규모 실증 연구를 수행했다. 결과는 업계의 통념과 상당히 다르다.
논문: “Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?” 저자: Thibaud Gloaguen, Niels Mündler, Mark Müller, Veselin Raychev, Martin Vechev (ETH Zurich / Anthropic) arXiv: 2602.11988
1. 배경: 컨텍스트 파일이란?
코딩 에이전트용 컨텍스트 파일은 레포지토리 루트에 위치하는 마크다운 파일로, 에이전트에게 프로젝트의 구조, 빌드 방법, 코딩 규칙 등을 알려주는 역할을 한다.
| 에이전트 | 파일명 | 개발사 |
|---|---|---|
| Claude Code | CLAUDE.md | Anthropic |
| Codex | AGENTS.md | OpenAI |
| Cursor | .cursorrules | Cursor |
| Windsurf | .windsurfrules | Codeium |
이 파일들의 공통적인 구성:
- 코드베이스 개요: 디렉토리 구조, 주요 모듈 설명
- 빌드/테스트 명령어:
npm test,bundle exec jekyll serve등 - 코딩 컨벤션: 네이밍 규칙, 스타일 가이드
- 프로젝트별 특수 요구사항: 특정 도구 사용, 주의사항
업계에서는 이런 파일을 작성하면 에이전트가 프로젝트를 더 잘 이해하고 정확한 코드를 생성할 것이라고 기대해왔다. 그런데 실제로 그런가?
2. 실험 설계
2-1. 평가 파이프라인
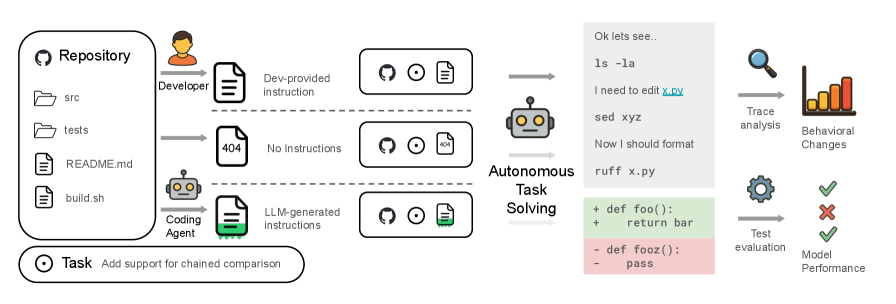 Figure 1. 평가 파이프라인 개요. 세 가지 조건(개발자 작성 컨텍스트 / 컨텍스트 없음 / LLM 생성 컨텍스트)에서 에이전트가 태스크를 해결하고, 생성된 패치를 유닛 테스트로 평가한다.
Figure 1. 평가 파이프라인 개요. 세 가지 조건(개발자 작성 컨텍스트 / 컨텍스트 없음 / LLM 생성 컨텍스트)에서 에이전트가 태스크를 해결하고, 생성된 패치를 유닛 테스트로 평가한다.
연구진은 세 가지 조건을 비교했다:
- None — 컨텍스트 파일 없이 작업
- LLM — LLM이 자동 생성한 컨텍스트 파일 제공
- Human — 개발자가 직접 작성한 컨텍스트 파일 제공
2-2. 벤치마크
SWE-bench Lite (기존 벤치마크)
- 11개 유명 Python 레포에서 300개 태스크
- Django, scikit-learn, sympy 등 잘 알려진 프로젝트
- 원래 컨텍스트 파일이 없어서 None vs LLM만 비교 가능
AGENTbench (이 논문에서 새로 제작)
- 개발자가 작성한 컨텍스트 파일이 실제로 존재하는 12개 니치 Python 레포에서 138개 인스턴스
- None, LLM, Human 세 가지 조건 모두 비교 가능
- 5,694개 PR에서 엄선하여 구성
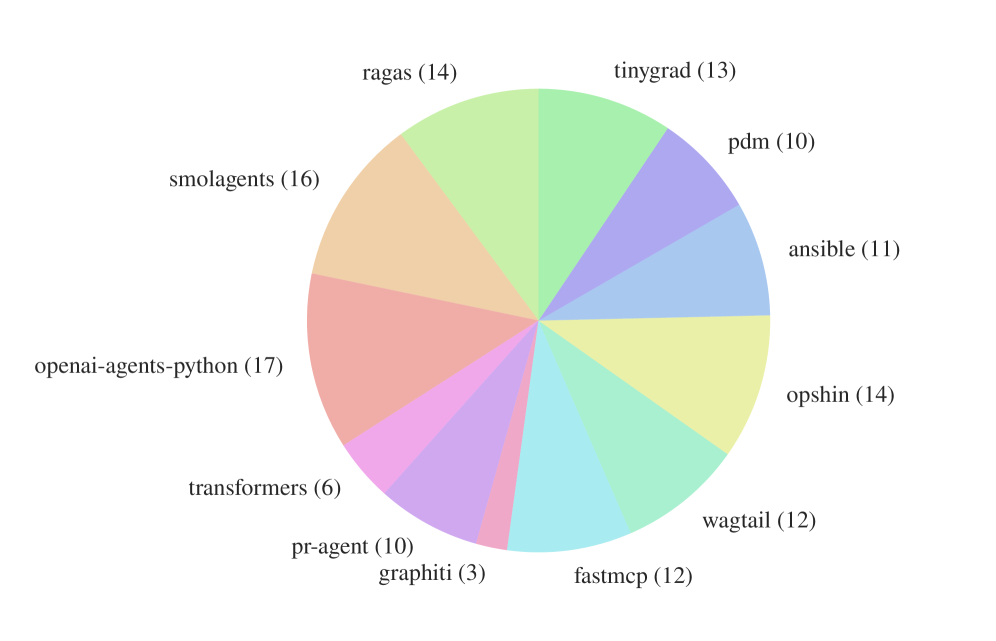 Figure 2. AGENTbench 인스턴스가 12개 오픈소스 레포지토리에 걸쳐 분포하는 모습. SWE-bench에 비해 특정 레포에 편중되지 않고 더 균등하게 분포되어 있다.
Figure 2. AGENTbench 인스턴스가 12개 오픈소스 레포지토리에 걸쳐 분포하는 모습. SWE-bench에 비해 특정 레포에 편중되지 않고 더 균등하게 분포되어 있다.
AGENTbench 통계
| 지표 | 평균 | 최솟값 | 최댓값 |
|---|---|---|---|
| PR 본문 길이 (단어) | 415.3 | 5 | 4,961 |
| Issue 설명 (단어) | 211.6 | 96 | 500 |
| 코드베이스 파일 수 | 3,337 | 151 | 26,602 |
| PR 패치 라인 수 | 118.9 | 12 | 1,973 |
| 수정 파일 수 | 2.5 | 1 | 23 |
| 테스트 커버리지 | 75% | 2.5% | 100% |
| 컨텍스트 파일 길이 (단어) | 641.0 | 24 | 2,003 |
| 컨텍스트 파일 섹션 수 | 9.7 | 1 | 29 |
2-3. 테스트한 에이전트
| 에이전트 | 모델 | 개발사 |
|---|---|---|
| Claude Code | Sonnet-4.5 | Anthropic |
| Codex | GPT-5.2 | OpenAI |
| Codex | GPT-5.1 mini | OpenAI |
| Qwen Code | Qwen3-30b-coder | Alibaba |
4개의 주요 코딩 에이전트를 2개의 벤치마크, 3가지 조건에서 평가 — 총 20개의 실험 조합을 테스트했다.
3. 핵심 결과: 컨텍스트 파일의 역설
3-1. 성능에 미치는 영향
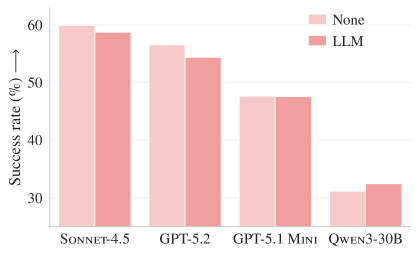 Figure 3a. SWE-bench Lite에서의 해결률. 4개 모델 모두에서 LLM 생성 컨텍스트 파일(주황색)이 컨텍스트 없음(파란색)보다 같거나 낮은 성공률을 보인다.
Figure 3a. SWE-bench Lite에서의 해결률. 4개 모델 모두에서 LLM 생성 컨텍스트 파일(주황색)이 컨텍스트 없음(파란색)보다 같거나 낮은 성공률을 보인다.
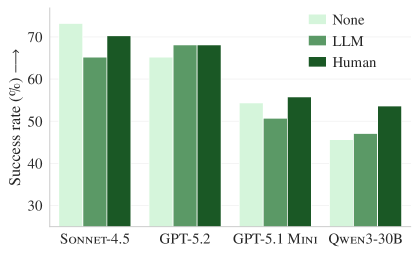 Figure 3b. AGENTbench에서의 해결률. 개발자 작성 컨텍스트(초록색)는 소폭 개선을 보이지만, LLM 생성 컨텍스트(주황색)는 여전히 성능을 떨어뜨린다.
Figure 3b. AGENTbench에서의 해결률. 개발자 작성 컨텍스트(초록색)는 소폭 개선을 보이지만, LLM 생성 컨텍스트(주황색)는 여전히 성능을 떨어뜨린다.
결과 요약:
| 조건 | SWE-bench Lite | AGENTbench |
|---|---|---|
| LLM 생성 컨텍스트 | -0.5% 성공률 ↓ | -2% 성공률 ↓ |
| 개발자 작성 컨텍스트 | (테스트 불가) | +4% 성공률 ↑ |
LLM이 자동 생성한 컨텍스트 파일은 두 벤치마크 모두에서 성능을 떨어뜨렸다. 개발자가 직접 작성한 파일도 개선 폭이 미미했다. 이 결과는 업계의 “컨텍스트 파일을 반드시 작성하라”는 권장과 정면으로 충돌한다.
3-2. 비용은 확실히 증가
반면 비용은 확실히 늘어났다.
| 모델 | 데이터셋 | None 비용 | LLM 비용 | Human 비용 |
|---|---|---|---|---|
| Sonnet-4.5 | SWE-bench | $1.30 | $1.51 (+16%) | — |
| GPT-5.2 | SWE-bench | $0.32 | $0.43 (+34%) | — |
| Sonnet-4.5 | AGENTbench | $1.15 | $1.33 (+16%) | $1.30 (+13%) |
| GPT-5.2 | AGENTbench | $0.38 | $0.57 (+50%) | $0.54 (+42%) |
| GPT-5.1 mini | AGENTbench | $0.18 | $0.20 (+11%) | $0.19 (+6%) |
| Qwen3-30b | AGENTbench | $0.13 | $0.15 (+15%) | $0.15 (+15%) |
평균 20% 이상의 비용 증가, 하지만 그에 상응하는 성능 향상은 없었다. 즉, 컨텍스트 파일은 비용 대비 효율이 마이너스인 셈이다.
4. 왜 컨텍스트 파일이 해로운가?
4-1. 기존 문서와의 정보 중복
이것이 논문의 가장 핵심적인 발견이다.
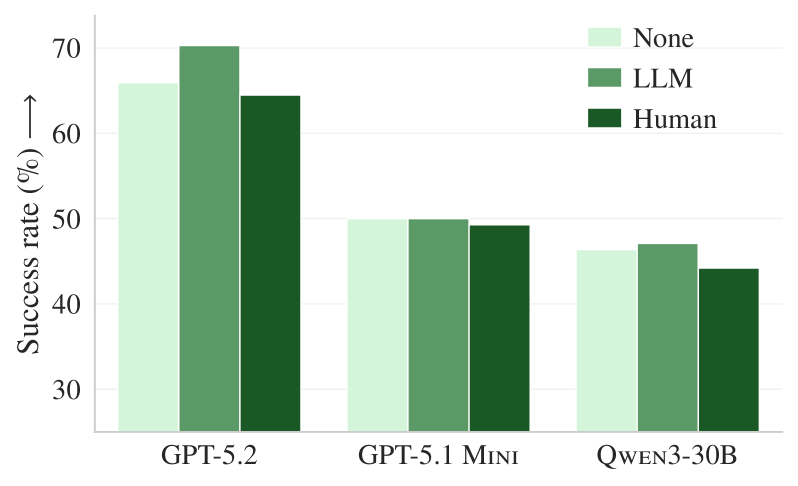 Figure 5. 기존 문서를 제거한 후의 AGENTbench 결과. 문서가 없을 때 LLM 생성 컨텍스트 파일(주황색)이 평균 +2.7% 성능 향상을 보이며, 개발자 작성 파일(초록색)보다도 높은 성과를 낸다.
Figure 5. 기존 문서를 제거한 후의 AGENTbench 결과. 문서가 없을 때 LLM 생성 컨텍스트 파일(주황색)이 평균 +2.7% 성능 향상을 보이며, 개발자 작성 파일(초록색)보다도 높은 성과를 낸다.
연구진은 레포지토리에서 .md 파일, 예제 코드, docs/ 폴더를 모두 제거한 상태에서 다시 실험했다. 결과:
- 문서가 있을 때: LLM 컨텍스트 파일이 -2% 성능 저하
- 문서를 제거하면: LLM 컨텍스트 파일이 +2.7% 성능 향상
이는 LLM이 생성하는 컨텍스트 파일이 이미 레포에 존재하는 README, 문서 등과 거의 동일한 정보를 담고 있다는 것을 입증한다. 중복된 정보가 에이전트를 혼란스럽게 만드는 것이다.
게임 개발로 비유하면, 같은 텍스처를 서로 다른 이름으로 두 번 로드하는 것과 비슷하다. 메모리만 낭비하고 렌더링 품질은 올라가지 않는다.
4-2. 파일 발견 속도 개선 없음
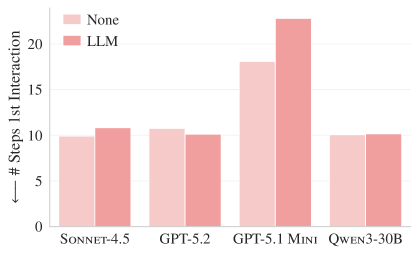 Figure 4a. SWE-bench Lite에서 에이전트가 관련 파일과 처음 상호작용하기까지의 스텝 수.
Figure 4a. SWE-bench Lite에서 에이전트가 관련 파일과 처음 상호작용하기까지의 스텝 수.
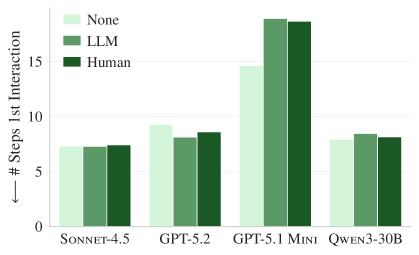 Figure 4b. AGENTbench에서도 동일한 패턴. 컨텍스트 파일이 있어도 관련 파일을 더 빨리 찾지 못한다.
Figure 4b. AGENTbench에서도 동일한 패턴. 컨텍스트 파일이 있어도 관련 파일을 더 빨리 찾지 못한다.
컨텍스트 파일에 코드베이스 개요가 있으면 에이전트가 관련 파일을 더 빨리 찾을 것이라 기대하지만, 실제로는 컨텍스트 파일 유무와 관계없이 15~25 스텝이 소요되었다. 코드베이스 개요가 파일 탐색 효율에 기여하지 못한다는 뜻이다.
4-3. 도구 사용은 늘지만 정확도는 그대로
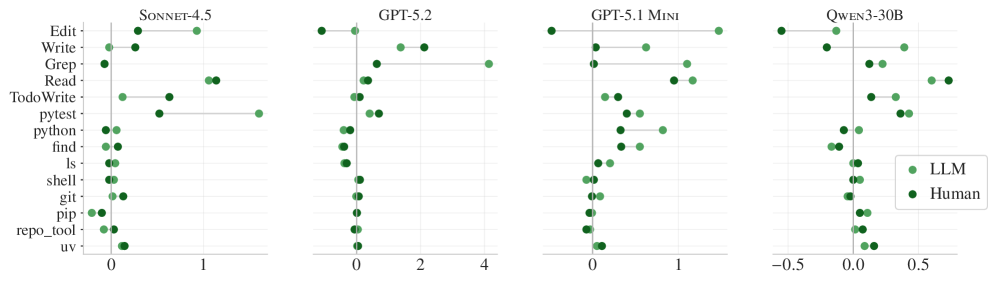 Figure 6. 컨텍스트 파일 포함 시 평균 도구 사용 증가량. grep, 테스트, 파일 읽기 등 거의 모든 도구 사용이 증가하지만 성공률은 오르지 않는다.
Figure 6. 컨텍스트 파일 포함 시 평균 도구 사용 증가량. grep, 테스트, 파일 읽기 등 거의 모든 도구 사용이 증가하지만 성공률은 오르지 않는다.
컨텍스트 파일이 있을 때 에이전트의 행동 변화:
- grep 사용: +30~50% 증가
- 테스트 실행: +40~100% 증가
- 레포 특정 도구: 컨텍스트 파일에 언급되면 2.5배 더 많이 사용
- 패키지 관리자 (uv 등): 언급되면 1.6배 더 사용
에이전트는 컨텍스트 파일의 지시를 충실히 따른다. 문제는 그 지시를 따르는 것이 더 나은 결과로 이어지지 않는다는 점이다. 더 많이 검색하고, 더 많이 테스트하지만, 정답에는 더 가까워지지 않는 — 일종의 “부지런한 비효율” 이다.
4-4. 추론 토큰 소비 증가
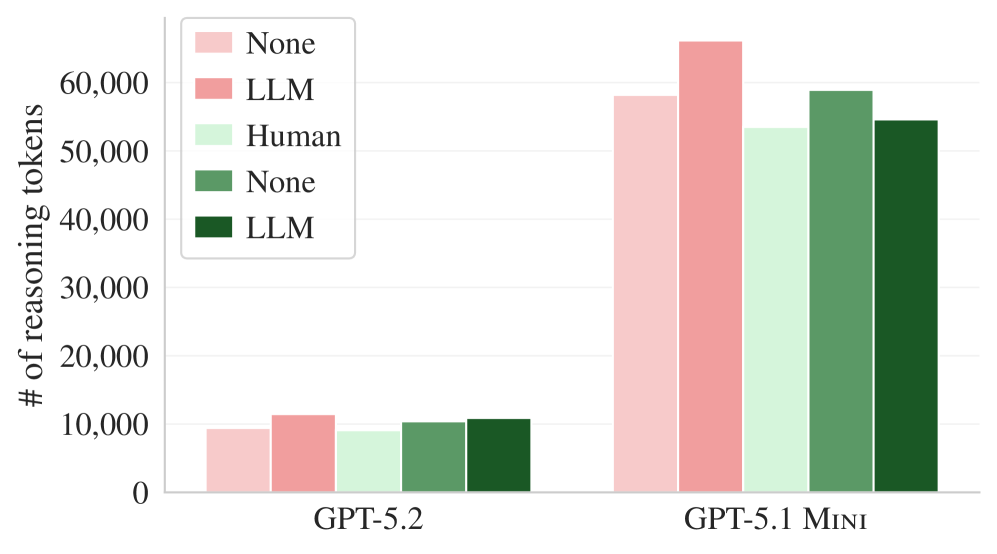 Figure 7. GPT-5.2와 GPT-5.1 mini의 평균 추론 토큰 사용량. 컨텍스트 파일이 있으면 추론에 더 많은 토큰을 소비한다.
Figure 7. GPT-5.2와 GPT-5.1 mini의 평균 추론 토큰 사용량. 컨텍스트 파일이 있으면 추론에 더 많은 토큰을 소비한다.
| 모델 | LLM 컨텍스트 시 추론 토큰 증가 | Human 컨텍스트 시 추론 토큰 증가 |
|---|---|---|
| GPT-5.2 | +22% | +20% |
| GPT-5.1 mini | +14% | +2% |
에이전트가 컨텍스트 파일을 처리하고 그 지시사항을 추론에 반영하느라 더 많은 토큰을 소비한다. 하지만 이 추가 추론이 더 나은 결과로 이어지지 않으므로, 순수한 낭비다.
5. 왜 이런 결과가 나왔을까?
논문의 발견들을 종합하면 다음과 같은 메커니즘이 작동한다:
1
2
3
4
5
6
7
8
9
10
11
컨텍스트 파일 제공
├── 에이전트가 지시를 충실히 따름 ✅
│ ├── 더 많은 도구 사용 (grep, test 등)
│ ├── 더 넓은 범위 탐색
│ └── 더 많은 추론 토큰 소비
│
├── 하지만 정보가 중복됨 ❌
│ ├── README, docs/와 같은 내용
│ └── 에이전트가 이미 접근 가능한 정보
│
└── 결과: 비용 ↑, 성능 ↔ 또는 ↓
핵심 통찰: 문제는 에이전트의 “지시 따르기 능력” 부족이 아니라, 지시 자체의 정보 품질에 있다. 에이전트가 이미 스스로 발견할 수 있는 정보를 반복해서 알려주면, 오히려 탐색 범위가 넓어지고 비용만 증가한다.
6. 그래서 어떻게 해야 할까?
논문의 권장사항
레포지토리 관리자에게:
| 하지 말 것 | 해야 할 것 |
|---|---|
| LLM으로 컨텍스트 파일 자동 생성 | 직접 최소한의 필수 정보만 작성 |
| 코드베이스 전체 구조 설명 | 프로젝트 고유의 특수 요구사항만 기술 |
| 길고 상세한 컨텍스트 파일 | 짧고 구체적인 지시사항 |
에이전트 개발사에게:
- 자동 컨텍스트 파일 생성 권장을 재고해야 한다
- 더 많은 컨텍스트 생성보다 기존 컨텍스트 활용 방식 개선에 집중해야 한다
효과적인 컨텍스트 파일 작성법
논문의 결론을 바탕으로, 컨텍스트 파일에 포함할 가치가 있는 정보와 없는 정보를 정리하면:
포함할 가치가 있는 정보 (레포 고유, 문서에 없는 것):
1
2
3
4
5
6
7
8
9
10
11
# 빌드 명령어 (프로젝트 고유)
bundle exec jekyll serve # 로컬 개발
JEKYLL_ENV=production bundle exec jekyll build # 프로덕션
# 특수 도구 요구사항
- uv를 패키지 관리자로 사용할 것
- 테스트는 반드시 pytest-asyncio로 실행
# 프로젝트 고유 규칙
- 번역 파일은 .en.md, .ja.md 접미사 사용
- 이미지는 assets/img/post/{category}/ 하위에 저장
포함하지 않아도 되는 정보 (이미 문서에 있는 것):
1
2
3
4
5
6
7
8
9
# ❌ 코드베이스 구조 설명 (에이전트가 직접 탐색 가능)
src/
components/ — React 컴포넌트
utils/ — 유틸리티 함수
...
# ❌ 일반적인 코딩 규칙 (LLM이 이미 학습한 것)
- 변수명은 camelCase를 사용한다
- 함수는 단일 책임 원칙을 따른다
7. 논문의 한계와 향후 연구
이 논문이 완벽한 결론은 아니다. 몇 가지 한계점:
- Python 프로젝트만 대상: 학습 데이터에 잘 표현된 Python 레포에서의 결과다. Rust, Zig 같은 니치 언어나, 게임 엔진처럼 특수한 도메인에서는 컨텍스트 파일이 더 유용할 수 있다
- 태스크 해결률만 측정: 코드 품질, 보안, 스타일 일관성 같은 다른 지표는 평가하지 않았다
- 단일 태스크 기준: 장기적인 프로젝트에서 반복적으로 같은 레포에 작업할 때의 누적 효과는 미검증
- SWE-bench의 한계: 유명 레포 위주이므로 LLM이 이미 학습 데이터로 접한 코드일 가능성이 높다
향후 연구 방향
- 니치 프로그래밍 언어에서의 컨텍스트 파일 효과
- 코드 효율성·보안 측면의 영향 평가
- 진정으로 유용한 최소한의 컨텍스트 파일 자동 생성 방법
8. 이 블로그에 적용한다면
이 블로그(Epheria)는 Jekyll 기반의 정적 사이트로, CLAUDE.md를 상당히 상세하게 작성해두고 있다. 논문의 결론을 적용해보면:
유지할 가치가 있는 정보:
bundle exec jekyll serve등 빌드 명령어 — 프로젝트 고유- jekyll-polyglot 다국어 규칙 (
.en.md,.ja.md접미사) — 문서에 없는 프로젝트 고유 규칙 - 포스트 front matter 형식 — chirpy 테마 커스터마이징으로 인한 비표준 설정
assets/img/post/{category}/이미지 규칙 — 프로젝트 고유 컨벤션
재검토할 정보:
- 디렉토리 구조 전체 나열 — 에이전트가 직접 탐색 가능
- 카테고리별 포스트 수 통계 — 정보 제공이지만 에이전트 성능에 기여하지 않을 수 있음
- 일반적인 코딩 스타일 규칙 —
.editorconfig에 이미 정의됨
다만, 이 블로그는 논문이 대상으로 한 “유명 Python 레포”가 아니라 Jekyll + chirpy 커스터마이징이 많은 니치 프로젝트이므로, 논문의 “컨텍스트 파일 생략” 권장을 그대로 적용하기보다는 프로젝트 고유 정보 위주로 정제하는 것이 합리적이다.
마치며
이 논문의 결론을 한 문장으로 요약하면:
“에이전트가 이미 알 수 있는 것을 다시 알려주지 마라.”
컨텍스트 파일 자체가 나쁜 것이 아니다. 중복된 정보를 담는 것이 나쁜 것이다. LLM 자동 생성이 아닌 개발자가 직접 작성한, 최소한의 프로젝트 고유 정보만 담은 컨텍스트 파일은 여전히 소폭의 긍정적 효과를 보였다.
컨텍스트 파일을 작성할 때 스스로에게 물어보자: “이 정보를 에이전트가 레포를 탐색해서 스스로 알 수 있는가?” 답이 “예”라면, 그 내용은 컨텍스트 파일에 넣지 않는 것이 낫다.
References
- Gloaguen, T., Mündler, N., Müller, M., Raychev, V., & Vechev, M. (2026). Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? arXiv:2602.11988. https://arxiv.org/abs/2602.11988
- OpenAI. (2026). Custom instructions with AGENTS.md. https://developers.openai.com/codex/guides/agents-md/
- Anthropic. (2026). Claude Code Documentation — CLAUDE.md. https://docs.anthropic.com/en/docs/claude-code