
Flow Field 最適化 — 3,000から10,000エージェントへのスケーリング
- Flow Field パスファインディング — 大規模群衆のための最適解
- Flow Field 最適化 — 3,000から10,000エージェントへのスケーリング
- 3,000エージェントの実際のボトルネックはパスファインディングではなく、メインスレッドのソート(37%)、レンダリング(30%)、分離計算(20%)だった
- NativeArray.Sort()をBurst SortJobに置き換える一行の変更だけで、p50フレームタイムが7.71ms → 5.02ms(-34.9%)改善された
- GPU Instancing + VATで10,000エージェントをGameObjectなしでレンダリングし、空間ハッシングで分離ステアリングをO(N²) → O(N)に削減した

はじめに
前回の記事では、Flow Fieldパスファインディングの概念と3段階パイプラインを解説した。Flow Fieldはエージェント数に関係なく \(O(V)\) で計算されるため、パスファインディング自体はボトルネックではない。
では、3,000エージェントでフレームレートが低下する原因は何か?そして10,000エージェントまでスケールアップするには何を変える必要があるのか?
この記事では、実際のプロファイリングデータに基づいてボトルネックを特定し、5つの主要な最適化を適用して3,000 → 10,000エージェントまでスケーリングした過程を解説する。
以下の動画は、すべての最適化適用後、VATアニメーションと実際のゾンビモデルで10,000エージェントが動作するデモだ。
Part 1: ボトルネックの特定 — パスファインディングではなかった
プロファイリング結果
3,000エージェントでUnity Profilerによりフレームを分析した結果、Flow Fieldパイプライン(Cost → Integration → Flow)はフレームの10%未満だった。本当のボトルネックは全く別の場所にあった。
| ボトルネック | フレーム比率 | 原因 |
|---|---|---|
| NativeArray.Sort | ~37% | 分離ステアリング用ソートがメインスレッドをブロッキング |
| レンダリング | ~30% | GameObjectベースレンダリングのコンポーネントオーバーヘッド |
| 分離計算 | ~20% | エージェント間衝突回避 \(O(N^2)\) 演算 |
| パスファインディング | <10% | Flow Field再計算(既に効率的) |
pie title フレームタイム比率(3Kエージェント)
"NativeArray.Sort" : 37
"レンダリング (GameObject)" : 30
"分離ステアリング" : 20
"パスファインディング" : 8
"その他" : 5
このデータが示すことは明確だ。パスファインディングアルゴリズムをどれだけ改善してもフレームは10%しか改善しない。本当の性能向上には残りの90%を攻略する必要がある。
最適化の順序決定
ボトルネックの比率と実装難易度を基準に最適化順序を決定した:
| 順序 | 最適化 | 予想効果 | 難易度 |
|---|---|---|---|
| 1 | Burst SortJob | フレーム ~37% 削減 | 一行変更 |
| 2 | GPU Instancing + VAT | レンダリングコスト大幅削減 | シェーダー + アーキテクチャ変更 |
| 3 | 空間ハッシング分離ステアリング | \(O(N^2) → O(N)\) | Jobパイプライン再設計 |
| 4 | Tiered LOD | 不要な演算の排除 | システム追加 |
| 5 | Frustum Culling | GPU負荷削減 | Job追加 |
最も少ない労力で最大の効果が得られるものから適用する。
Part 2: Burst SortJob — 一行で37%削減
問題:メインスレッドのブロッキング
分離ステアリングのためにエージェントをセルインデックス基準でソートする必要がある。同じセルのエージェントをメモリ上で連続配置することで、近傍検索が高速化されるためだ。
問題はNativeArray.Sort()がメインスレッドで同期的に実行されることだった。20,000エージェント基準でこのソートに~2.9msかかっており、これは全フレームタイムの37%に相当した。その間、19個のJob Workerスレッドはアイドル状態だった。
1
2
3
4
[Before] メインスレッドでの同期ソート
──────────────────────────────────────────────────
Main Thread: ████ Sort (2.9ms) ████ Separation ████
Worker 1~19: ░░░░░░░░░░░░░░░░ (待機) ░░░░░░░░░░░░░░░░
解決策:.SortJob()
Unity CollectionsパッケージはNativeArrayに.SortJob()拡張メソッドを提供している。これは内部的にBurstコンパイルされたMerge Sortを使用し、Jobチェーンに組み込むことができる。
1
2
3
4
5
6
7
// Before: メインスレッドブロッキング
_data.CellAgentPairs.Sort(new CellIndexComparer());
// After: Burst SortJob、ワーカースレッドで実行
var h2 = _data.CellAgentPairs
.SortJob(new CellIndexComparer())
.Schedule(h1); // 前のJobハンドルにチェイニング
一行の変更だ。.Sort()を.SortJob().Schedule()に置き換えれば、ソートがワーカースレッドに移動し、メインスレッドは解放される。
1
2
3
4
[After] Burst SortJobによるワーカースレッドでの非同期ソート
──────────────────────────────────────────────────
Main Thread: ░░░░░░░░░░░░░░ (他の処理を実行) ░░░░░░░░░░░░░░
Worker 1: ████ SortJob ████ → Separation ████
全体のJobチェーン
SortJobは分離ステアリングパイプラインの4段階中2段階目に該当する。チェーン全体がワーカースレッドで依存関係の順序に従って実行される:
1
2
3
4
5
6
7
8
9
10
11
12
13
// Phase 1: 各エージェントのセルインデックス割り当て
var h1 = assignJob.Schedule(_activeCount, 64);
// Phase 2: セルインデックス基準ソート(Burst SortJob)
var h2 = _data.CellAgentPairs
.SortJob(new CellIndexComparer())
.Schedule(h1);
// Phase 3: セル別(開始インデックス、個数)構築
var h3 = rangesJob.Schedule(h2);
// Phase 4: 3×3近傍セルベースの分離計算
var handle = sepJob.Schedule(_activeCount, 64, h3);
メインスレッドはこのチェーンをスケジュールするだけで即座にリターンする。実際の演算はすべてワーカースレッドで行われる。
結果
| 指標 | Before | After | 改善 |
|---|---|---|---|
| Separation全体 | 3.34ms | 0.73ms | -78% |
| p50フレームタイム | 7.71ms | 5.02ms | -34.9% |
| Job Worker稼働率 | ~0% | 9.0% | — |
一行の変更でp50が7.71ms → 5.02msに改善された。最小の労力で最大の効果を得た最適化だ。
教訓:最適化の第一歩は常にプロファイリングだ。直感で「パスファインディングが遅いはず」と思い込んでいたら、実際のボトルネック(Sort)を見逃していただろう。
Part 3: GPU Instancing + VAT — Zero-GameObjectアーキテクチャ
問題:GameObjectのコスト
3,000体のゾンビをそれぞれGameObjectとして生成すると:
1
2
3
ゾンビ1体 = Transform + MeshRenderer + Animator + Collider
→ 3,000体 = CPU側コンポーネント12,000個以上
→ 10,000体 = CPU側コンポーネント40,000個以上
Transform同期、Animator更新、レンダリングカリング — すべてUnityエンジンが毎フレーム処理するコストだ。10,000体ではこれだけでフレーム予算を超過する。
解決策:GameObjectを排除する
GPU Instancing:Graphics.RenderMeshInstanced()を使用すれば、同じメッシュ+マテリアルを共有するインスタンスを単一ドローコールで最大1,023個までレンダリングできる。TransformはNativeArray<float4x4>マトリックス配列で管理し、Burst Jobが毎フレーム更新する。
1
2
3
4
5
6
7
8
9
10
11
12
// PositionToMatrixJob(Burstコンパイル、IJobParallelFor)
// 位置 + 速度方向 → TRSマトリックス変換
float4x4 matrix = float4x4.TRS(position, rotation, scale);
Matrices[index] = matrix;
// レンダリング:タイプ別にバッチ分割
for (int offset = 0; offset < visibleCount; offset += 1023)
{
int batchSize = math.min(1023, visibleCount - offset);
var batch = matrices.GetSubArray(offset, batchSize);
Graphics.RenderMeshInstanced(renderParams, mesh, 0, batch);
}
VAT (Vertex Animation Texture):Animatorなしでgpu上でアニメーションを再生する。原理はシンプルだ:
- オフラインでゾンビの歩行アニメーションの全フレーム、全頂点位置をテクスチャに保存
- ランタイムにシェーダーが現在の時刻に対応するテクスチャ行をサンプリング
- サンプリングした値で頂点位置を変形
1
2
3
4
5
6
テクスチャレイアウト:
U軸 → 頂点インデックス (0 ~ 4,349)
V軸 → フレームインデックス (0 ~ 59)
各テクセル = RGBAHalf = 該当フレームにおける該当頂点の (x, y, z) オフセット
VRAMコスト:~1MB per クリップ (4,350 verts × 60 frames × RGBAHalf)
位相オフセット:同期の回避
VATの落とし穴は、すべてのゾンビが同じタイミングで同じフレームを再生することだ。数千体が完璧に同期した群舞を踊ると不自然になる。
解決策はワールド座標ベースのハッシュでエージェントごとに開始位相をずらすことだ:
1
2
3
4
5
6
7
8
9
10
// ワールドXZ座標でハッシュ → エージェントごとに異なる開始位相
float phaseOffset = frac(worldPos.x * 0.137 + worldPos.z * 0.241);
float time = (_Time.y * _AnimSpeed + phaseOffset * _AnimLength)
% _AnimLength;
// 隣接フレーム補間 → 滑らかなアニメーション
float frameFloat = (time / _AnimLength) * (_FrameCount - 1);
float frame0 = floor(frameFloat);
float frame1 = frame0 + 1;
float blend = frameFloat - frame0;
このコードでインスタンスごとの追加データ転送なしに、位置だけで自然な非同期アニメーションが実現できる。
ルートモーションのストリッピング
VATにルートモーションが含まれると、ゾンビが定位置で移動する代わりにシェーダー空間で歩き去ってしまう。これを防ぐために頂点0(ルートボーン)のXZオフセットを除去する:
1
2
3
4
5
6
7
8
if (_StripRootMotion > 0.5)
{
// ルートボーン(vertex 0)のXZオフセットをサンプリング
float2 rootUV0 = float2(0.5 / _TexWidth, v0);
float3 rootOffset0 = tex2Dlod(_VATPosTex, float4(rootUV0, 0, 0)).xyz;
// 現在の頂点からルートのXZ移動分を除去
offset0.xz -= rootOffset0.xz;
}
Before vs After
1
2
3
4
5
6
7
8
9
10
11
[Before] GameObjectベース
───────────────────────────────────
CPU: Transform × 10K + Animator × 10K + MeshRenderer × 10K
GPU: 10,000ドローコール(バッチングなし)
→ 物理的に不可能
[After] NativeArray + GPU Instancing + VAT
───────────────────────────────────
CPU: NativeArray<float4x4> 更新(Burst Job)
GPU: ~58ドローコール(1,023個ずつバッチング)
→ 10,000エージェント @ 60fps
Part 4: 空間ハッシング分離ステアリング — O(N²) → O(N)
問題:N²比較
分離ステアリング(Separation Steering)は、エージェントが互いに重ならないよう押し出す力を計算する。素朴な実装は全エージェントペアを比較する:
\[\text{比較回数} = \frac{N(N-1)}{2}\]| エージェント数 | 比較回数 |
|---|---|
| 1,000 | 499,500 |
| 3,000 | 4,498,500 |
| 10,000 | 49,995,000 |
10,000エージェントでは毎フレーム5,000万回の距離計算が必要になる。Burstでコンパイルしてもこの規模は処理しきれない。
解決策:セルベース空間ハッシング
核心となるアイデアは近くのエージェントだけを比較することだ。Flow Fieldが既にグリッドを使用しているため、同じグリッド構造を再利用する。
flowchart LR
A["<b>AssignCells</b><br/>エージェント → セルマッピング<br/>(IJobParallelFor)"] --> B["<b>SortJob</b><br/>セルインデックス基準ソート<br/>(Burst)"] --> C["<b>BuildCellRanges</b><br/>セル別開始/個数<br/>(IJob)"] --> D["<b>ComputeSeparation</b><br/>3×3近傍のみ検査<br/>(IJobParallelFor)"]
style A fill:#e8d5b7,stroke:#b8860b,color:#333
style B fill:#b7d5e8,stroke:#4682b4,color:#333
style C fill:#d5b7e8,stroke:#8b57b4,color:#333
style D fill:#b7e8c4,stroke:#2e8b57,color:#333
Step 1: AssignCellsJob
各エージェントのワールド座標をグリッドセルインデックスに変換する。
1
2
3
4
5
6
// (position.x, position.z) → (cellX, cellZ) → 1Dインデックス
int cellX = (int)(position.x / cellSize);
int cellZ = (int)(position.z / cellSize);
int cellIndex = cellZ * gridWidth + cellX;
CellAgentPairs[i] = new int2(cellIndex, agentIndex);
Step 2: SortJob
セルインデックス基準でソートすると、同じセルのエージェントが配列内で連続して配置される:
1
2
3
ソート前: [(5,A), (2,B), (5,C), (2,D), (3,E)]
ソート後: [(2,B), (2,D), (3,E), (5,A), (5,C)]
▲ セル2 ▲ ▲セル3▲ ▲ セル5 ▲
これがPart 2で解説したBurst SortJobだ。
Step 3: BuildCellRangesJob
ソート済み配列を一度走査し、各セルの(開始インデックス、個数)を記録する:
1
2
3
4
CellRanges[cellIndex] = new int2(startIndex, count);
// 例: CellRanges[2] = (0, 2) → インデックス0から2個
// CellRanges[3] = (2, 1) → インデックス2から1個
// CellRanges[5] = (3, 2) → インデックス3から2個
Step 4: ComputeSeparationJob
各エージェントは自身のセル + 周囲8セル = 3×3範囲のみを検査する:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
for (int dx = -1; dx <= 1; dx++)
for (int dz = -1; dz <= 1; dz++)
{
int2 checkCell = myCell + new int2(dx, dz);
int cellIdx = CellToIndex(checkCell);
int2 range = CellRanges[cellIdx]; // O(1) ルックアップ
for (int k = range.x; k < range.x + range.y; k++)
{
int otherIdx = SortedPairs[k].y;
float3 diff = myPos - Positions[otherIdx];
float dist = math.length(diff);
if (dist > 0 && dist < radius)
{
// 二次減衰:近いほど強く押し出す
float strength = (1 - dist / radius);
strength *= strength;
force += math.normalize(diff) * strength;
}
}
}
なぜO(N)なのか
- 各エージェントが検査するセル:常に9個(3×3)
- セルあたりのエージェント数:密度により異なるが、実測平均5~15個
- エージェントあたりの比較回数:9 × 平均密度 = 定数に近い
- 全体の比較回数:\(O(N \times \text{const}) = O(N)\)
| 素朴な実装 | 空間ハッシング | |
|---|---|---|
| 10,000エージェント | 49,995,000比較 | ~90,000~150,000比較 |
| 計算量 | \(O(N^2)\) | \(O(N)\) |
追加の利点:ソート済み配列のおかげで、同じセルのエージェントがメモリ上で連続配置される。CPUキャッシュラインが効率的に活用され、単純な比較回数以上の性能向上が得られる。
Part 5: Tiered LOD — 距離ベースの品質差別化
アイデア
画面の隅で点のようにしか見えないゾンビにRigidbody物理とAnimatorを動かす必要はない。プレイヤーとの距離に応じて処理レベルを差別化する。
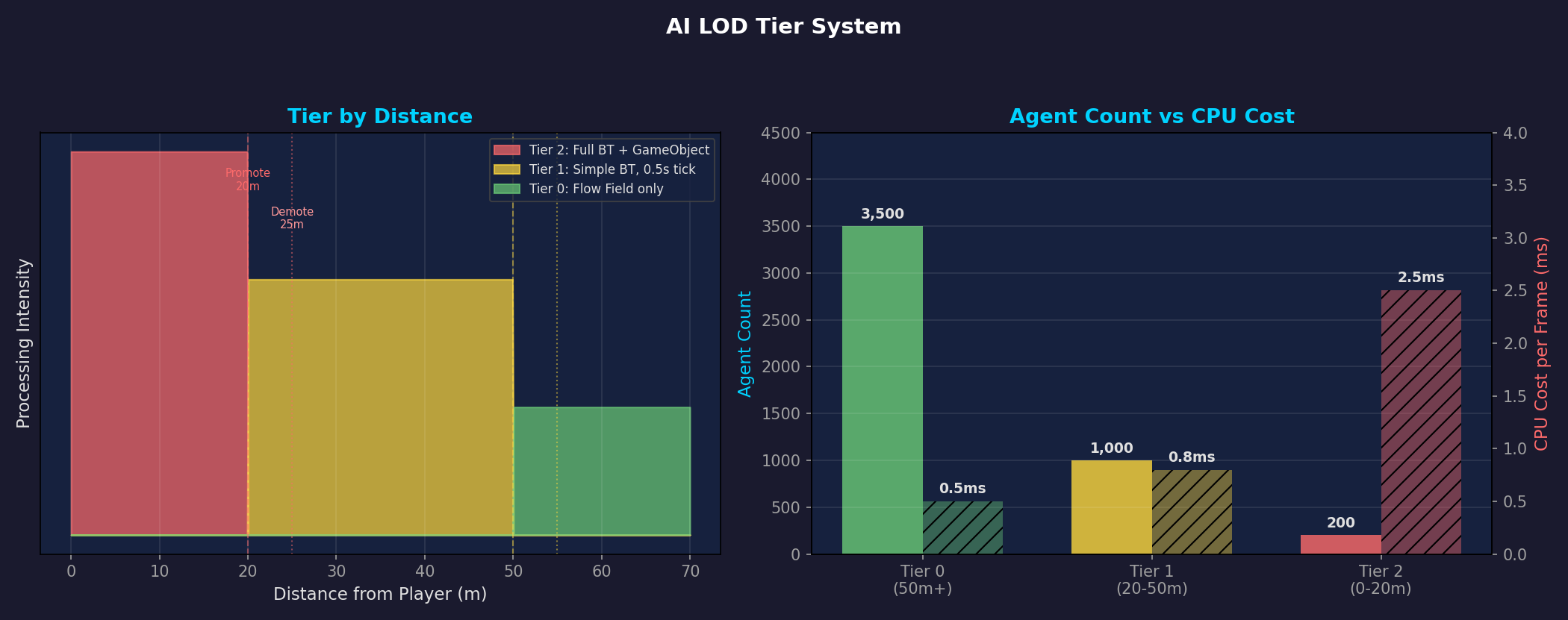 左:距離別Tier区間とヒステリシス(Promote 20m / Demote 25m)。右:Tier別エージェント数対CPUコスト — Tier 0が3,500体だが0.5ms、Tier 2は200体で2.5ms。
左:距離別Tier区間とヒステリシス(Promote 20m / Demote 25m)。右:Tier別エージェント数対CPUコスト — Tier 0が3,500体だが0.5ms、Tier 2は200体で2.5ms。
| Tier | 距離 | 表現 | 物理 | アニメーション |
|---|---|---|---|---|
| Tier 0 | > 50m | NativeArray + GPU Instancing | なし | VAT (GPU) |
| Tier 1 | 25~50m | NativeArray + GPU Instancing | なし | VAT (GPU) |
| Tier 2 | < 20m | GameObject + Rigidbody | MovePosition | Animator(予定) |
Tier 0/1は純粋なデータだ。NativeArrayに位置/速度のみ格納し、GPU Instancingでレンダリングする。CPUコストはMove JobとMatrix Jobだけだ。
Tier 2のみGameObjectを使用し、プレイヤーとの近接戦闘が可能なフルスペックゾンビだ。同時最大300体に制限する。
ヒステリシス:境界での振動防止
昇格距離(20m)と降格距離(25m)を異なる値に設定する。この5mのギャップが境界線でTierが繰り返し切り替わることを防止する。
1
2
3
4
5
距離: 0m ────── 20m ──── 25m ──── 50m ──── 55m ────→
│ Tier 2 │ ギャップ(5m) │ Tier 1 │ ギャップ(5m) │ Tier 0
│ │ │ │ │
└─ 昇格 ───┘ │ └─ 昇格 ──┘
└─── 降格 ───┘ └─── 降格 ───┘
フレームあたりの遷移制限
100体が同時に20mラインを越えると、1フレームで100個のGameObjectを生成しなければならない。これを防ぐためにフレームあたり最大10個に遷移を制限する:
1
2
[SerializeField] private int _maxPromotionsPerFrame = 10;
[SerializeField] private int _maxDemotionsPerFrame = 10;
残りは次フレームに繰り越される。プレイヤーの体感では10フレーム(~167ms)かけて自然に遷移する。
Part 6: Frustum Culling — 見えないものは描画しない
カメラ外のゾンビをGPUに送るのは純粋な無駄だ。BurstコンパイルされたCompactVisibleByTypeJobが毎フレーム処理する。
動作方式
- カメラの視錐台6平面(上/下/左/右/近/遠)を抽出
- 各エージェントのAABB(軸平行バウンディングボックス)と6平面をテスト
- すべての平面の内側にあるエージェントのみ出力配列にコンパクト化
1
2
3
4
5
6
7
8
9
10
11
12
13
// 6平面テスト
bool visible = true;
for (int p = 0; p < 6; p++)
{
float4 plane = FrustumPlanes[p];
float dist = math.dot(plane.xyz, center) + plane.w;
float radius = math.dot(math.abs(plane.xyz), extents);
if (dist + radius < 0f)
{
visible = false;
break; // 1つでも外なら即座に除外
}
}
タイプ別分離コンパクト化
ゾンビタイプ(Fast/Slow)別に異なるメッシュとマテリアルを使用するため、可視ゾンビをタイプ別に分離コンパクト化する:
1
2
3
4
5
6
出力配列レイアウト:
[Type 0 マトリックス: 0 ~ Capacity-1]
[Type 1 マトリックス: Capacity ~ 2×Capacity-1]
各タイプの実数をVisibleCountsに記録
→ レンダリング時にタイプ別に正確な個数分だけドローコールを発行
カメラがマップ全体の1/4だけを映している場合、レンダリングコストも~1/4に減少する。
Part 7: SoAデータレイアウト — Burstが好むメモリ構造
AoS vs SoA
従来のOOP方式はAoS(Array of Structures)だ:
1
2
3
4
5
6
7
8
9
10
// AoS: ゾンビ1体のすべてのデータが連続
struct Zombie {
float3 Position; // 12B
float3 Velocity; // 12B
float Health; // 4B
byte State; // 1B
byte Tier; // 1B
// ... 合計 ~80B per zombie
}
Zombie[] zombies = new Zombie[10000];
SoA(Structure of Arrays)は同じフィールドをまとめて格納する:
1
2
3
4
5
6
// SoA: 同じ種類のデータが連続
NativeArray<float3> Positions; // 10K × 12B = 120KB(連続)
NativeArray<float3> Velocities; // 10K × 12B = 120KB(連続)
NativeArray<float> Healths; // 10K × 4B = 40KB (連続)
NativeArray<byte> States; // 10K × 1B = 10KB (連続)
NativeArray<byte> AiTiers; // 10K × 1B = 10KB (連続)
なぜSoAが速いのか
Move Jobが位置を更新する際、Positions配列のみを逐次アクセスする:
1
2
3
4
5
6
7
8
9
10
11
12
13
[AoS] Positionsを読む時 — 80Bごとに12Bだけ有効
┌─────────────────────────────────────────────────┐
│ Pos₀ Vel₀ HP₀ ... │ Pos₁ Vel₁ HP₁ ... │ Pos₂ │
│ ████ ░░░░░░░░░░░░░ │ ████ ░░░░░░░░░░░░░ │ ████ │
└─────────────────────────────────────────────────┘
キャッシュライン64B中12Bのみ使用 → 効率15%
[SoA] Positions配列 — 連続する12Bが隙間なく並ぶ
┌─────────────────────────────────────────────────┐
│ Pos₀ │ Pos₁ │ Pos₂ │ Pos₃ │ Pos₄ │ Pos₅ │ ... │
│ ████ │ ████ │ ████ │ ████ │ ████ │ ████ │ ... │
└─────────────────────────────────────────────────┘
キャッシュライン64B中60B使用 → 効率93%
さらにBurstコンパイラがSoAレイアウトを検出すると、SIMD(SSE/AVX)の自動ベクトライゼーションを適用する。float3を4つ同時に処理するため、理論上4倍高速になる。
実際のプロジェクトでは17個のNativeArrayでゾンビデータを管理している。Position、Velocity、Health、State、Tier、Type、Matrixなど、各Jobが必要な配列のみ選択的にアクセスし、キャッシュ効率を最大化している。
Part 8: 全体フレームパイプライン
すべての最適化が適用された後のフレームパイプラインだ。各Phaseが前のPhaseの結果に依存する構造で、可能な限り並列にスケジュールする:
flowchart TD
subgraph Phase1["Phase 1: 並列Jobスケジュール (~1.0ms)"]
A[DistanceJob]
B[SortJob チェーン<br/>Assign→Sort→Ranges→Separation]
C[KnockbackDecayJob]
D[EffectTimerJob]
end
subgraph Phase2["Phase 2: 距離同期 + 追加スケジュール (~0.3ms)"]
E[TierAssignJob]
F[AttackJob]
end
subgraph Phase3["Phase 3: 全体同期 + LOD遷移 (~0.5ms)"]
G[LOD Transitions<br/>Tier 昇格/降格]
H[Attack 結果処理]
end
subgraph Phase4["Phase 4: 移動 + レンダリング (~2.1ms)"]
I[MoveJob<br/>Flow Field 参照 + 移動]
J[PositionToMatrixJob]
K[CompactVisibleByTypeJob<br/>Frustum Culling]
L[Graphics.RenderMeshInstanced]
end
Phase1 --> Phase2 --> Phase3 --> Phase4
style Phase1 fill:#e8f5e9,stroke:#4caf50,color:#333
style Phase2 fill:#e3f2fd,stroke:#2196f3,color:#333
style Phase3 fill:#fff3e0,stroke:#ff9800,color:#333
style Phase4 fill:#fce4ec,stroke:#e91e63,color:#333
核心原則:メインスレッドはスケジューリングと同期のみを担当し、実際の演算はすべてBurstコンパイルされたワーカースレッドで実行する。
最終結果
プロファイリング比較
| 指標 | 3K(最適化前) | 10K(最適化後) | 20K(ストレステスト) |
|---|---|---|---|
| p50フレームタイム | ~10ms | ~5.2ms | 7.71ms |
| レンダリング方式 | デバッグカプセル | GPU Instancing + VAT | GPU Instancing + VAT |
| 分離ステアリング | ~3.3ms | ~0.73ms | ~0.73ms |
| ドローコール | - | 58(バッチング) | 152 |
| 三角形/フレーム | - | - | 41.2M |
| Job Worker稼働率 | ~0% | ~9% | ~3.6% |
10,000エージェントが3,000よりもエージェントあたりのフレームコストがむしろ低い。ボトルネックを除去し、パイプラインをデータ指向に再設計した結果だ。
最適化別の貢献度
flowchart LR
A["3K Baseline<br/>~10ms"] -->|"SortJob<br/>-34.9%"| B["5.02ms"]
B -->|"GPU Instancing<br/>+ VAT"| C["レンダリングコスト<br/>大幅削減"]
C -->|"空間ハッシング<br/>O(N)→O(N)"| D["分離 0.73ms"]
D -->|"LOD + Culling"| E["10K agents<br/>~5.2ms"]
style A fill:#ffcdd2,stroke:#e53935,color:#333
style E fill:#c8e6c9,stroke:#43a047,color:#333
まだ残っている課題
この記事で紹介した最適化で10,000エージェント @ 60fpsを達成したが、ここで終わりではない。後続の記事では:
- Multi-Goal & Layered Flow Field — 複数目的地とレイヤー分離によるより複雑なAI行動の実装
- クロスプラットフォームベンチマーク — Apple Silicon(M4/M4 Pro)での最適化結果
参考資料
- Unity Technologies. Burst User Guide. Unity Documentation.
- Unity Technologies. NativeArray.SortJob. Unity Collections Package.
- Framebuffer. (2018). Spatial Hashing. GameDev.net.
- Reynolds, C. (1999). Steering Behaviors For Autonomous Characters. GDC Proceedings.