
Unity Profiler 最適化

目次
- 1. Unity Profiler の構成
- 2. Profiler のスレッド
- 3. Sample Stack と Call Stack
- 4. Marker について
- 5. ボトルネックを探す
- 6. Graphics Batching
Unity Profiler
- Editor 環境または Development Build で手軽に最適化を進められるツール。
Unity Profiler の構成
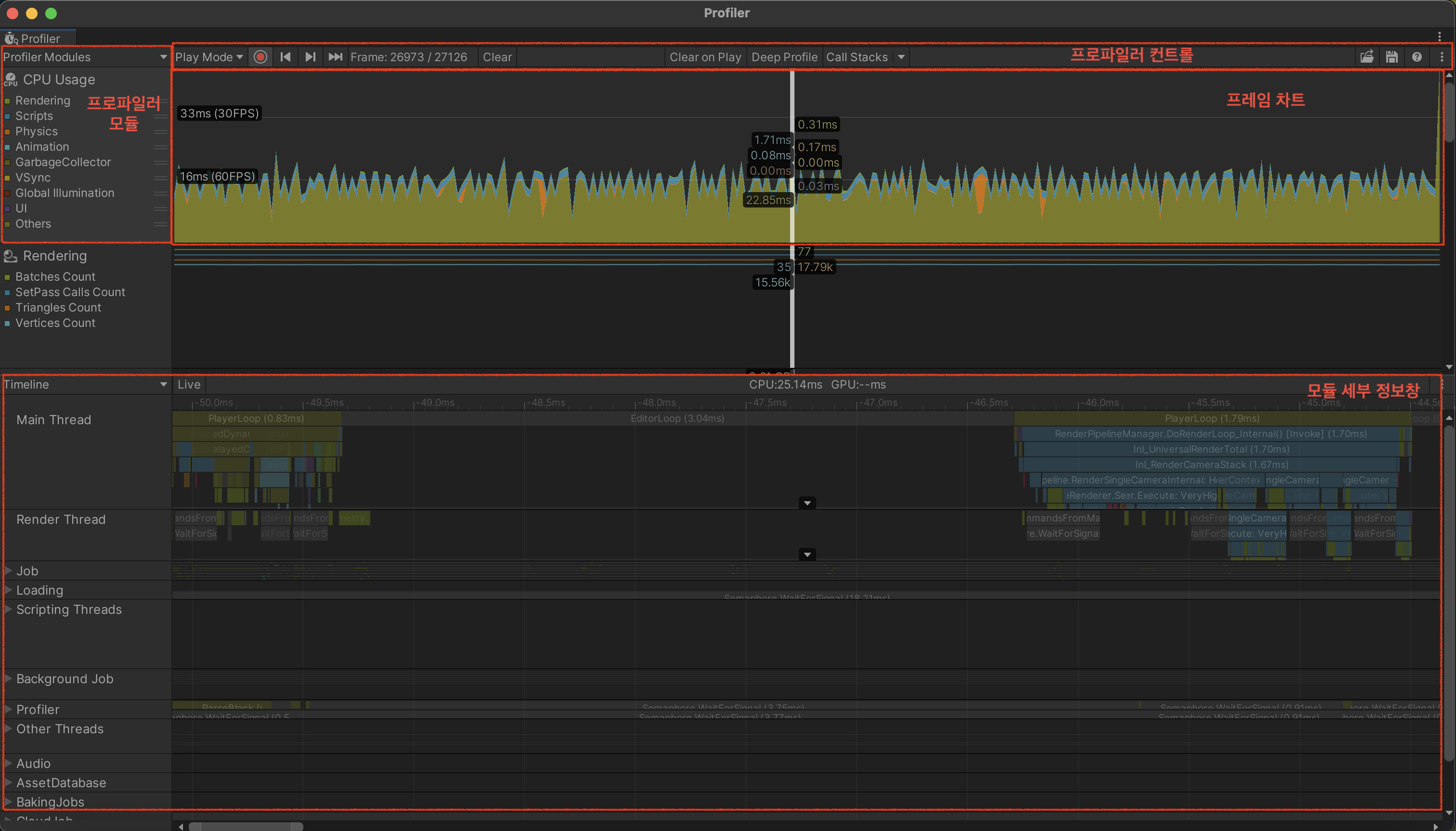
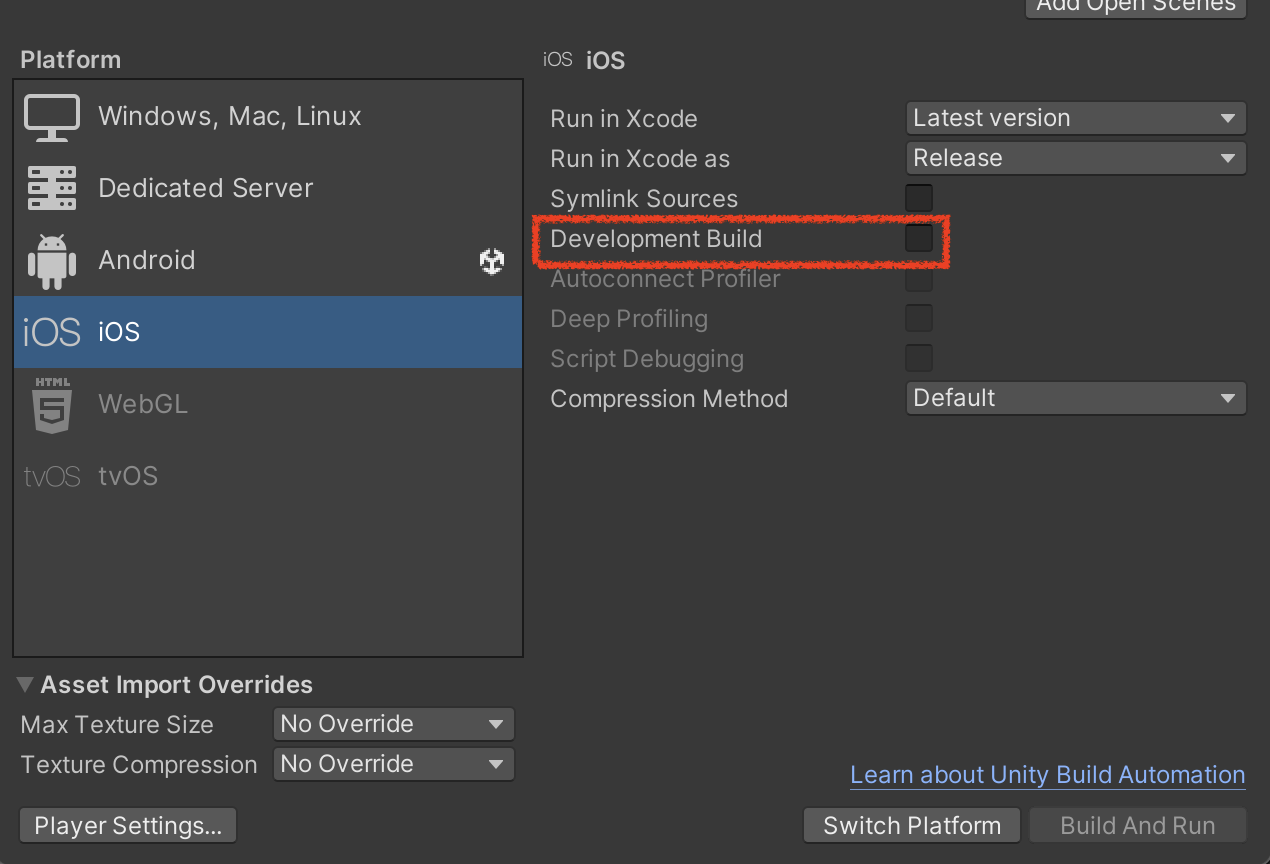
Development Build オプションを有効にする
- 追加オプションの多くは不要。主に Profiler 自動接続や Deep Profiling を支援する。
- ただし自動接続はビルド時にその PC の IP を焼き込むため、ビルドした PC からのみ自動接続できる。
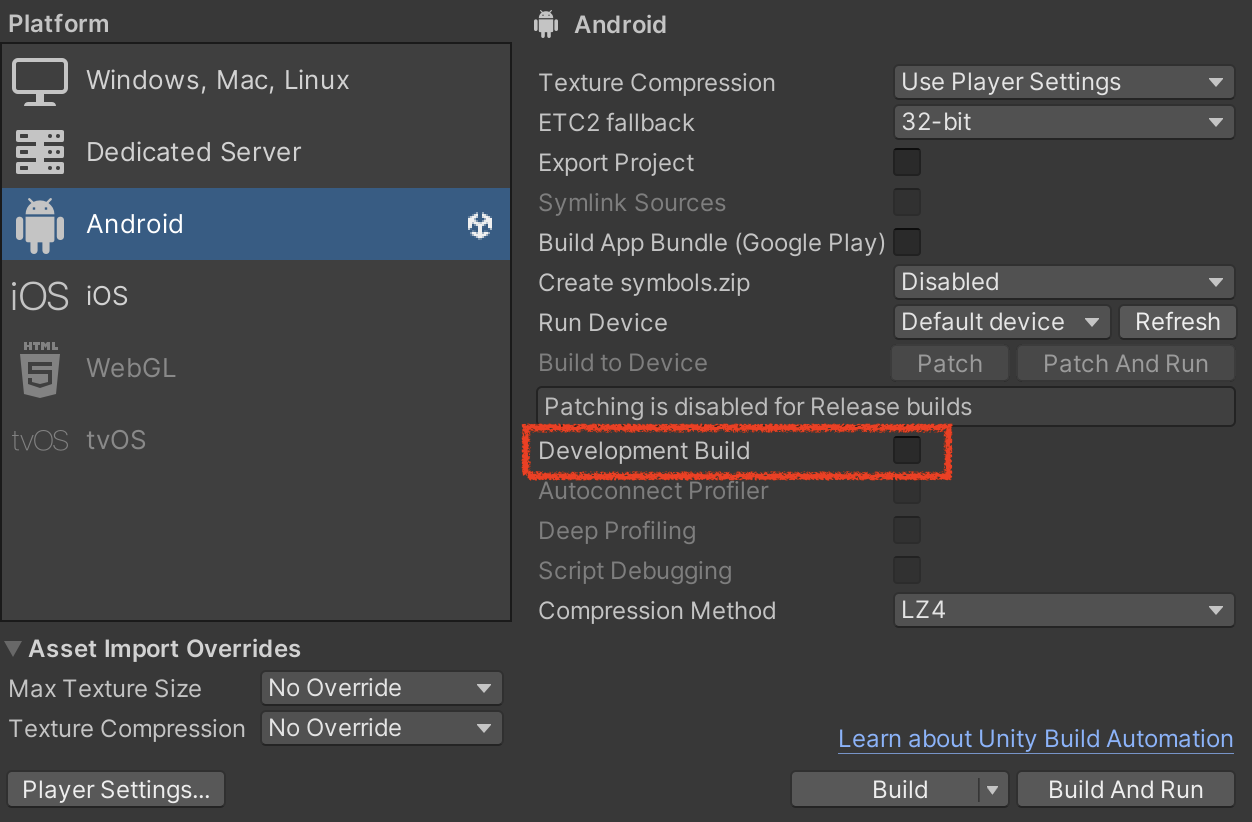
Profiler - CPU モジュール
- Sample 単位で確認できる。
- 各処理がどれだけ CPU 時間を消費しているか確認可能。
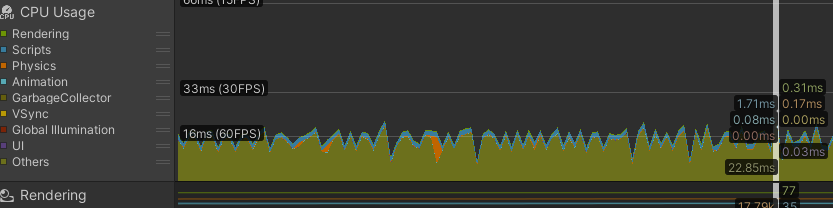
Profiler - Chart ビュー
- プロジェクトの目標 FPS より速く処理できているか確認する。60fps なら多くの処理は 16ms 以内、30fps なら 33ms 以内が目安。
- グラフの過負荷スパイクが起きていないか確認する。
- VSync が ON だとチャートが実質 60fps / 16ms に張り付きやすい。プロファイリング時は VSync を OFF にする。
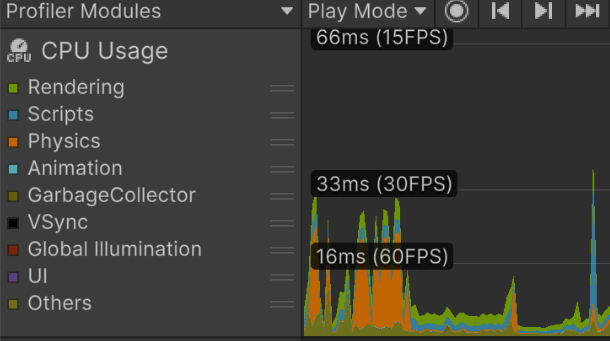
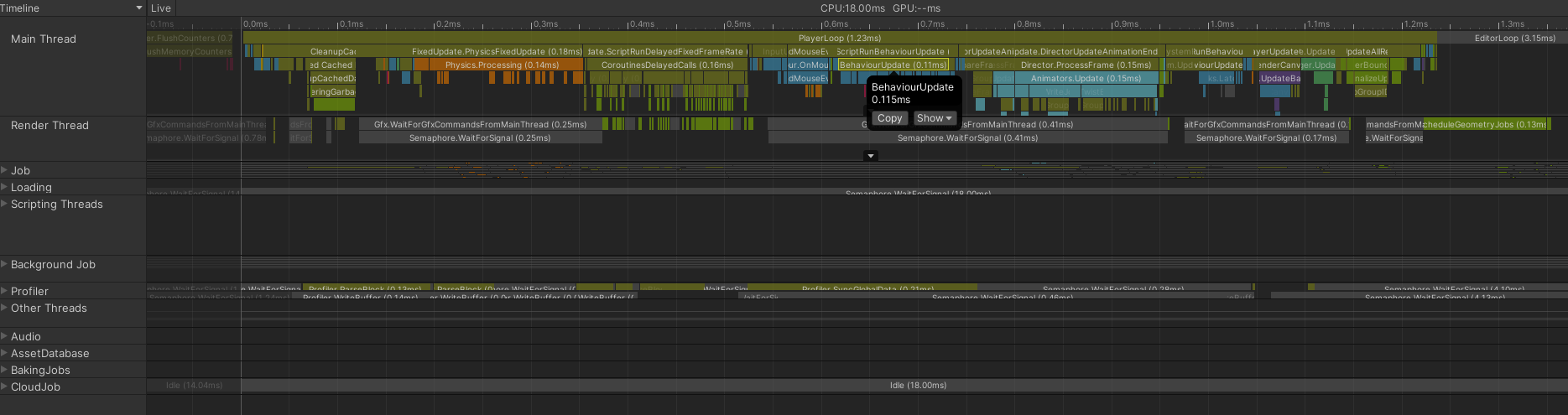
Profiler - 詳細ウィンドウ、Timeline ビュー
- CPU 使用時間を直感的に把握できる。
- 全スレッドを一目で確認できる。
- 関数のタイミングと実行順序の関係を線形に追える。
Profiler - 詳細ウィンドウ、Hierarchy ビュー
- 親子の呼び出し関係を把握できる。
- 見たい指標でソート可能。
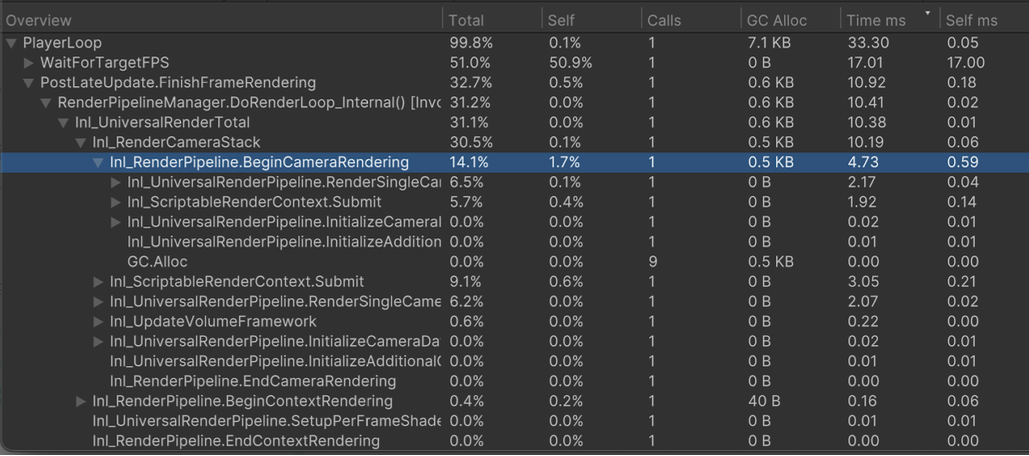
- まずは実行時間が長い Sample から順に改善すればよい。
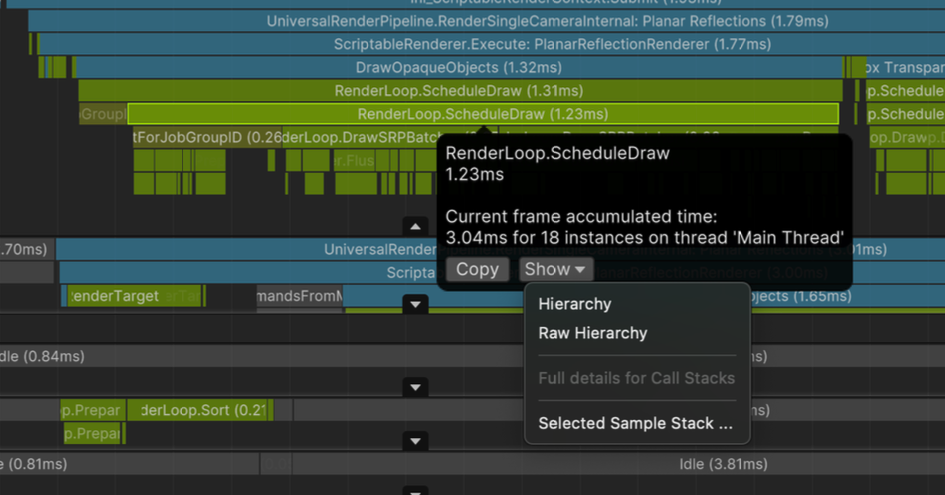
Profiler - スレッド
- Main Thread
- Unity Player Loop (
Awake,Startなど) が実行される MonoBehaviourスクリプトが一次的にここで動作する
- Unity Player Loop (
- Render Thread
- GPU へ送るコマンドを組み立てるスレッド
実際には Main Thread 側で Draw Call が発生し、Render Thread 側で実行用コマンドが組み立てられる
- GPU へ送るコマンドを組み立てるスレッド
- Worker Thread (Job Thread)
- Job System などによる非同期並列処理
- アニメーション/物理など計算負荷が高い処理がここで実行される
Main Thread で Job を予約し、Worker Thread で処理する
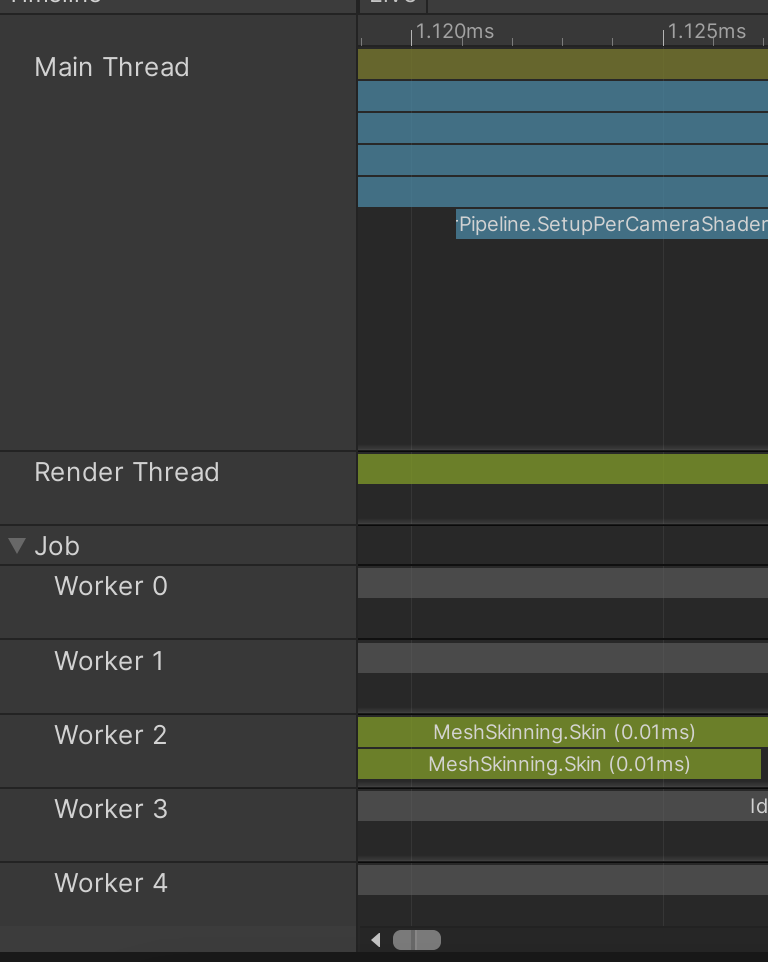
- 異なるスレッド間では、直接呼び合っていないメソッドでも因果関係がある。
ex1. Job 予約 > Worker Thread で処理
ex2. Main Thread のMeshRenderer.Draw()実行 > Render Thread で Graphics コマンド組み立て
Main Thread が遅れると Render Thread が遊ぶ場合がある。
Show Flow Eventsを有効化すると、実行順序と因果関係を確認できる。
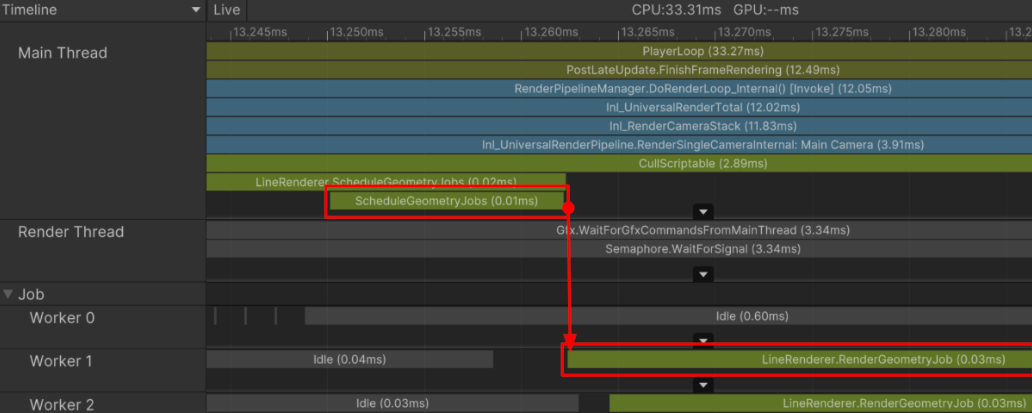
Sample Stack と Call Stack の違い

- Sample Stack と Call Stack には差がある。Sample Stack はチャンク単位で整理され、マークされた C# メソッド/コードブロックだけを対象にする。
- このためサンプリングが大きくひとかたまりになる。Unity は全 C# 呼び出しを取るのではなく、マーク済みの主要処理を中心にサンプリングする。
Deep Profiling 時の注意
Deep Profiling では、コンストラクタ/プロパティを含む全 C# 呼び出しがマークされる。
プロファイリング自体のオーバーヘッドが過大になり、データが不正確になることがある。
- そのため Deep Profiling は、限定スコープ・短時間で使うのを推奨。
Call Stack を有効にする方法
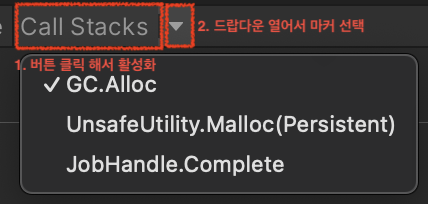
- まず Call Stack ボタンを押して有効化する(ハイライト表示)。
- Call Stack ドロップダウンで、記録したい Marker を選ぶ。

- 特定 Sample については、Call Stack 全体を記録できる。
GC.Alloc: 動的割り当てが発生した場合UnsafeUtility.Malloc: 手動解放が必要な unmanaged 割り当てJobHandle.Complete: Main Thread が Job を強制同期完了した場合
- 常用は推奨せず、限定用途で使う。
Marker について
1. Main Loop Marker
PlayerLoop: Player Loop に沿って実行される Sample 群のルートBehaviourUpdate:Update()Sample 群のホルダーFixedBehaviourUpdate:FixedUpdate()Sample 群のホルダーEditorLoop: Editor 専用ループ
2. Graphics Marker (Main Thread)
WaitForTargetFPSVSync / 目標フレームレート待機時間
Gfx.WaitForPresentOnGfxThreadRender Thread が GPU 待機状態で、Main Thread 側も待機が発生する時の Marker
Gfx.PresentFrameGPU が現在フレームを描画するのを待つ
長い場合は GPU 側処理が遅いGPU.WaitForCommandsRender Thread は新規コマンド受け取り準備完了だが、Main Thread からコマンド供給が追いつかず待機している状態
ボトルネックを探す
- Graphics Marker は GPU / CPU bound 判定に有効。
- Main Thread が Render Thread 待ちの場合、Main 側での詰まりやスレッド間受け渡しを疑う。Render コマンドは後段の Player Loop で組み立てられる。
- つまり単純な GPU/CPU 判定だけでなく、スレッド間ボトルネックを確認する必要がある。
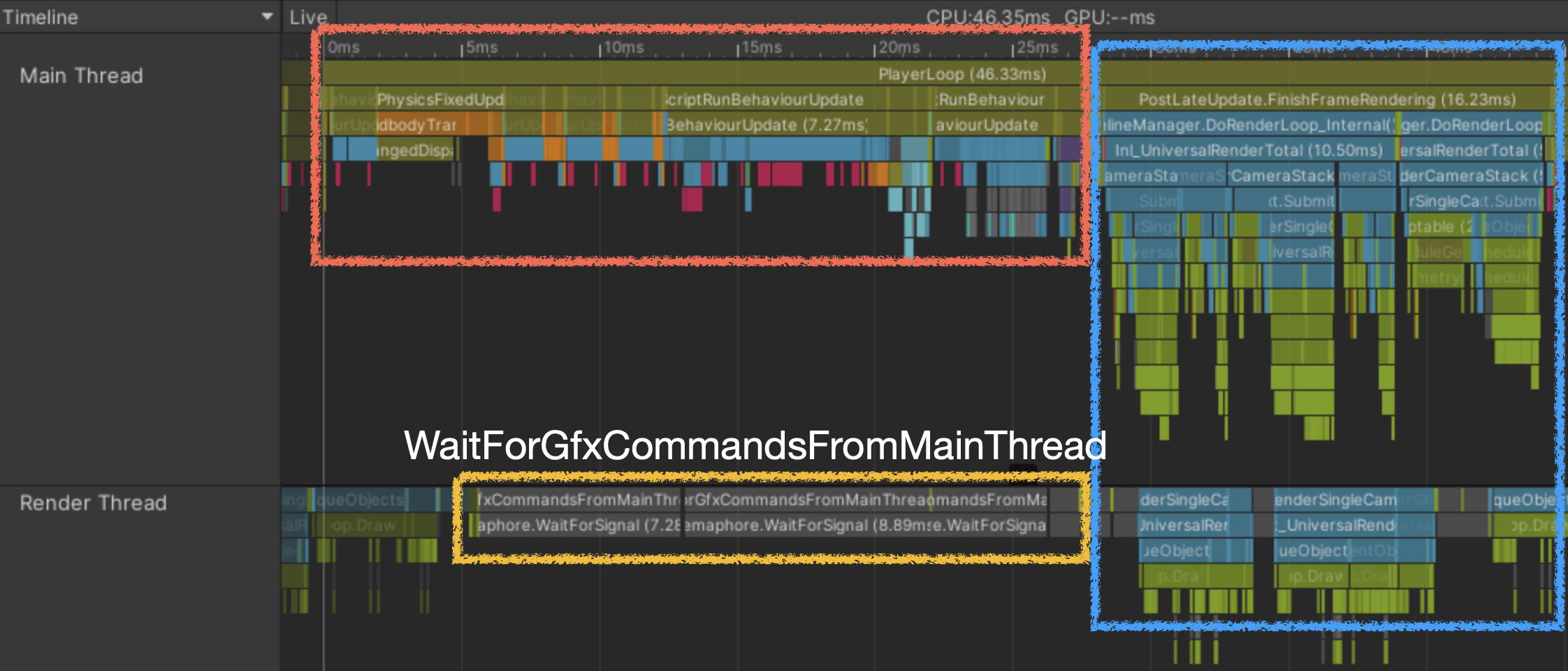
- CPU Main Thread bound
Main Thread の処理遅延で Render Thread が待機
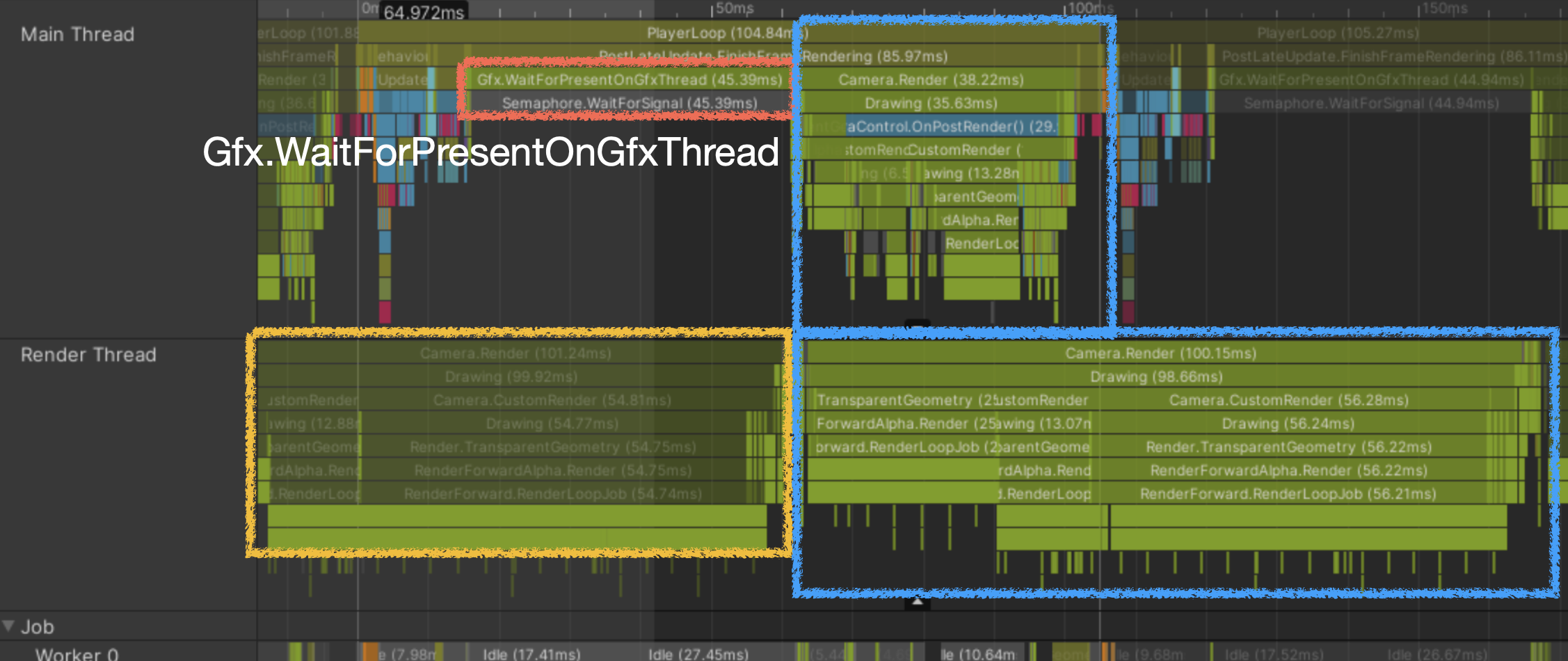
- Render Thread bound
直前フレーム分の Draw Call コマンド送信がまだ続いている
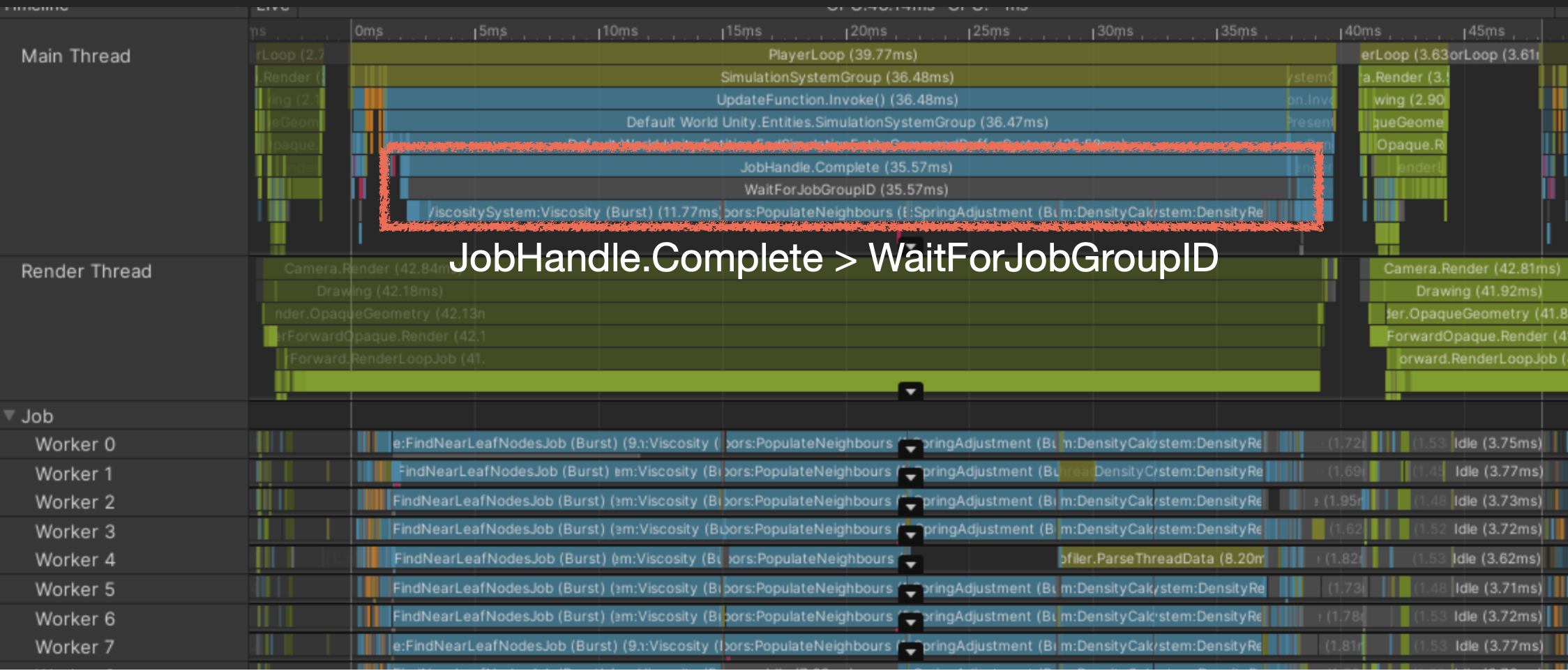
- Worker Thread bound
Job 完了を同期で待っている
- Xcode Frame Debugger や 2023 以降の Profiler は CPU/GPU bound を可視化してくれる。
ボトルネックは大きく 4 種類
- CPU Main Thread bound
- CPU Worker Thread bound (物理、アニメーション、Job System)
- CPU Render Thread bound (GPU そのものではなく、CPU でのコマンド組み立て/転送の詰まり)
- GPU bound
- ボトルネック特定の流れ
Main Thread ボトルネックか? -> Player Loop 最適化
違うなら物理/アニメーション/Job System を重点確認
それでも違うなら Render Thread を調べ、さらに GPU 要因か CPU 要因かを切り分ける
- Render Thread の CPU ボトルネックの場合
- CPU Graphics 最適化
Camera / Culling 最適化
SetPass Call 削減 (batching)
可能な batch 手法: SRP batching, Dynamic batching, Static batching, GPU instancing
汎用的な事実
- Batching の前に押さえるべき点。
- Graphics 処理遅延の要因は複数ある。
最近は GPU 性能不足というより、CPU 側のコマンド組み立て遅延で GPU を十分活かせないケースが多い
CPU->GPU へのコマンド/リソースアップロード遅延
GPU 内部処理の遅延 - Draw Call は CPU から GPU へレンダリング実行命令を送ること。
Draw Call 自体より、Render State 変更時の CPU コスト/アップロード遅延が重いことが多い。
- 高コストになりやすいのは「描画命令直前」。
- GPU は小さいメッシュ多数より、大きいメッシュをまとめて描く方が得意。
- 多くのレンダリング問題は GPU 計算性能不足ではなく、GPU 利用効率の低さに起因する。
小さいメッシュを大量送信すると GPU の実行単位 (Wavefront/Warp) を無駄にする。
例: 1 単位 256 頂点処理なのに 128 頂点単位で送ると無駄が出る。
Graphics Batching
1. SRP Batching (URP, HDRP)
- Draw 命令そのものより、その前段で毎回異なる Render State (異なる Shader) をセットアップするコストの方が大きい。
- 同一 Shader & Material を使うメッシュをまとめる
- 1 つの SetPass Call (同一 Shader Variant) の下に複数 Draw Call を束ねる
- Material ごとのデータ: 巨大リストに入れて初期アップロード
- Object ごとのデータ: 巨大リストに入れて毎フレームアップロード
- Index/Offset でリストからメッシュを指定して
Draw() - プロジェクトで使う Shader 種類を減らすと最適化しやすい。
2. Static Batching (Static)
- GPU は大きなメッシュを一括で描くのが得意。コンセプトは転送量削減。
- 動かないメッシュを事前結合して Bake -> 先に GPU へアップロード -> 各 Renderer で
DrawIndexed()呼び出し - CPU/GPU ともに高速
- Unity Editor がアプリビルド時にのみ Bake
- 欠点: 既存メッシュを結合してユニークメッシュを作るためメモリ使用量が増える
3. Dynamic Batching (Dynamic)
- GPU は大きなメッシュを一括で描くのが得意。コンセプトは転送量削減。 -> あまり推奨しない。
- 毎フレームメッシュを結合 >
Draw()を 1 回実行 - GPU 観点では最適化
GPU が受け取るのは 1 メッシュ/1 Draw 命令なので高速
- ただし CPU は毎フレーム結合処理が必要
Draw 命令は減るが、結合工程で性能を消費
- 毎フレーム Bake
Draw Call 多発より、結合処理の方が重くなる場合がある
4. GPU Instancing
- CPU から GPU への命令伝達を節約する。
- 同一メッシュに完全同一 Shader/Material を使う場合
- メッシュデータを GPU に 1 回だけアップロード
インスタンスごとの固有データ (Object to World 行列) は配列で渡す
- 同一オブジェクトを大量描画する時、CPU 側が非常に速い
- (500 未満)頂点数が小さすぎるメッシュは効率が下がる
GPU は大きなメッシュ描画の方が効率的。頂点 256 以下メッシュは効果が薄いことがある。
まとめ
- 一般的な効率: SRP Batching, Static Batching > GPU Instancing > Dynamic Batching
- Draw Call より、直前の Render State Setup の方が CPU コストが大きくなりやすい
- Draw Call 最適化も重要だが、まず SetPass Call 削減 (SRP Batching) に集中するのが有効
- Draw Call 削減 (Instancing / Dynamic) より先に、SRP Batching 有効化と Shader 種類削減が最も効果的
SRP Batching を ON にして Shader 種類を減らすのが高効果。
SetPass Call を減らそう!!
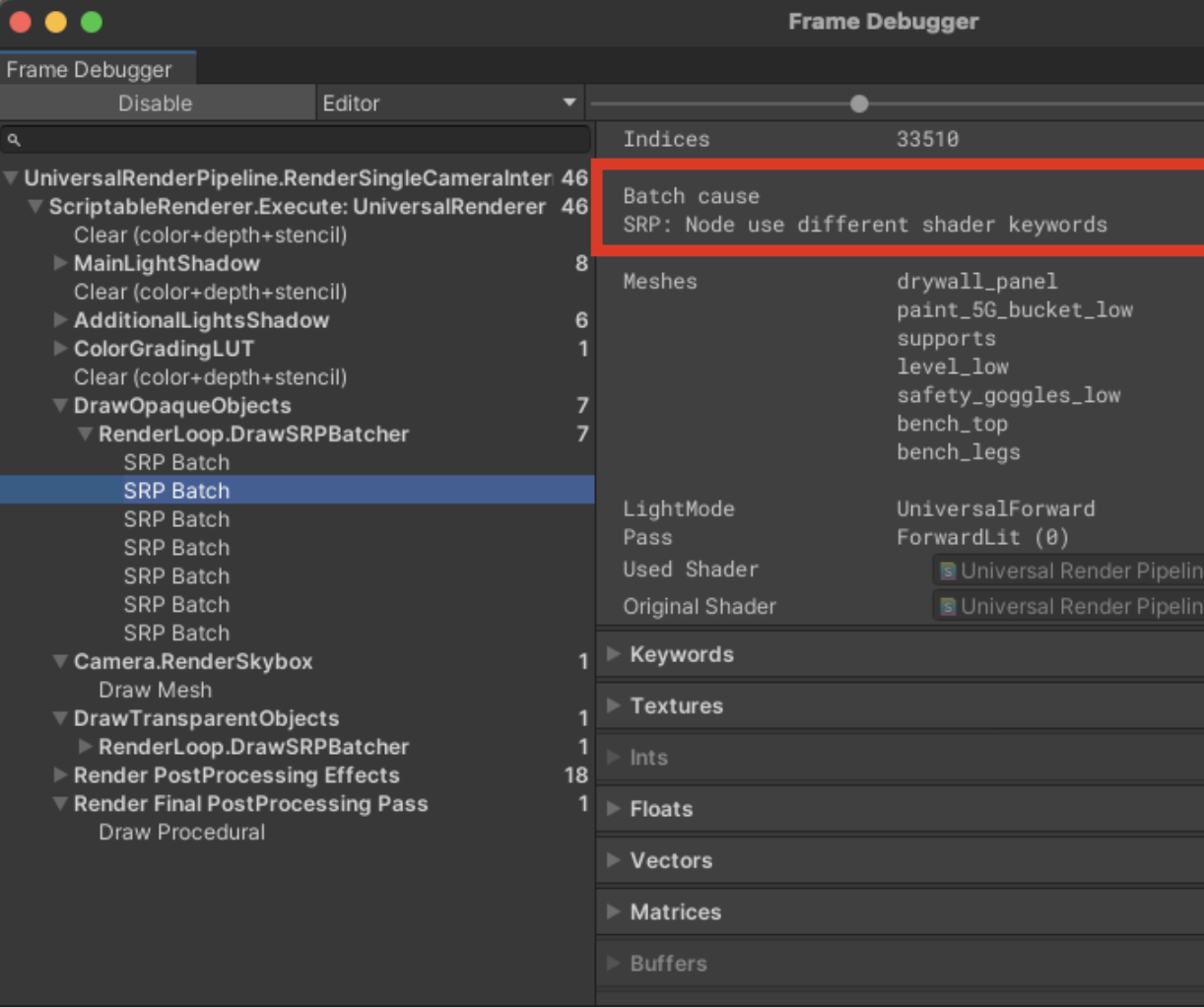
- Frame Debugger で SetPass Call が統合されない理由を確認できる。
- SetPass Call 300 未満を目標に設定。
GPU レンダリングがボトルネックの場合
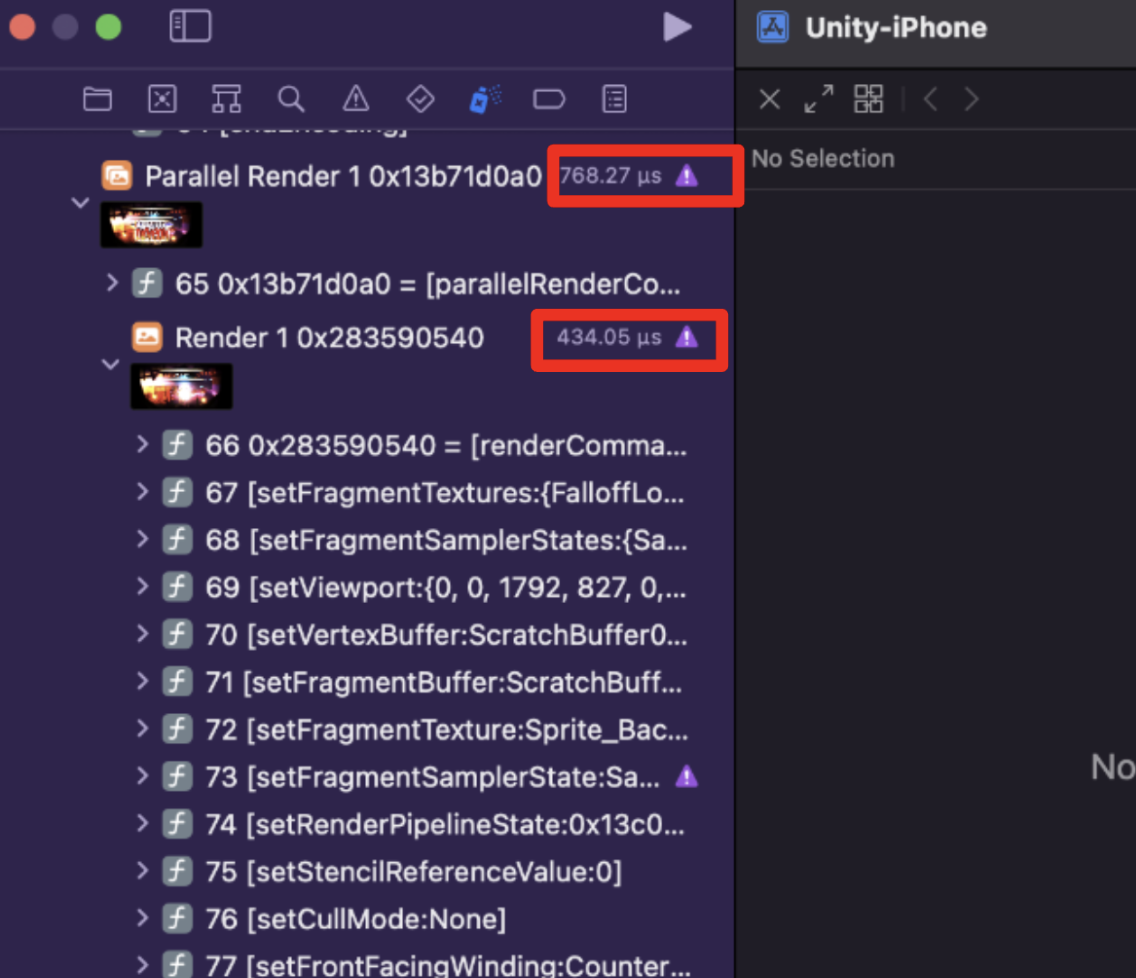
- Xcode GPU Frame Capture
- コマンドが時系列で並ぶため、各レンダリング段階の時間消費を確認できる。
- 異常に時間を使う Draw を見つけ、該当 Draw が使う Shader / Mesh を特定して最適化する。
- Reference
李済民 (Retro Unity パートナーシップエンジニア) 氏の講義で得た内容。
IJEMIN GitHub