
Claude Skills 2.0 완전 정복 — Skill Creator, 벤치마킹, 트리거 최적화까지

- 실전 데이터로 보는 게임 개발자의 AI 활용법 - 2,165 메시지의 기록
- Claude Opus 4.5 → 4.6 전환기 - 게임 개발자가 체감한 성능, 토큰, 워크플로우의 변화
- AGENTS.md는 정말 도움이 될까? - 코딩 에이전트의 컨텍스트 파일 효과를 검증한 논문 분석
- Claude 메모리 무료 개방과 /simplify, /batch — 그리고 CLAUDE.md의 숨겨진 비용
- Windows에서 Claude Code 설치 완전 가이드 — 실전 트러블슈팅 포함
- 게임 기획자를 위한 Claude Code 완전 활용 가이드 — 사양서부터 밸런싱까지
- macOS에서 Claude Code C# LSP 완벽 세팅 가이드 — csharp-ls 설치부터 트러블슈팅까지
- C# LSP vs JetBrains MCP — 토큰 효율성 분석 리포트
- Claude Skills 2.0 완전 정복 — Skill Creator, 벤치마킹, 트리거 최적화까지
- Claude의 기억 시스템 심층 분석 — Auto Memory, Auto Dream, 그리고 Sleep-time Compute
- Claude Code 아키텍처 심층 분석 — AI 코딩 에이전트의 설계 원리를 추론하다
- AI 에이전트 하네스 엔지니어링 심층 해부 — 오케스트레이션 설계 원리와 C# 재구축
- Skills 2.0은 Capability Uplift(기능 향상)와 Inquiry Preference(선호도 저장) 두 축으로 분류되며, 벤치마킹으로 스킬의 존재 가치를 수치로 판단할 수 있다
- Skill Creator가 생성·평가·개선·벤치마크 4가지 모드로 확장되어, 테스트 케이스 자동 생성부터 블라인드 A/B 비교까지 스킬 개발 전체 라이프사이클을 자동화한다
- 프론트매터에 context: fork, model, effort, hooks 등 새 옵션이 추가되고, Description 최적화 루프로 암시적 트리거 정확도를 대폭 개선할 수 있다

들어가며
Claude Code의 스킬(Skills) 시스템이 대규모 업데이트를 맞이했다. 기존에 SKILL.md 파일 하나로 지시사항을 적어두는 단순한 구조였다면, Skills 2.0은 자동 평가, 벤치마킹, 블라인드 비교, 트리거 최적화까지 갖춘 완전한 스킬 개발 프레임워크로 진화했다.
이번 업데이트의 핵심 변화:
- Skill Creator 플러그인이 Create·Eval·Improve·Benchmark 4가지 모드로 대폭 강화
- 스킬 사용/미사용 시 결과를 자동으로 A/B 테스트하는 벤치마킹 시스템 내장
- 프론트매터에
context: fork,model,effort,hooks등 정교한 실행 제어 옵션 추가 - Description 최적화 루프로 암시적 트리거 정확도 개선
이 글에서는 공식 문서, Skill Creator 구현체, Anthropic 블로그를 교차검증하며 실무에 필요한 모든 내용을 정리한다.
1. 스킬의 두 가지 분류 체계
Anthropic은 스킬의 역할을 명확히 두 가지로 나눈다.
1-1. Capability Uplift (기능 향상형)
Claude가 자체적으로 할 수 없는 새로운 능력을 부여하는 스킬이다.
- 회사 전용 체크리스트, 독자적 프레임워크, 특정 도구 연동
- AI 모델이 발전하면 기본 기능으로 흡수될 가능성이 있음
- 벤치마킹으로 “이 스킬이 아직 필요한가?”를 수치로 판단
예를 들어, 과거에는 PDF 텍스트 추출을 스킬로 가르쳐야 했지만, 모델이 발전하면서 기본 도구만으로 충분해질 수 있다. 이때 벤치마킹 결과 스킬 유무의 차이가 없다면 해당 스킬은 폐기 대상이다.
1-2. Inquiry Preference (요청 선호도형)
Claude가 이미 할 수 있지만, 특정 워크플로우나 톤앤매너를 일관되게 따르도록 하는 스킬이다.
- 커밋 메시지 스타일, 코드 리뷰 형식, 보고서 템플릿
- 객관적으로 “더 좋은” 결과가 아니라, 사용자가 원하는 방식의 결과를 보장
- 모델이 발전해도 사용자의 선호도는 변하지 않으므로 장기적으로 유지됨
공식 Best Practices 문서에서도 “Claude is already very smart — Only add context Claude doesn’t already have”라고 명시하고 있다. 불필요한 설명은 빼고, Claude가 모르는 것만 가르치는 것이 핵심이다.
2. Progressive Disclosure — 3단계 점진적 로딩
스킬은 컨텍스트 윈도우를 효율적으로 사용하기 위해 3단계로 나뉘어 로딩된다.
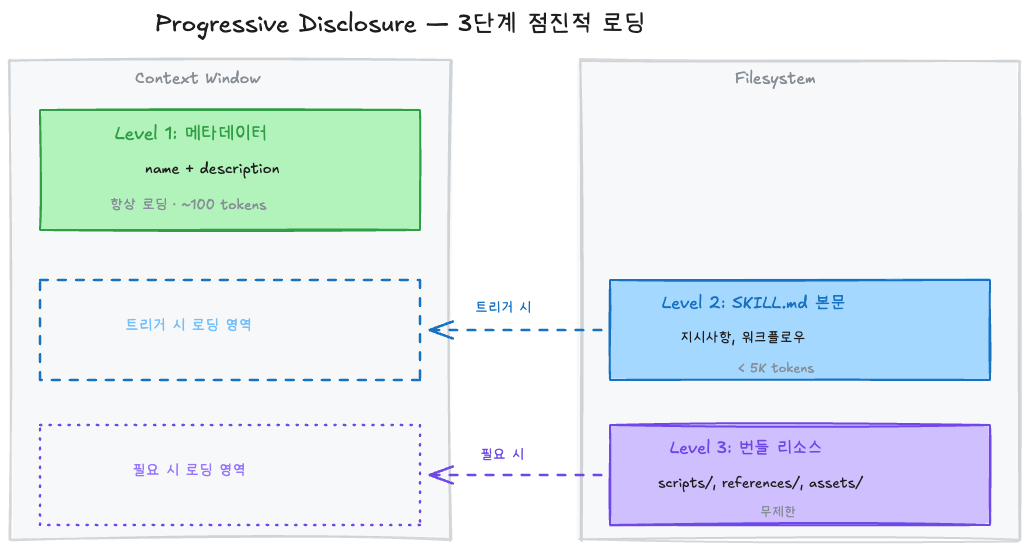
| 레벨 | 로딩 시점 | 토큰 비용 | 내용 |
|---|---|---|---|
| Level 1: 메타데이터 | 항상 (세션 시작 시) | ~100토큰/스킬 | name + description |
| Level 2: SKILL.md 본문 | 스킬 트리거 시 | 5K 토큰 이하 | 지시사항, 워크플로우 |
| Level 3: 번들 리소스 | 필요할 때만 | 사실상 무제한 | 스크립트, 레퍼런스 문서, 에셋 |
2-1. 디렉토리 구조
1
2
3
4
5
6
7
8
skill-name/
├── SKILL.md # 필수 — 메인 지시사항 (500줄 이하 권장)
├── references/ # 필요 시 로딩되는 참조 문서
│ ├── finance.md
│ └── sales.md
├── scripts/ # 실행만 함 (코드 자체는 컨텍스트에 안 들어감)
│ └── validate.py
└── assets/ # 템플릿, 아이콘, 폰트 등
핵심은 scripts/ 디렉토리다. Claude가 python scripts/validate.py를 실행하면, 스크립트의 코드 자체는 컨텍스트 윈도우에 들어가지 않고 실행 결과만 토큰을 소비한다. 수백 줄짜리 검증 로직도 출력 몇 줄로 요약된다.
2-2. 로딩 흐름 예시
1
2
3
4
5
1. 세션 시작 → "PDF Processing - Extract text and tables..." (메타데이터만 로딩)
2. 사용자: "이 PDF에서 표를 추출해줘"
3. Claude 판단 → SKILL.md 본문 로딩
4. 폼 작성이 필요한 경우에만 → FORMS.md 추가 로딩
5. 스크립트 실행 → 결과만 수신
많은 스킬을 설치해도 Level 1(메타데이터)만 상주하므로, 컨텍스트 패널티가 거의 없다. 스킬 description의 총 문자 예산은 컨텍스트 윈도우의 2% (폴백: 16,000자)로 동적 조절된다.
3. 프론트매터 완전 가이드
SKILL.md 상단의 YAML 프론트매터로 스킬의 동작을 세밀하게 제어할 수 있다. Skills 2.0에서 크게 확장된 부분이다.
3-1. 전체 필드 레퍼런스
| 필드 | 필수 여부 | 설명 |
|---|---|---|
name | No | 스킬 식별자. 소문자+숫자+하이픈만, 최대 64자 |
description | 권장 | 트리거의 핵심. 무엇을 하는지 + 언제 사용해야 하는지. 최대 1024자 |
disable-model-invocation | No | true → Claude가 자동 실행 불가 (사용자 /명령으로만) |
user-invocable | No | false → / 메뉴에서 숨김 (Claude만 내부적으로 사용) |
allowed-tools | No | 스킬 활성 시 허용할 도구 제한 (예: Read, Grep, Glob) |
model | No | 스킬 실행 시 사용할 AI 모델 지정 |
effort | No | 노력 수준: low, medium, high, max (Opus 4.6만 max) |
context | No | fork → 독립 서브에이전트에서 실행 |
agent | No | context: fork 시 에이전트 타입 (Explore, Plan 등) |
hooks | No | 스킬 라이프사이클 훅 (YAML 형식) |
argument-hint | No | 자동완성 힌트 (예: [issue-number]) |
3-2. 실행 권한 제어 — 누가 스킬을 호출할 수 있는가
| 설정 | 사용자 호출 | Claude 호출 | 컨텍스트 로딩 |
|---|---|---|---|
| 기본값 | O | O | description 항상 로딩 |
disable-model-invocation: true | O | X | description 미로딩 |
user-invocable: false | X | O | description 항상 로딩 |
실용 사례:
1
2
3
4
5
6
# 배포 스킬 — 사용자만 수동으로 실행해야 안전
---
name: deploy
description: Deploy the application to production
disable-model-invocation: true
---
Claude가 “코드가 준비된 것 같으니 배포하겠습니다”라고 자의적으로 판단하는 상황을 원천 차단한다.
1
2
3
4
5
6
# 레거시 시스템 컨텍스트 — Claude만 참조하는 배경 지식
---
name: legacy-system-context
description: Explains how the old auth system works
user-invocable: false
---
사용자가 /legacy-system-context를 직접 실행할 일은 없지만, Claude가 관련 질문을 받으면 자동으로 참조한다.
3-3. 문자열 치환 변수
스킬 본문에서 동적 값을 삽입할 수 있다:
| 변수 | 설명 |
|---|---|
$ARGUMENTS | 스킬 호출 시 전달된 전체 인수 |
$ARGUMENTS[N] 또는 $N | N번째 인수 (0-based) |
${CLAUDE_SESSION_ID} | 현재 세션 ID |
${CLAUDE_SKILL_DIR} | 스킬의 SKILL.md가 있는 디렉토리 |
1
2
3
4
5
6
7
---
name: migrate-component
description: Migrate a component from one framework to another
---
Migrate the $0 component from $1 to $2.
Preserve all existing behavior and tests.
/migrate-component SearchBar React Vue → $0=SearchBar, $1=React, $2=Vue
3-4. 서브에이전트 실행 (context: fork)
context: fork를 설정하면 스킬이 독립된 컨텍스트에서 실행된다. 대화 히스토리에 접근하지 않으며, SKILL.md 내용이 서브에이전트의 프롬프트가 된다.
1
2
3
4
5
6
7
8
9
10
11
---
name: deep-research
description: Research a topic thoroughly
context: fork
agent: Explore
---
Research $ARGUMENTS thoroughly:
1. Find relevant files using Glob and Grep
2. Read and analyze the code
3. Summarize findings with specific file references
agent 필드로 서브에이전트 타입을 지정할 수 있다: Explore (읽기 전용 탐색), Plan (설계), general-purpose (범용), 또는 .claude/agents/에 정의한 커스텀 에이전트.
3-5. 동적 컨텍스트 주입
!`command` 구문으로 셸 명령의 결과를 전처리 단계에서 삽입할 수 있다:
1
2
3
4
5
6
7
8
9
10
11
12
13
---
name: pr-summary
description: Summarize changes in a pull request
context: fork
agent: Explore
---
## Pull Request 컨텍스트
- PR diff: !`gh pr diff`
- 변경 파일: !`gh pr diff --name-only`
## 태스크
이 PR의 변경사항을 요약해줘...
각 !`command`는 Claude가 보기 전에 실행되어, Claude는 이미 치환된 최종 결과만 받는다.
4. Skill Creator — 스킬 개발 프레임워크
Skill Creator는 단순한 생성 도구에서 스킬의 전체 라이프사이클을 관리하는 프레임워크로 진화했다.
4-1. 4가지 운영 모드
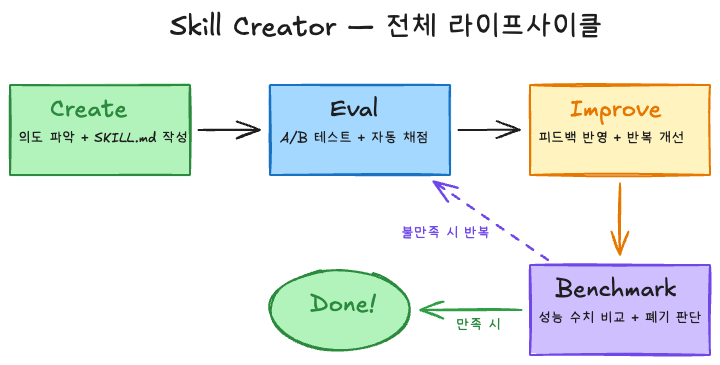
| 모드 | 목적 | 핵심 동작 |
|---|---|---|
| Create | 새 스킬 생성 | 의도 파악 → 인터뷰 → SKILL.md 작성 → 테스트 케이스 |
| Eval | 스킬 평가 | 테스트 프롬프트 실행 → assertions로 pass/fail 자동 판정 |
| Improve | 반복 개선 | 피드백 기반 수정 → 재실행 → 비교 → 만족할 때까지 반복 |
| Benchmark | 성능 벤치마크 | 스킬 사용 vs 미사용 A/B 테스트 → 통계 리포트 |
4-2. Create 모드 — 스킬 생성 워크플로우
Step 1: 의도 파악 (Capture Intent)
Skill Creator가 네 가지를 확인한다:
- 이 스킬이 Claude에게 무엇을 하게 할 것인가?
- 어떤 상황에서 트리거되어야 하는가?
- 기대하는 출력 형식은?
- 테스트 케이스를 설정할 것인가? (객관적 검증이 가능한 스킬은 권장, 주관적 스킬은 선택)
Step 2: 인터뷰 및 리서치
엣지 케이스, 입출력 형식, 예시 파일, 성공 기준, 의존성을 확인한다. MCP가 있으면 서브에이전트로 병렬 리서치도 수행한다.
Step 3: SKILL.md 작성
핵심 원칙:
- Description을 “pushy”하게 — Claude는 스킬을 과소 트리거(undertrigger) 하는 경향이 있다
- 3인칭으로 작성 — “Processes Excel files and generates reports” (Good) / “I can help you…” (Bad)
- Why를 설명 —
ALWAYS/NEVER보다 이유를 설명하는 것이 더 효과적 - 간결하게 — Claude가 이미 아는 것은 생략
1
2
3
4
5
6
7
8
# Bad: 너무 짧은 description
description: Helps with documents
# Good: what + when을 모두 포함하고 pushy하게
description: >
Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs,
forms, or document extraction.
Step 4: 테스트 케이스 생성
2~3개의 현실적 프롬프트를 evals/evals.json에 저장:
1
2
3
4
5
6
7
8
9
10
11
{
"skill_name": "pdf-processing",
"evals": [
{
"id": 1,
"prompt": "이 PDF에서 모든 텍스트를 추출해서 output.txt에 저장해줘",
"expected_output": "PDF의 모든 페이지에서 텍스트 추출 후 파일 저장",
"files": ["test-files/document.pdf"]
}
]
}
4-3. Eval 모드 — 평가 시스템 상세
멀티 에이전트 병렬 실행
각 테스트 케이스마다 두 개의 서브에이전트를 동시에 스폰한다:
1
2
3
테스트 케이스 1 → with_skill 에이전트 + without_skill 에이전트
테스트 케이스 2 → with_skill 에이전트 + without_skill 에이전트
테스트 케이스 3 → with_skill 에이전트 + without_skill 에이전트
각 에이전트는 독립된 컨텍스트에서 실행되므로 상호 오염이 없다. 토큰과 타이밍 지표도 개별 수집된다.
4종의 전문 서브에이전트
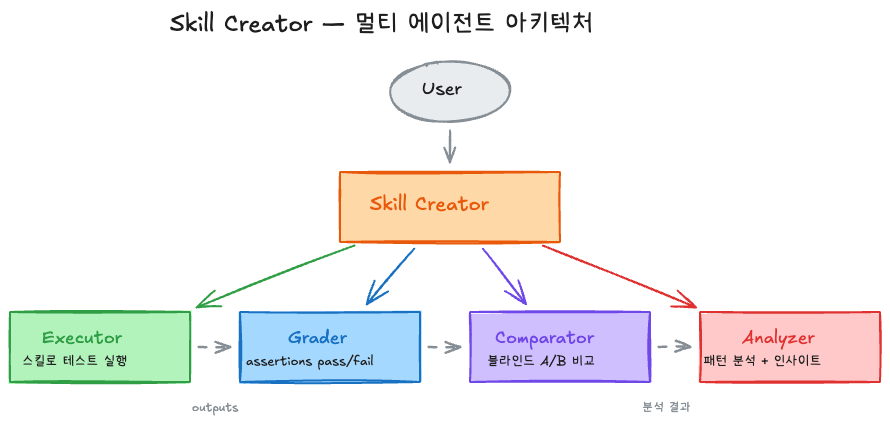
| 에이전트 | 역할 |
|---|---|
| Executor | 스킬을 사용해 테스트 프롬프트 실행 |
| Grader | assertions 기반 pass/fail 채점 + 증거 제시 |
| Comparator | 블라인드 A/B 비교 (어느 쪽이 스킬인지 모른 채 판단) |
| Analyzer | 벤치마크 패턴 분석 + 개선 인사이트 도출 |
5단계 평가 프로세스
Step 1: 서브에이전트 스폰 — with-skill과 baseline을 같은 턴에 모두 실행
Step 2: Assertions 초안 작성 — 실행되는 동안 검증 기준을 미리 작성 (시간 효율화)
1
2
3
4
5
6
7
8
9
10
{
"eval_id": 1,
"eval_name": "pdf-text-extraction",
"prompt": "Extract all text from this PDF",
"assertions": [
"PDF 라이브러리를 사용해 파일을 성공적으로 읽음",
"모든 페이지에서 텍스트를 추출함",
"output.txt에 읽기 쉬운 형식으로 저장함"
]
}
Step 3: 타이밍 데이터 즉시 캡처 — 서브에이전트 완료 시 timing.json에 토큰/시간 저장
1
2
3
4
5
{
"total_tokens": 84852,
"duration_ms": 23332,
"total_duration_seconds": 23.3
}
Step 4: 채점 → 집계 → 분석 → 뷰어 실행
1
2
3
4
5
6
7
8
9
# 벤치마크 집계
python -m scripts.aggregate_benchmark workspace/iteration-1 --skill-name pdf
# 뷰어 실행 (브라우저에서 결과 확인)
nohup python eval-viewer/generate_review.py \
workspace/iteration-1 \
--skill-name "pdf" \
--benchmark workspace/iteration-1/benchmark.json \
> /dev/null 2>&1 &
Step 5: 피드백 읽기 — 사용자가 뷰어에서 리뷰를 제출하면 feedback.json으로 수신
1
2
3
4
5
6
7
{
"reviews": [
{"run_id": "eval-0-with_skill", "feedback": "차트에 축 라벨이 없음"},
{"run_id": "eval-1-with_skill", "feedback": ""},
{"run_id": "eval-2-with_skill", "feedback": "완벽"}
]
}
빈 피드백은 “만족”을 의미한다. 구체적 불만이 있는 케이스에 집중해 개선한다.
5. 벤치마킹 시스템
5-1. 벤치마크 리포트 구조
벤치마킹이 완료되면 benchmark.json에 상세 통계가 기록된다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"run_summary": {
"with_skill": {
"pass_rate": {"mean": 0.85, "stddev": 0.05},
"time_seconds": {"mean": 45.0, "stddev": 12.0},
"tokens": {"mean": 3800, "stddev": 400}
},
"without_skill": {
"pass_rate": {"mean": 0.35, "stddev": 0.08},
"time_seconds": {"mean": 32.0, "stddev": 8.0},
"tokens": {"mean": 2100, "stddev": 300}
},
"delta": {
"pass_rate": "+0.50",
"time_seconds": "+13.0",
"tokens": "+1700"
}
}
}
핵심 지표:
- pass_rate — 스킬 사용 시 통과율 vs 미사용 시 통과율 (mean ± stddev)
- time_seconds — 실행 시간 비교
- tokens — 토큰 사용량 비교
- delta — 차이값
위 예시에서는 스킬이 통과율을 +50% 올리는 대신, 실행 시간 +13초와 토큰 +1700개의 비용이 든다.
5-2. 스킬 폐기 판단 기준
| 벤치마크 승률 | 해석 | 액션 |
|---|---|---|
| 70% 이상 | 스킬이 확실히 유용 | 유지 |
| 50~70% | 개선 여지 있음 | 모델 업데이트 후 재검토 |
| 50% 미만 | 스킬이 오히려 방해 | 삭제 또는 완전 재작성 |
모델 업그레이드 후 회귀(Regression) 확인이 벤치마킹의 핵심 용도다. 새 모델이 나왔을 때:
- 기존 벤치마크를 다시 실행
- 스킬 사용/미사용 간 차이가 줄었다면 → 모델이 해당 기능을 흡수 중
- 차이가 거의 없다면 → 스킬 폐기 고려
5-3. 블라인드 비교 (Blind Comparison)
더 엄밀한 비교가 필요할 때 사용하는 고급 기능이다:
- Comparator 에이전트에게 두 출력물을 A, B로 익명화해서 전달
- 어느 쪽이 스킬 적용인지 모른 채 content, structure, usability 기준으로 채점
- Analyzer 에이전트가 왜 승자가 이겼는지 분석 → 개선 인사이트 도출
1
2
3
4
5
6
7
{
"winner": "A",
"rubric": {
"A": {"content_score": 4.7, "structure_score": 4.3, "overall_score": 9.0},
"B": {"content_score": 2.7, "structure_score": 2.7, "overall_score": 5.4}
}
}
6. Improve 모드 — 반복 개선의 철학
6-1. 개선 원칙 4가지
Skill Creator 구현체에서 명시하는 개선 철학:
1. 일반화하라 (Generalize)
“우리는 수백만 번 사용될 스킬을 만들고 있다. 테스트 케이스 2~3개에 과적합하면 무의미하다.”
특정 테스트 케이스에만 맞는 세세한 수정보다, 다른 메타포나 패턴을 시도하는 것이 더 효과적이다.
2. 간결하게 유지하라 (Keep Lean)
트랜스크립트(실행 기록)를 읽어서, 스킬이 모델에게 비생산적인 작업을 시키는 부분을 찾아 제거한다. 최종 출력만이 아니라 실행 과정을 분석하는 것이 핵심이다.
3. 이유를 설명하라 (Explain the Why)
1
2
3
4
5
6
7
# Bad — 강압적
ALWAYS use pdfplumber. NEVER use other libraries.
# Good — 이유를 설명
Use pdfplumber for text extraction because it handles
multi-column layouts reliably. Other libraries (pypdf, PyMuPDF)
struggle with complex table structures.
“오늘날의 LLM은 똑똑하다. Theory of Mind가 있으므로 이유를 이해하면 지시사항 없는 엣지 케이스도 올바르게 판단한다.”
4. 반복 작업을 번들링하라 (Bundle Repeated Work)
테스트 실행 트랜스크립트에서 서브에이전트들이 독립적으로 같은 헬퍼 스크립트를 작성한 패턴이 보이면, 그 스크립트를 scripts/에 번들링한다. 매번 휠을 재발명하는 낭비를 방지한다.
6-2. 이터레이션 루프
1
2
3
4
5
1. 스킬 개선 적용
2. 모든 테스트 케이스를 새 iteration-N+1/ 디렉토리에 재실행 (baseline 포함)
3. --previous-workspace로 이전 이터레이션과 비교하는 뷰어 실행
4. 사용자 리뷰 대기
5. 피드백 읽기 → 개선 → 반복
종료 조건:
- 사용자가 만족
- 모든 피드백이 빈 칸 (= 전부 OK)
- 의미 있는 진전이 없을 때
7. Description 최적화 — 트리거 튜닝
7-1. 왜 중요한가
description은 스킬이 자동으로 실행될지를 결정하는 유일한 메커니즘이다. Claude가 사용자 메시지를 받으면, 모든 스킬의 description을 훑어보고 관련 있는 스킬을 선택한다. 마치 서점에서 책의 표지와 띠지만 보고 고르는 것과 같다.
현재 Claude는 과소 트리거(undertrigger) 경향이 있다. 즉, 도움이 될 스킬이 있는데도 사용하지 않는 경우가 많다. Description 최적화는 이 문제를 직접 해결한다.
7-2. 최적화 프로세스
Step 1: 트리거 Eval 쿼리 20개 생성
should-trigger 8~10개 + should-not-trigger 8~10개를 작성한다:
1
2
3
4
5
6
7
8
9
10
[
{
"query": "보스가 Q4 sales final FINAL v2.xlsx 파일을 보냈는데, C열이 매출이고 D열이 비용이래. 이윤율 컬럼 추가해줘",
"should_trigger": true
},
{
"query": "피보나치 함수 작성해줘",
"should_trigger": false
}
]
좋은 쿼리의 특징:
- 현실적이고 구체적 (파일 경로, 회사명, 오타, 캐주얼한 말투)
- should-not-trigger는 근접 실패(near-miss) 위주 — “피보나치”처럼 명백히 무관한 건 테스트 가치가 없음
- 다양한 길이, 톤, 표현 방식
Step 2: HTML 리뷰어로 사용자 확인
생성된 쿼리 세트를 HTML 인터페이스로 보여주고, 사용자가 편집/추가/삭제한 후 export한다.
Step 3: 자동 최적화 루프 실행
1
2
3
4
5
6
python -m scripts.run_loop \
--eval-set eval_set.json \
--skill-path ./my-skill \
--model claude-sonnet-4-6 \
--max-iterations 5 \
--verbose
내부 동작:
- Eval 세트를 60% 학습 / 40% 검증으로 분할
- 각 쿼리를 3회 실행해 신뢰성 있는 트리거율 측정
- Extended Thinking으로 실패 원인 분석 + 개선안 제안
- 최대 5회 반복
- 검증 세트(40%) 점수 기준으로 best description 선택 (오버피팅 방지)
Step 4: 결과 적용
최적화된 description을 SKILL.md 프론트매터에 반영하고, 전후 점수를 확인한다.
7-3. 트리거 메커니즘의 한계
Claude는 간단한 작업에는 스킬을 잘 사용하지 않는다. “이 PDF 읽어줘”처럼 기본 도구만으로 해결 가능한 요청에는, description이 완벽해도 스킬이 트리거되지 않을 수 있다. 복잡하고 다단계인 요청일수록 스킬 트리거 확률이 높다.
따라서 Eval 쿼리도 충분히 복잡한 요청으로 작성해야 의미 있는 테스트가 된다.
8. 스킬 작성 베스트 프랙티스
공식 문서에서 강조하는 핵심 패턴들:
8-1. 자유도 조절
| 상황 | 자유도 | 예시 |
|---|---|---|
| 여러 접근법이 유효할 때 | 높음 | “코드 구조를 분석하고, 잠재적 버그를 확인하고…” |
| 선호 패턴이 있을 때 | 중간 | 파라미터화된 스크립트 템플릿 |
| 작업이 취약하거나 순서가 엄격할 때 | 낮음 | “이 명령을 정확히 실행: python scripts/migrate.py --verify” |
Anthropic의 비유: 절벽 양쪽의 좁은 다리에서는 정확한 가드레일이 필요하지만, 위험 없는 넓은 들판에서는 방향만 가리키고 Claude를 신뢰하라.
8-2. 피드백 루프 패턴
1
실행 → 검증 → 에러 발견 시 수정 → 재검증 → 통과 시 진행
1
2
3
4
5
6
7
8
9
10
## 문서 편집 프로세스
1. `word/document.xml` 수정
2. **즉시 검증**: `python scripts/validate.py unpacked_dir/`
3. 검증 실패 시:
- 에러 메시지 확인
- XML 수정
- 재검증
4. **검증 통과 후에만** 진행
5. 리빌드: `python scripts/pack.py unpacked_dir/ output.docx`
8-3. 파일 참조는 1단계 깊이까지
1
2
3
4
5
6
7
# Good — SKILL.md에서 직접 참조
**기본 사용법**: [여기에 설명]
**고급 기능**: [advanced.md](advanced.md) 참조
**API 레퍼런스**: [reference.md](reference.md) 참조
# Bad — 2단계 이상 중첩
SKILL.md → advanced.md → details.md (Claude가 불완전하게 읽을 수 있음)
9. 플랫폼별 차이점
Skills는 Claude의 여러 플랫폼에서 사용 가능하지만, 환경에 따라 차이가 있다:
| 플랫폼 | 커스텀 스킬 | 프리빌트 스킬 | 서브에이전트 | 네트워크 |
|---|---|---|---|---|
| Claude Code | O (파일시스템) | — | O | 전체 접근 |
| Claude.ai | O (ZIP 업로드) | O (PPTX, XLSX, DOCX, PDF) | X | 설정에 따라 |
| Claude API | O (API 업로드) | O | — | X |
| Agent SDK | O (파일시스템) | — | — | — |
Claude.ai에서의 제한:
- 서브에이전트 없음 → 병렬 평가 불가, 순차 실행
- 블라인드 비교 불가
- Description 최적화 (
run_loop.py) 불가 —claude -pCLI 필요
Claude API에서의 제한:
- 네트워크 접근 없음
- 런타임 패키지 설치 불가 — 사전 설치된 패키지만 사용
10. 실전 활용 가이드 — 처음부터 스킬 만들기
처음 스킬을 만든다면 이 순서를 따라보자:
Step 1: 반복하는 작업 패턴 인식
“이 작업을 할 때마다 같은 설명을 반복하고 있다” → 스킬 후보
Step 2: Claude와 함께 작업 한 번 완수
스킬 없이 Claude에게 직접 작업을 시켜본다. 이 과정에서 자연스럽게 제공하는 컨텍스트, 선호도, 절차적 지식을 관찰한다.
Step 3: Skill Creator로 스킬 생성
1
2
Claude에게: "방금 한 BigQuery 분석 패턴을 스킬로 만들어줘.
테이블 스키마, 네이밍 규칙, 테스트 계정 필터링 규칙을 포함해."
Claude는 스킬 형식과 구조를 기본적으로 이해한다. 특별한 시스템 프롬프트 없이 “스킬 만들어줘”라고 하면 적절한 SKILL.md를 생성한다.
Step 4: 간결성 검토
“이 설명 Claude가 꼭 필요한가?” → 불필요한 설명 제거
Step 5: 테스트 및 반복
새 인스턴스(Claude B)에서 스킬을 사용해 실제 작업을 수행하고, 관찰 결과를 원래 인스턴스(Claude A)에 피드백한다:
1
2
"Claude B가 지역별 매출 리포트를 작성했는데, 테스트 계정 필터링을 빼먹었어.
스킬에 언급은 되어있는데 눈에 잘 안 띄나 봐."
Step 6: 팀 피드백 반영
팀원에게 스킬을 공유하고 사용 패턴을 관찰한다:
- 스킬이 기대한 시점에 트리거되는가?
- 지시사항이 명확한가?
- 빠진 것은 없는가?
마무리
Skills 2.0의 핵심은 “스킬도 소프트웨어처럼 테스트하고 관리하라”는 것이다.
| 기존 | Skills 2.0 |
|---|---|
| SKILL.md에 지시사항 작성 | 4가지 모드(Create·Eval·Improve·Benchmark) |
| 트리거 여부를 감으로 판단 | 자동 최적화 루프 + 수치 기반 판단 |
| 스킬이 좋은지 나쁜지 주관적 평가 | A/B 테스트 + 블라인드 비교 + 통계 리포트 |
| 모델 업그레이드 시 기도 | 벤치마킹으로 회귀 검출 + 폐기 판단 |
| 프론트매터는 name/description만 | context, model, effort, hooks, agent 등 정교한 제어 |
스킬 하나를 잘 만들어두면 수천, 수만 번의 반복 작업에서 일관된 품질을 보장받을 수 있다. 그리고 이제 그 “잘 만들어두는” 과정 자체가 자동화되었다.
참고 자료: