
AGENTS.mdは本当に役に立つのか? — コーディングエージェントのコンテキストファイルの有効性を検証した論文分析

- ゲーム開発者のAI活用術:2,165メッセージの記録から見る実戦データ(47日間の記録)
- Claude Opus 4.5 → 4.6 移行期 - ゲーム開発者が体感した性能、トークン、ワークフローの変化
- AGENTS.mdは本当に役に立つのか? — コーディングエージェントのコンテキストファイルの有効性を検証した論文分析
- Claudeメモリ無料開放と/simplify、/batch — そしてCLAUDE.mdの隠れたコスト
- WindowsでClaude Codeをインストールする完全ガイド — 実践トラブルシューティング付き
- ゲームプランナーのためのClaude Code完全活用ガイド — 仕様書からバランシングまで
- macOSでClaude Code C# LSPを完全セットアップするガイド — csharp-lsのインストールからトラブルシューティングまで
- C# LSP vs JetBrains MCP トークン効率分析 — Claude Codeで最適なツール選択戦略
- AGENTS.mdやCLAUDE.mdのようなコンテキストファイルは6万以上のレポジトリで採用されているが、LLMが自動生成したコンテキストファイルは性能をむしろ低下させ、コストを20%以上増加させる。
- 主な原因は既存ドキュメントとの情報の重複。ドキュメントを削除するとコンテキストファイルが+2.7%の性能向上を示し、情報過多が問題であることが立証された。
- 開発者が直接作成した最小限のコンテキストファイルのみがわずかな効果を示し、一般的なコードベースの概要よりも具体的なツールの要件の方が有用である。

はじめに
Claude Codeを使用する際、CLAUDE.mdを作成することは、今やほぼデフォルトのワークフローとして定着しています。OpenAIのCodexはAGENTS.mdを、AnthropicのClaude CodeはCLAUDE.mdを推奨しており、これらのコンテキストファイルは現在、6万以上のオープンソースレポジトリで採用されています。
しかし、これらのファイルは本当にエージェントの性能を高めてくれるのでしょうか?チューリッヒ工科大学(ETH Zurich)とAnthropicの研究チームが、この問いに対して初の大規模な実証研究を行いました。その結果は、業界の通説とはかなり異なるものでした。
論文: “Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?” 著者: Thibaud Gloaguen, Niels Mündler, Mark Müller, Veselin Raychev, Martin Vechev (ETH Zurich / Anthropic) arXiv: 2602.11988
1. 背景:コンテキストファイルとは?
コーディングエージェント用のコンテキストファイルは、レポジトリのルートに位置するMarkdownファイルで、エージェントにプロジェクトの構造、ビルド方法、コーディング規則などを伝える役割を果たします。
| エージェント | ファイル名 | 開発元 |
|---|---|---|
| Claude Code | CLAUDE.md | Anthropic |
| Codex | AGENTS.md | OpenAI |
| Cursor | .cursorrules | Cursor |
| Windsurf | .windsurfrules | Codeium |
これらのファイルの一般的な構成:
- コードベースの概要: ディレクトリ構造、主要モジュールの説明
- ビルド/テストコマンド:
npm test、bundle exec jekyll serveなど - コーディング規約: 命名規則、スタイルガイド
- プロジェクト固有の特殊要件: 特定のツールの使用、注意事項
業界では、このようなファイルを作成することでエージェントがプロジェクトをより深く理解し、正確なコードを生成することが期待されてきました。しかし、実際はどうなのでしょうか?
2. 実験設計
2-1. 評価パイプライン
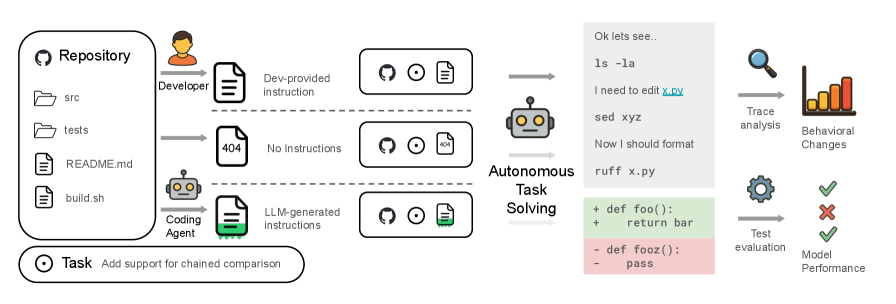 Figure 1. 評価パイプラインの概要。3つの条件(開発者が作成したコンテキスト / コンテキストなし / LLMが生成したコンテキスト)でエージェントがタスクを解決し、生成されたパッチをユニットテストで評価する。
Figure 1. 評価パイプラインの概要。3つの条件(開発者が作成したコンテキスト / コンテキストなし / LLMが生成したコンテキスト)でエージェントがタスクを解決し、生成されたパッチをユニットテストで評価する。
研究チームは、以下の3つの条件を比較しました:
- None — コンテキストファイルなしで作業
- LLM — LLMが自動生成したコンテキストファイルを提供
- Human — 開発者が直接作成したコンテキストファイルを提供
2-2. ベンチマーク
SWE-bench Lite (既存のベンチマーク)
- 11の有名なPythonレポジトリから300のタスク
- Django、scikit-learn、sympyなどのよく知られたプロジェクト
- もともとコンテキストファイルが存在しないため、None vs LLMのみを比較可能
AGENTbench (この論文で新たに作成)
- 開発者が作成したコンテキストファイルが実際に存在する12のニッチなPythonレポジトリから138のインスタンス
- None、LLM、Humanの3つの条件すべてを比較可能
- 5,694件のPRから厳選して構成
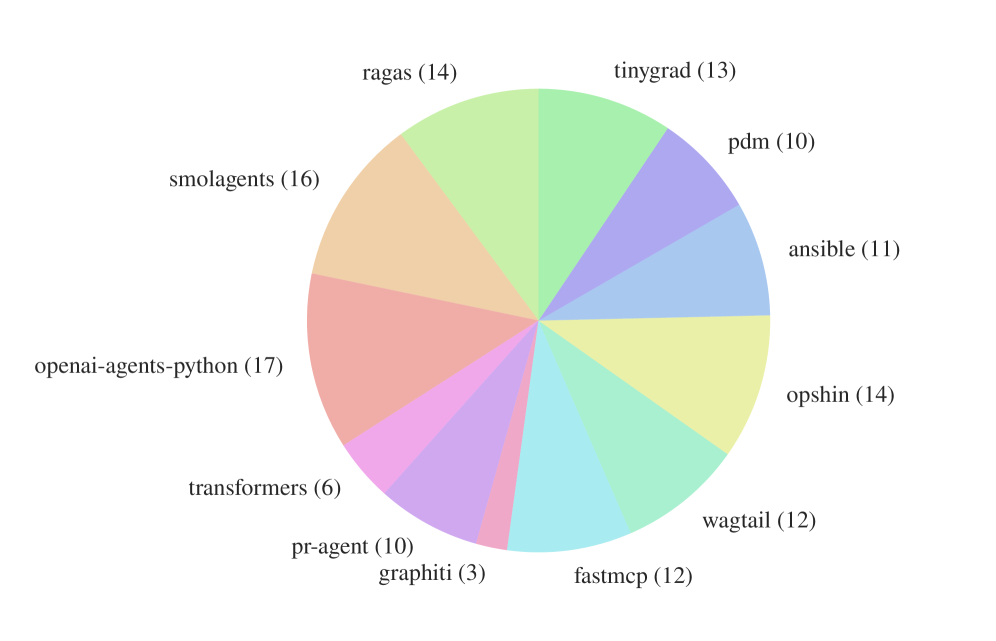 Figure 2. AGENTbenchのインスタンスが12のオープンソースレポジトリにわたって分布している様子。SWE-benchに比べ、特定のレポジトリに偏ることなく、より均等に分布している。
Figure 2. AGENTbenchのインスタンスが12のオープンソースレポジトリにわたって分布している様子。SWE-benchに比べ、特定のレポジトリに偏ることなく、より均等に分布している。
AGENTbench の統計
| 指標 | 平均 | 最小 | 最大 |
|---|---|---|---|
| PR本文の長さ (単語数) | 415.3 | 5 | 4,961 |
| Issueの説明 (単語数) | 211.6 | 96 | 500 |
| コードベースのファイル数 | 3,337 | 151 | 26,602 |
| PRパッチの行数 | 118.9 | 12 | 1,973 |
| 修正ファイル数 | 2.5 | 1 | 23 |
| テストカバレッジ | 75% | 2.5% | 100% |
| コンテキストファイルの長さ (単語数) | 641.0 | 24 | 2,003 |
| コンテキストファイルのセクション数 | 9.7 | 1 | 29 |
2-3. テストされたエージェント
| エージェント | モデル | 開発元 |
|---|---|---|
| Claude Code | Sonnet-4.5 | Anthropic |
| Codex | GPT-5.2 | OpenAI |
| Codex | GPT-5.1 mini | OpenAI |
| Qwen Code | Qwen3-30b-coder | Alibaba |
4つの主要なコーディングエージェントを2つのベンチマーク、3つの条件で評価し、計20の実験の組み合わせをテストしました。
3. 主要な結果:コンテキストファイルのパラドックス
3-1. 性能への影響
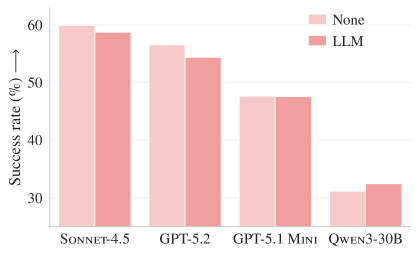 Figure 3a. SWE-bench Liteにおける解決率。4つのモデルすべてにおいて、LLMが生成したコンテキストファイル(オレンジ)は、コンテキストなし(青)と同等か、それ以下の成功率を示している。
Figure 3a. SWE-bench Liteにおける解決率。4つのモデルすべてにおいて、LLMが生成したコンテキストファイル(オレンジ)は、コンテキストなし(青)と同等か、それ以下の成功率を示している。
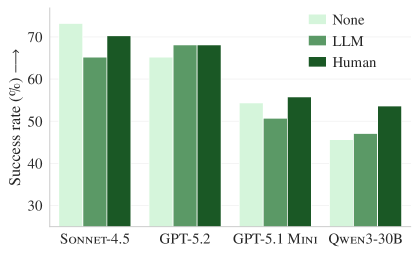 Figure 3b. AGENTbenchにおける解決率。開発者が作成したコンテキスト(緑)はわずかな改善を示しているが、LLMが生成したコンテキスト(オレンジ)は依然として性能を低下させている。
Figure 3b. AGENTbenchにおける解決率。開発者が作成したコンテキスト(緑)はわずかな改善を示しているが、LLMが生成したコンテキスト(オレンジ)は依然として性能を低下させている。
結果の要約:
| 条件 | SWE-bench Lite | AGENTbench |
|---|---|---|
| LLM生成コンテキスト | -0.5% 成功率 ↓ | -2% 成功率 ↓ |
| 開発者作成コンテキスト | (テスト不可) | +4% 成功率 ↑ |
LLMが自動生成したコンテキストファイルは、両方のベンチマークで性能を低下させました。 開発者が直接作成したファイルも、改善の幅はごくわずかでした。この結果は、業界の「コンテキストファイルを必ず作成せよ」という推奨と真っ向から対立するものです。
3-2. コストは確実に増加
一方で、コストは確実に増加しました。
| モデル | データセット | None コスト | LLM コスト | Human コスト |
|---|---|---|---|---|
| Sonnet-4.5 | SWE-bench | $1.30 | $1.51 (+16%) | — |
| GPT-5.2 | SWE-bench | $0.32 | $0.43 (+34%) | — |
| Sonnet-4.5 | AGENTbench | $1.15 | $1.33 (+16%) | $1.30 (+13%) |
| GPT-5.2 | AGENTbench | $0.38 | $0.57 (+50%) | $0.54 (+42%) |
| GPT-5.1 mini | AGENTbench | $0.18 | $0.20 (+11%) | $0.19 (+6%) |
| Qwen3-30b | AGENTbench | $0.13 | $0.15 (+15%) | $0.15 (+15%) |
平均20%以上のコスト増加。しかし、それに見合う性能の向上はありませんでした。つまり、コンテキストファイルは費用対効果がマイナスであると言えます。
4. なぜコンテキストファイルは有害なのか?
4-1. 既存ドキュメントとの情報の重複
これが論文の最も核心的な発見です。
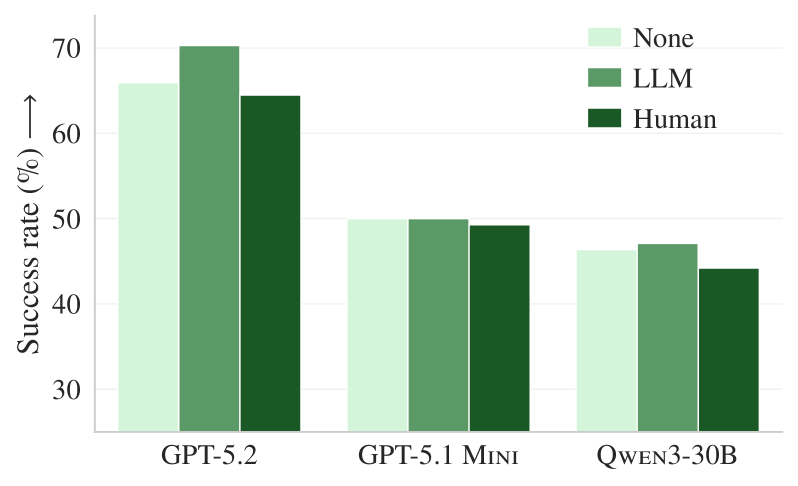 Figure 5. 既存のドキュメントを削除した後のAGENTbenchの結果。ドキュメントがないとき、LLM生成のコンテキストファイル(オレンジ)は平均+2.7%の性能向上を示し、開発者が作成したファイル(緑)よりも高い成果を出している。
Figure 5. 既存のドキュメントを削除した後のAGENTbenchの結果。ドキュメントがないとき、LLM生成のコンテキストファイル(オレンジ)は平均+2.7%の性能向上を示し、開発者が作成したファイル(緑)よりも高い成果を出している。
研究チームは、レポジトリから .md ファイル、サンプルコード、 docs/ フォルダをすべて削除した状態で再度実験を行いました。その結果:
- ドキュメントがあるとき:LLMコンテキストファイルは -2% の性能低下
- ドキュメントを削除すると:LLMコンテキストファイルは +2.7% の性能向上
これは、LLMが生成するコンテキストファイルが、すでにレポジトリに存在する README やドキュメントなどとほぼ同じ情報を含んでいることを立証しています。重複した情報がエージェントを混乱させているのです。
ゲーム開発に例えるなら、同じテクスチャを異なる名前で2回ロードするようなものです。メモリを浪費するだけで、レンダリングの品質は上がりません。
4-2. ファイル発見速度の改善なし
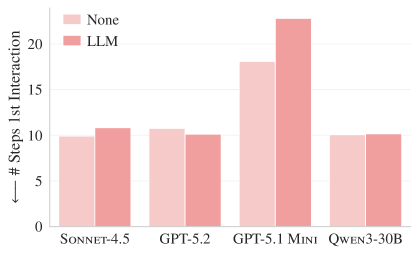 Figure 4a. SWE-bench Liteで、エージェントが関連ファイルと最初に相互作用するまでのステップ数。
Figure 4a. SWE-bench Liteで、エージェントが関連ファイルと最初に相互作用するまでのステップ数。
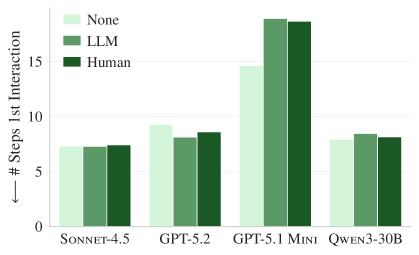 Figure 4b. AGENTbenchでも同様のパターン。コンテキストファイルがあっても、関連ファイルをより早く見つけることはできない。
Figure 4b. AGENTbenchでも同様のパターン。コンテキストファイルがあっても、関連ファイルをより早く見つけることはできない。
コンテキストファイルにコードベースの概要があれば、エージェントが関連ファイルをより早く見つけられると期待されますが、実際にはコンテキストファイルの有無にかかわらず 15〜25 ステップを要しました。コードベースの概要は、ファイルの探索効率に寄与していないということです。
4-3. ツール使用は増えるが、正確度はそのまま
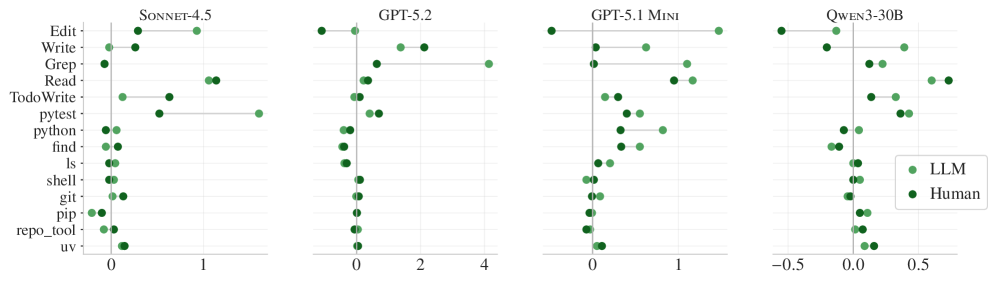 Figure 6. コンテキストファイルを含めたときの平均的なツール使用の増加量。grep、テスト、ファイル読み込みなど、ほぼすべてのツール使用が増加するが、成功率は上がらない。
Figure 6. コンテキストファイルを含めたときの平均的なツール使用の増加量。grep、テスト、ファイル読み込みなど、ほぼすべてのツール使用が増加するが、成功率は上がらない。
コンテキストファイルがあるときのエージェントの行動の変化:
- grep の使用: +30〜50% 増加
- テストの実行: +40〜100% 増加
- レポジトリ固有のツール: コンテキストファイルに言及されると 2.5倍 多く使用される
- パッケージマネージャー (uvなど): 言及されると 1.6倍 多く使用される
エージェントはコンテキストファイルの指示を忠実に守ります。問題は、その指示に従うことがより良い結果に繋がらないという点です。より多く検索し、より多くテストするが、正解には近づかない。一種の「勤勉な非効率」と言えるでしょう。
4-4. 推論トークンの消費増加
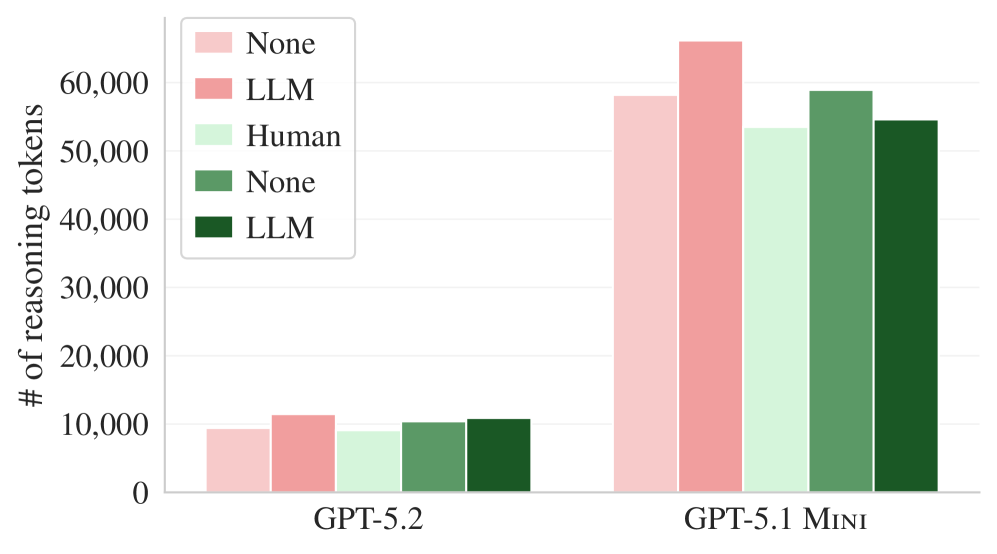 Figure 7. GPT-5.2 と GPT-5.1 mini の平均推論トークン使用量。コンテキストファイルがあると、推論により多くのトークンを消費する。
Figure 7. GPT-5.2 と GPT-5.1 mini の平均推論トークン使用量。コンテキストファイルがあると、推論により多くのトークンを消費する。
| モデル | LLMコンテキスト時の推論トークン増加 | Humanコンテキスト時の推論トークン増加 |
|---|---|---|
| GPT-5.2 | +22% | +20% |
| GPT-5.1 mini | +14% | +2% |
エージェントがコンテキストファイルを処理し、その指示事項を推論に反映させるために、より多くのトークンを消費します。しかし、この追加の推論がより良い結果に結びつかないため、純粋な無駄となります。
5. なぜこのような結果になったのか?
論文の発見を総合すると、以下のようなメカニズムが働いています:
1
2
3
4
5
6
7
8
9
10
11
コンテキストファイルを提供
├── エージェントが指示を忠実に守る ✅
│ ├── より多くのツールを使用 (grep, test など)
│ ├── より広い範囲を探索
│ └── より多くの推論トークンを消費
│
├── しかし、情報が重複している ❌
│ ├── README, docs/ と同じ内容
│ └── エージェントがすでにアクセス可能な情報
│
└── 結果:コスト ↑、性能 ↔ または ↓
核心的な洞察:問題は、エージェントの「指示に従う能力」の不足ではなく、指示そのものの情報の質にあります。エージェントがすでに自分で発見できる情報を繰り返し教えると、かえって探索範囲が広がり、コストだけが増加します。
6. それでは、どうすればよいのか?
論文の推奨事項
レポジトリの管理者へ:
| やるべきではないこと | やるべきこと |
|---|---|
| LLMでコンテキストファイルを自動生成する | 開発者が直接、最小限の必須情報だけを記述する |
| コードベースの構造全体を説明する | プロジェクト独自の特殊な要件だけを記述する |
| 長くて詳細なコンテキストファイル | 短く具体的な指示事項 |
エージェントの開発元へ:
- コンテキストファイルの自動生成の推奨を再考すべきである。
- コンテキストの追加生成よりも、既存コンテキストの活用方法の改善に注力すべきである。
効果的なコンテキストファイルの書き方
論文の結論に基づき、コンテキストファイルに含める価値のある情報とそうでない情報を整理すると:
含める価値のある情報(レポジトリ固有で、ドキュメントにないもの):
1
2
3
4
5
6
7
8
9
10
11
# ビルドコマンド (プロジェクト固有)
bundle exec jekyll serve # ローカル開発
JEKYLL_ENV=production bundle exec jekyll build # 本番環境
# 特殊なツールの要件
- パッケージマネージャーとして uv を使用すること
- テストは必ず pytest-asyncio で実行すること
# プロジェクト固有のルール
- 翻訳ファイルは .en.md, .ja.md のサフィックスを使用する
- 画像は assets/img/post/{category}/ 以下に保存する
含める必要のない情報(すでにドキュメントにあるもの):
1
2
3
4
5
6
7
8
9
# ❌ コードベースの構造説明 (エージェントが直接探索可能)
src/
components/ — Reactコンポーネント
utils/ — ユーティリティ関数
...
# ❌ 一般的なコーディングルール (LLMがすでに学習済み)
- 変数名は camelCase を使用する
- 関数は単一責任の原則に従う
7. 論文の限界と今後の研究
この論文が完璧な結論というわけではありません。いくつかの限界点:
- Pythonプロジェクトのみが対象: 学習データでよく扱われているPythonレポジトリでの結果です。Rust、Zigのようなニッチな言語や、ゲームエンジンのような特殊なドメインでは、コンテキストファイルがより有用である可能性があります。
- タスク解決率のみを測定: コードの品質、セキュリティ、スタイルの整合性など、他の指標は評価されていません。
- 単一タスク基準: 長期的なプロジェクトで、同じレポジトリに対して繰り返し作業を行う際の累積的な効果は未検証です。
- SWE-benchの限界: 有名なレポジトリが中心であるため、LLMがすでに学習データとして接したコードである可能性が高いです。
今後の研究方向
- ニッチなプログラミング言語におけるコンテキストファイルの効果。
- コードの効率性・セキュリティ面の影響評価。
- 本当に有用な最小限のコンテキストファイルの自動生成手法。
8. このブログに適用するなら
このブログ(Epheria)は Jekyll ベースの静的サイトで、 CLAUDE.md をかなり詳細に作成しています。論文の結論を適用してみると:
維持する価値のある情報:
bundle exec jekyll serveなどのビルドコマンド — プロジェクト固有。jekyll-polyglotの多言語ルール(.en.md,.ja.mdサフィックス) — 標準ドキュメントにないプロジェクト固有のルール。- ポストの front matter 形式 — Chirpy テーマのカスタマイズによる非標準の設定。
assets/img/post/{category}/の画像ルール — プロジェクト固有のコンベンション。
再検討すべき情報:
- ディレクトリ構造全体の列挙 — エージェントが直接探索可能。
- カテゴリ別のポスト数統計 — 情報提供ではあるが、エージェントの性能には寄与しない可能性がある。
- 一般的なコーディングスタイルルール —
.editorconfigですでに定義済み。
ただし、このブログは論文が対象とした「有名なPythonレポジトリ」ではなく、Jekyll + Chirpy のカスタマイズが多いニッチなプロジェクトであるため、論文の「コンテキストファイルの省略」推奨をそのまま適用するよりは、プロジェクト固有の情報中心に整理するのが合理的です。
おわりに
この論文の結論を一言で要約すると:
「エージェントがすでに知ることができることを、わざわざ教えるな。」
コンテキストファイル自体が悪いわけではありません。重複した情報を詰め込むことが悪いのです。LLMの自動生成ではなく開発者が直接作成した、最小限のプロジェクト固有情報だけを盛り込んだコンテキストファイルは、依然としてわずかなプラスの効果を示しています。
コンテキストファイルを記述する際、自分自身に問いかけてみましょう。「この情報は、エージェントがレポジトリを探索して自分で知ることができるだろうか?」 答えが「Yes」なら、その内容はコンテキストファイルに入れない方が得策です。
References
- Gloaguen, T., Mündler, N., Müller, M., Raychev, V., & Vechev, M. (2026). Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? arXiv:2602.11988. https://arxiv.org/abs/2602.11988
- OpenAI. (2026). Custom instructions with AGENTS.md. https://developers.openai.com/codex/guides/agents-md/
- Anthropic. (2026). Claude Code Documentation — CLAUDE.md. https://docs.anthropic.com/en/docs/claude-code