
Claude Skills 2.0 完全ガイド — Skill Creator、ベンチマーク、トリガー最適化まで

- ゲーム開発者のAI活用術:2,165メッセージの記録から見る実戦データ(47日間の記録)
- Claude Opus 4.5 → 4.6 移行期 - ゲーム開発者が体感した性能、トークン、ワークフローの変化
- AGENTS.mdは本当に役に立つのか? — コーディングエージェントのコンテキストファイルの有効性を検証した論文分析
- Claudeメモリ無料開放と/simplify、/batch — そしてCLAUDE.mdの隠れたコスト
- WindowsでClaude Codeをインストールする完全ガイド — 実践トラブルシューティング付き
- ゲームプランナーのためのClaude Code完全活用ガイド — 仕様書からバランシングまで
- macOSでClaude Code C# LSPを完全セットアップするガイド — csharp-lsのインストールからトラブルシューティングまで
- C# LSP vs JetBrains MCP トークン効率分析 — Claude Codeで最適なツール選択戦略
- Claude Skills 2.0 完全ガイド — Skill Creator、ベンチマーク、トリガー最適化まで
- Skills 2.0はCapability Uplift(機能向上)とInquiry Preference(選好度保存)の2軸で分類され、ベンチマークでスキルの存在価値を数値で判断できる
- Skill Creatorが生成・評価・改善・ベンチマークの4モードに拡張され、テストケース自動生成からブラインドA/B比較までスキル開発の全ライフサイクルを自動化する
- フロントマターにcontext: fork、model、effort、hooksなど新オプションが追加され、Description最適化ループで暗黙的トリガー精度を大幅に改善できる

はじめに
Claude Codeのスキル(Skills)システムが大規模なアップデートを迎えた。従来はSKILL.mdファイル1つに指示を書くだけのシンプルな構造だったが、Skills 2.0は自動評価、ベンチマーク、ブラインド比較、トリガー最適化まで備えた完全なスキル開発フレームワークに進化した。
今回のアップデートの主な変更点:
- Skill CreatorプラグインがCreate・Eval・Improve・Benchmarkの4モードに大幅強化
- スキル使用/未使用時の結果を自動でA/Bテストするベンチマークシステムを内蔵
- フロントマターに
context: fork、model、effort、hooksなど精密な実行制御オプションを追加 - Description最適化ループで暗黙的トリガー精度を改善
本記事では公式ドキュメント、Skill Creator実装、Anthropicブログを交差検証し、実務に必要なすべての内容を整理する。
1. スキルの2つの分類体系
Anthropicはスキルの役割を明確に2つに分けている。
1-1. Capability Uplift(機能向上型)
Claudeが自力ではできない新しい能力を付与するスキルだ。
- 社内専用チェックリスト、独自フレームワーク、特定ツール連携
- AIモデルの発展によりベース機能に吸収される可能性あり
- ベンチマークで「このスキルはまだ必要か?」を数値で判断
例えば、以前はPDFテキスト抽出をスキルで教える必要があったが、モデルが進化すると基本ツールだけで十分になり得る。ベンチマーク結果でスキルの有無に差がなければ、そのスキルは廃止候補となる。
1-2. Inquiry Preference(要求選好度型)
Claudeがすでにできるが、特定のワークフローやトーン&マナーを一貫して従わせるスキルだ。
- コミットメッセージのスタイル、コードレビュー形式、レポートテンプレート
- 客観的に「より良い」結果ではなく、ユーザーが望む方法での結果を保証
- モデルが発展してもユーザーの好みは変わらないため長期的に維持される
公式Best Practicesドキュメントでも「Claude is already very smart — Only add context Claude doesn’t already have」と明記している。不要な説明を省き、Claudeが知らないことだけを教えることが核心だ。
2. Progressive Disclosure — 3段階の漸進的ロード
スキルはコンテキストウィンドウを効率的に使用するため、3段階に分けてロードされる。
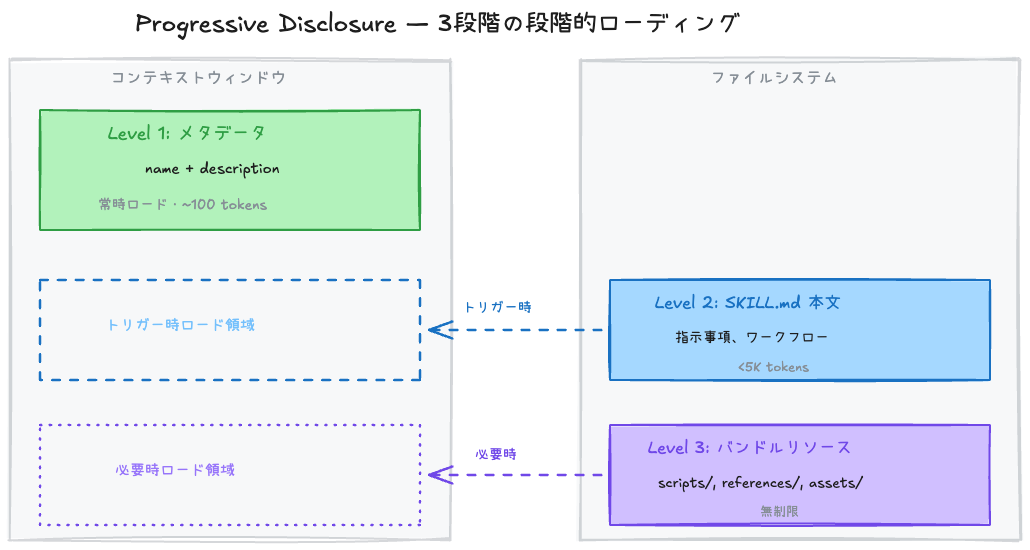
| レベル | ロード時点 | トークンコスト | 内容 |
|---|---|---|---|
| Level 1: メタデータ | 常時(セッション開始時) | ~100トークン/スキル | name + description |
| Level 2: SKILL.md本文 | スキルトリガー時 | 5Kトークン以下 | 指示、ワークフロー |
| Level 3: バンドルリソース | 必要時のみ | 事実上無制限 | スクリプト、リファレンス文書、アセット |
2-1. ディレクトリ構造
1
2
3
4
5
6
7
8
skill-name/
├── SKILL.md # 必須 — メイン指示(500行以下推奨)
├── references/ # 必要時にロードされる参照文書
│ ├── finance.md
│ └── sales.md
├── scripts/ # 実行のみ(コード自体はコンテキストに入らない)
│ └── validate.py
└── assets/ # テンプレート、アイコン、フォントなど
核心はscripts/ディレクトリだ。Claudeがpython scripts/validate.pyを実行すると、スクリプトのコード自体はコンテキストウィンドウに入らず、実行結果のみがトークンを消費する。数百行の検証ロジックも出力数行に要約される。
2-2. ロードフローの例
1
2
3
4
5
1. セッション開始 → "PDF Processing - Extract text and tables..." (メタデータのみロード)
2. ユーザー: "このPDFから表を抽出して"
3. Claude判断 → SKILL.md本文ロード
4. フォーム作成が必要な場合のみ → FORMS.md追加ロード
5. スクリプト実行 → 結果のみ受信
多くのスキルをインストールしてもLevel 1(メタデータ)のみが常駐するため、コンテキストペナルティはほぼない。スキルdescriptionの総文字予算はコンテキストウィンドウの2%(フォールバック: 16,000文字)で動的に調整される。
3. フロントマター完全ガイド
SKILL.md上部のYAMLフロントマターでスキルの動作を細かく制御できる。Skills 2.0で大幅に拡張された部分だ。
3-1. 全フィールドリファレンス
| フィールド | 必須 | 説明 |
|---|---|---|
name | No | スキル識別子。小文字+数字+ハイフンのみ、最大64文字 |
description | 推奨 | トリガーの核心。何をするか + いつ使うべきか。最大1024文字 |
disable-model-invocation | No | true → Claudeが自動実行不可(ユーザー/コマンドのみ) |
user-invocable | No | false → /メニューで非表示(Claudeのみ内部使用) |
allowed-tools | No | スキル有効時に許可するツールを制限(例: Read, Grep, Glob) |
model | No | スキル実行時に使用するAIモデルを指定 |
effort | No | 努力レベル: low, medium, high, max(Opus 4.6のみmax対応) |
context | No | fork → 独立サブエージェントで実行 |
agent | No | context: fork時のエージェントタイプ(Explore, Planなど) |
hooks | No | スキルライフサイクルフック(YAML形式) |
argument-hint | No | オートコンプリートヒント(例: [issue-number]) |
3-2. 実行権限制御 — 誰がスキルを呼び出せるか
| 設定 | ユーザー呼び出し | Claude呼び出し | コンテキストロード |
|---|---|---|---|
| デフォルト | O | O | description常時ロード |
disable-model-invocation: true | O | X | description非ロード |
user-invocable: false | X | O | description常時ロード |
実用的な例:
1
2
3
4
5
6
# デプロイスキル — ユーザーの手動実行のみで安全を確保
---
name: deploy
description: Deploy the application to production
disable-model-invocation: true
---
Claudeが「コードの準備ができたようなのでデプロイします」と自意的に判断する状況を根本的に防止する。
1
2
3
4
5
6
# レガシーシステムコンテキスト — Claudeのみが参照する背景知識
---
name: legacy-system-context
description: Explains how the old auth system works
user-invocable: false
---
ユーザーが/legacy-system-contextを直接実行することはないが、Claudeが関連質問を受けると自動的に参照する。
3-3. 文字列置換変数
スキル本文で動的な値を挿入できる:
| 変数 | 説明 |
|---|---|
$ARGUMENTS | スキル呼び出し時に渡された全引数 |
$ARGUMENTS[N]または$N | N番目の引数(0ベース) |
${CLAUDE_SESSION_ID} | 現在のセッションID |
${CLAUDE_SKILL_DIR} | スキルのSKILL.mdがあるディレクトリ |
1
2
3
4
5
6
7
---
name: migrate-component
description: Migrate a component from one framework to another
---
Migrate the $0 component from $1 to $2.
Preserve all existing behavior and tests.
/migrate-component SearchBar React Vue → $0=SearchBar, $1=React, $2=Vue
3-4. サブエージェント実行 (context: fork)
context: forkを設定するとスキルが独立したコンテキストで実行される。会話履歴にアクセスせず、SKILL.mdの内容がサブエージェントのプロンプトとなる。
1
2
3
4
5
6
7
8
9
10
11
---
name: deep-research
description: Research a topic thoroughly
context: fork
agent: Explore
---
Research $ARGUMENTS thoroughly:
1. Find relevant files using Glob and Grep
2. Read and analyze the code
3. Summarize findings with specific file references
agentフィールドでサブエージェントのタイプを指定できる:Explore(読み取り専用探索)、Plan(設計)、general-purpose(汎用)、または.claude/agents/で定義したカスタムエージェント。
3-5. 動的コンテキスト注入
!`command`構文でシェルコマンドの結果を前処理段階で挿入できる:
1
2
3
4
5
6
7
8
9
10
11
12
13
---
name: pr-summary
description: Summarize changes in a pull request
context: fork
agent: Explore
---
## Pull Requestコンテキスト
- PR diff: !`gh pr diff`
- 変更ファイル: !`gh pr diff --name-only`
## タスク
このPRの変更内容を要約して...
各!`command`はClaudeが見る前に実行され、Claudeは置換済みの最終結果のみを受け取る。
4. Skill Creator — スキル開発フレームワーク
Skill Creatorは単純な生成ツールから、スキルの全ライフサイクルを管理するフレームワークに進化した。
4-1. 4つの運用モード
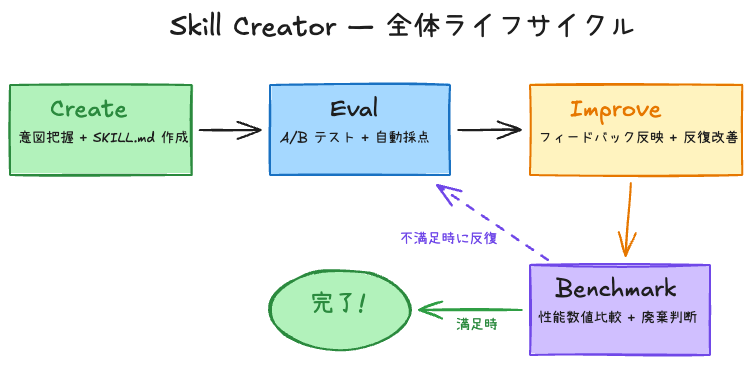
| モード | 目的 | 主な動作 |
|---|---|---|
| Create | 新スキル生成 | 意図把握 → インタビュー → SKILL.md作成 → テストケース |
| Eval | スキル評価 | テストプロンプト実行 → assertionsでpass/fail自動判定 |
| Improve | 反復改善 | フィードバック基盤修正 → 再実行 → 比較 → 満足するまで反復 |
| Benchmark | 性能ベンチマーク | スキル使用 vs 未使用 A/Bテスト → 統計レポート |
4-2. Createモード — スキル生成ワークフロー
Step 1: 意図把握(Capture Intent)
Skill Creatorが4つを確認する:
- このスキルはClaudeに何をさせるのか?
- どのような状況でトリガーされるべきか?
- 期待する出力形式は?
- テストケースを設定するか?(客観的検証が可能なスキルは推奨、主観的スキルは選択)
Step 2: インタビューとリサーチ
エッジケース、入出力形式、サンプルファイル、成功基準、依存関係を確認する。MCPがあればサブエージェントで並列リサーチも実行する。
Step 3: SKILL.md作成
核心原則:
- Descriptionを「pushy」に — Claudeはスキルを過少トリガー(undertrigger)する傾向がある
- 三人称で記述 — “Processes Excel files and generates reports”(Good)/ “I can help you…“(Bad)
- Whyを説明 —
ALWAYS/NEVERより理由を説明する方が効果的 - 簡潔に — Claudeがすでに知っていることは省略
1
2
3
4
5
6
7
8
# Bad: 短すぎるdescription
description: Helps with documents
# Good: what + whenを両方含みpushyに
description: >
Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs,
forms, or document extraction.
Step 4: テストケース生成
2〜3個の現実的なプロンプトをevals/evals.jsonに保存:
1
2
3
4
5
6
7
8
9
10
11
{
"skill_name": "pdf-processing",
"evals": [
{
"id": 1,
"prompt": "このPDFからすべてのテキストを抽出してoutput.txtに保存して",
"expected_output": "PDFの全ページからテキストを抽出しファイルに保存",
"files": ["test-files/document.pdf"]
}
]
}
4-3. Evalモード — 評価システム詳細
マルチエージェント並列実行
各テストケースごとに2つのサブエージェントを同時にスポーンする:
1
2
3
テストケース 1 → with_skill エージェント + without_skill エージェント
テストケース 2 → with_skill エージェント + without_skill エージェント
テストケース 3 → with_skill エージェント + without_skill エージェント
各エージェントは独立したコンテキストで実行されるため、相互汚染がない。トークンとタイミングの指標も個別に収集される。
4種の専門サブエージェント
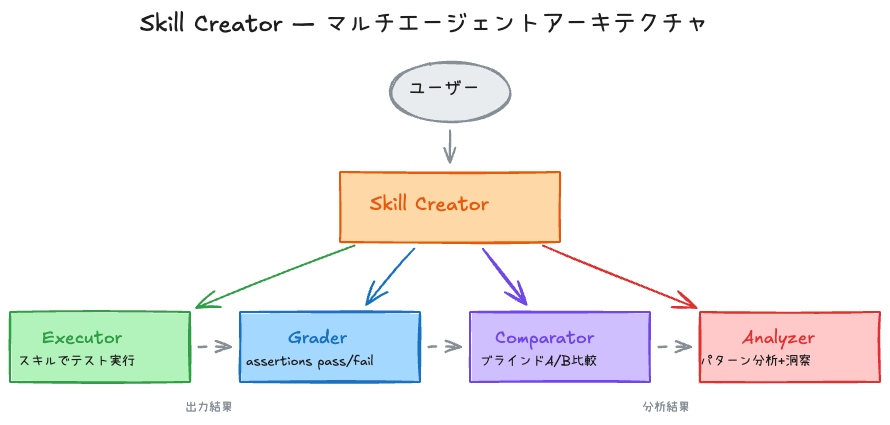
| エージェント | 役割 |
|---|---|
| Executor | スキルを使ってテストプロンプトを実行 |
| Grader | assertionsベースのpass/fail採点 + 根拠提示 |
| Comparator | ブラインドA/B比較(どちらがスキル側か知らない状態で判断) |
| Analyzer | ベンチマークパターン分析 + 改善インサイト導出 |
5段階評価プロセス
Step 1: サブエージェントスポーン — with-skillとbaselineを同じターンにすべて実行
Step 2: Assertions下書き — 実行中に検証基準を事前作成(時間効率化)
1
2
3
4
5
6
7
8
9
10
{
"eval_id": 1,
"eval_name": "pdf-text-extraction",
"prompt": "Extract all text from this PDF",
"assertions": [
"PDFライブラリを使用してファイルを正常に読み込んだ",
"全ページからテキストを抽出した",
"output.txtに読みやすい形式で保存した"
]
}
Step 3: タイミングデータ即時キャプチャ — サブエージェント完了時にtiming.jsonにトークン/時間を保存
1
2
3
4
5
{
"total_tokens": 84852,
"duration_ms": 23332,
"total_duration_seconds": 23.3
}
Step 4: 採点 → 集計 → 分析 → ビューアー起動
1
2
3
4
5
6
7
8
9
# ベンチマーク集計
python -m scripts.aggregate_benchmark workspace/iteration-1 --skill-name pdf
# ビューアー起動(ブラウザで結果確認)
nohup python eval-viewer/generate_review.py \
workspace/iteration-1 \
--skill-name "pdf" \
--benchmark workspace/iteration-1/benchmark.json \
> /dev/null 2>&1 &
Step 5: フィードバック読み取り — ユーザーがビューアーでレビューを提出するとfeedback.jsonで受信
1
2
3
4
5
6
7
{
"reviews": [
{"run_id": "eval-0-with_skill", "feedback": "チャートに軸ラベルがない"},
{"run_id": "eval-1-with_skill", "feedback": ""},
{"run_id": "eval-2-with_skill", "feedback": "完璧"}
]
}
空のフィードバックは「満足」を意味する。具体的な不満があるケースに集中して改善する。
5. ベンチマークシステム
5-1. ベンチマークレポート構造
ベンチマーク完了後、benchmark.jsonに詳細統計が記録される:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"run_summary": {
"with_skill": {
"pass_rate": {"mean": 0.85, "stddev": 0.05},
"time_seconds": {"mean": 45.0, "stddev": 12.0},
"tokens": {"mean": 3800, "stddev": 400}
},
"without_skill": {
"pass_rate": {"mean": 0.35, "stddev": 0.08},
"time_seconds": {"mean": 32.0, "stddev": 8.0},
"tokens": {"mean": 2100, "stddev": 300}
},
"delta": {
"pass_rate": "+0.50",
"time_seconds": "+13.0",
"tokens": "+1700"
}
}
}
主要指標:
- pass_rate — スキル使用時の通過率 vs 未使用時の通過率(mean ± stddev)
- time_seconds — 実行時間比較
- tokens — トークン使用量比較
- delta — 差分値
上記の例ではスキルが通過率を+50%上げる代わりに、実行時間+13秒とトークン+1700個のコストがかかる。
5-2. スキル廃止判断基準
| ベンチマーク勝率 | 解釈 | アクション |
|---|---|---|
| 70%以上 | スキルが確実に有用 | 維持 |
| 50〜70% | 改善の余地あり | モデルアップデート後に再検討 |
| 50%未満 | スキルがむしろ妨げ | 削除または完全書き直し |
モデルアップグレード後のリグレッション確認がベンチマークの核心的な用途だ。新モデルがリリースされた時:
- 既存ベンチマークを再実行
- スキル使用/未使用間の差が縮まった → モデルがその機能を吸収中
- 差がほとんどない → スキル廃止を検討
5-3. ブラインド比較(Blind Comparison)
より厳密な比較が必要な時に使用する高度な機能:
- Comparatorエージェントに2つの出力物をA、Bとして匿名化して渡す
- どちらがスキル適用側か知らない状態でcontent、structure、usability基準で採点
- Analyzerエージェントがなぜ勝者が勝ったかを分析 → 改善インサイトを導出
1
2
3
4
5
6
7
{
"winner": "A",
"rubric": {
"A": {"content_score": 4.7, "structure_score": 4.3, "overall_score": 9.0},
"B": {"content_score": 2.7, "structure_score": 2.7, "overall_score": 5.4}
}
}
6. Improveモード — 反復改善の哲学
6-1. 改善原則4つ
Skill Creator実装で明示されている改善哲学:
1. 一般化せよ(Generalize)
「我々は数百万回使用されるスキルを作っている。テストケース2〜3個にオーバーフィットしても無意味だ。」
特定のテストケースにだけ合わせた細かい修正より、別のメタファーやパターンを試す方が効果的だ。
2. 簡潔に保て(Keep Lean)
トランスクリプト(実行記録)を読んで、スキルがモデルに非生産的な作業をさせている部分を見つけて除去する。最終出力だけでなく実行プロセスを分析することが核心だ。
3. 理由を説明せよ(Explain the Why)
1
2
3
4
5
6
7
# Bad — 強圧的
ALWAYS use pdfplumber. NEVER use other libraries.
# Good — 理由を説明
Use pdfplumber for text extraction because it handles
multi-column layouts reliably. Other libraries (pypdf, PyMuPDF)
struggle with complex table structures.
「現代のLLMは賢い。Theory of Mindがあるので理由を理解すれば、指示にないエッジケースでも正しく判断する。」
4. 反復作業をバンドルせよ(Bundle Repeated Work)
テスト実行トランスクリプトでサブエージェントたちが独立に同じヘルパースクリプトを作成したパターンが見られたら、そのスクリプトをscripts/にバンドルする。毎回車輪を再発明する無駄を防止する。
6-2. イテレーションループ
1
2
3
4
5
1. スキル改善を適用
2. すべてのテストケースを新しいiteration-N+1/ディレクトリで再実行(baseline含む)
3. --previous-workspaceで前のイテレーションと比較するビューアーを起動
4. ユーザーレビューを待機
5. フィードバック読み取り → 改善 → 反復
終了条件:
- ユーザーが満足
- すべてのフィードバックが空欄(= 全部OK)
- 意味のある進展がない時
7. Description最適化 — トリガーチューニング
7-1. なぜ重要か
descriptionはスキルが自動実行されるかを決定する唯一のメカニズムだ。Claudeがユーザーメッセージを受け取ると、すべてのスキルのdescriptionを走査して関連するスキルを選択する。書店で本の表紙と帯だけを見て選ぶようなものだ。
現在Claudeは過少トリガー(undertrigger)の傾向がある。つまり、助けになるスキルがあっても使わないケースが多い。Description最適化はこの問題を直接解決する。
7-2. 最適化プロセス
Step 1: トリガーEvalクエリ20個を生成
should-trigger 8〜10個 + should-not-trigger 8〜10個を作成:
1
2
3
4
5
6
7
8
9
10
[
{
"query": "上司がQ4 sales final FINAL v2.xlsxファイルを送ってきた。C列が売上でD列がコストだって。利益率カラムを追加して",
"should_trigger": true
},
{
"query": "フィボナッチ関数を書いて",
"should_trigger": false
}
]
良いクエリの特徴:
- 現実的で具体的(ファイルパス、会社名、タイポ、カジュアルな口調)
- should-not-triggerは近接失敗(near-miss)中心 — 「フィボナッチ」のように明らかに無関係なものはテスト価値がない
- 多様な長さ、トーン、表現方式
Step 2: HTMLレビューアーでユーザー確認
生成されたクエリセットをHTMLインターフェースで表示し、ユーザーが編集/追加/削除後にエクスポートする。
Step 3: 自動最適化ループ実行
1
2
3
4
5
6
python -m scripts.run_loop \
--eval-set eval_set.json \
--skill-path ./my-skill \
--model claude-sonnet-4-6 \
--max-iterations 5 \
--verbose
内部動作:
- Evalセットを60%学習 / 40%検証に分割
- 各クエリを3回実行して信頼性のあるトリガー率を測定
- Extended Thinkingで失敗原因分析 + 改善案を提案
- 最大5回反復
- 検証セット(40%)スコア基準でbest descriptionを選択(オーバーフィッティング防止)
Step 4: 結果を適用
最適化されたdescriptionをSKILL.mdフロントマターに反映し、前後のスコアを確認する。
7-3. トリガーメカニズムの限界
Claudeは簡単なタスクにはスキルをあまり使わない。「このPDF読んで」のように基本ツールだけで解決可能なリクエストには、descriptionが完璧でもスキルがトリガーされない場合がある。複雑でマルチステップなリクエストほどスキルトリガー確率が高い。
したがって、Evalクエリも十分に複雑なリクエストで作成してこそ意味のあるテストになる。
8. スキル作成ベストプラクティス
公式ドキュメントで強調されている核心パターン:
8-1. 自由度の調整
| 状況 | 自由度 | 例 |
|---|---|---|
| 複数のアプローチが有効な時 | 高 | “コード構造を分析し、潜在的なバグを確認し…” |
| 好みのパターンがある時 | 中 | パラメータ化されたスクリプトテンプレート |
| タスクが脆弱または順序が厳密な時 | 低 | “この正確なコマンドを実行: python scripts/migrate.py --verify” |
Anthropicの比喩:崖の両側の狭い橋では正確なガードレールが必要だが、危険のない広い野原では方向だけ示してClaudeを信頼せよ。
8-2. フィードバックループパターン
1
実行 → 検証 → エラー発見時修正 → 再検証 → 通過時進行
1
2
3
4
5
6
7
8
9
10
## ドキュメント編集プロセス
1. `word/document.xml`を修正
2. **即時検証**: `python scripts/validate.py unpacked_dir/`
3. 検証失敗時:
- エラーメッセージを確認
- XMLを修正
- 再検証
4. **検証通過後にのみ**進行
5. リビルド: `python scripts/pack.py unpacked_dir/ output.docx`
8-3. ファイル参照は1段階の深さまで
1
2
3
4
5
6
7
# Good — SKILL.mdから直接参照
**基本的な使い方**: [ここに説明]
**高度な機能**: [advanced.md](advanced.md)参照
**APIリファレンス**: [reference.md](reference.md)参照
# Bad — 2段階以上のネスト
SKILL.md → advanced.md → details.md (Claudeが不完全に読む可能性あり)
9. プラットフォーム別の違い
Skillsは複数のClaudeプラットフォームで使用可能だが、環境によって違いがある:
| プラットフォーム | カスタムスキル | プリビルトスキル | サブエージェント | ネットワーク |
|---|---|---|---|---|
| Claude Code | O(ファイルシステム) | — | O | フルアクセス |
| Claude.ai | O(ZIPアップロード) | O(PPTX, XLSX, DOCX, PDF) | X | 設定次第 |
| Claude API | O(APIアップロード) | O | — | X |
| Agent SDK | O(ファイルシステム) | — | — | — |
Claude.aiでの制限:
- サブエージェントなし → 並列評価不可、順次実行のみ
- ブラインド比較不可
- Description最適化(
run_loop.py)不可 —claude -pCLIが必要
Claude APIでの制限:
- ネットワークアクセスなし
- ランタイムパッケージインストール不可 — プリインストールパッケージのみ使用
10. 実践活用ガイド — ゼロからスキルを作る
初めてスキルを作るなら、この順序に従ってみよう:
Step 1: 繰り返すタスクパターンを認識
「このタスクをするたびに同じ説明を繰り返している」→ スキル候補
Step 2: Claudeと一緒にタスクを1回完遂
スキルなしでClaudeに直接タスクをやらせてみる。このプロセスで自然と提供するコンテキスト、好み、手続き的知識を観察する。
Step 3: Skill Creatorでスキルを作成
1
2
Claudeに: "さっきやったBigQuery分析パターンをスキルにして。
テーブルスキーマ、命名規則、テストアカウントフィルタリングルールを含めて。"
Claudeはスキルの形式と構造を基本的に理解している。特別なシステムプロンプトなしに「スキルを作って」と言えば適切なSKILL.mdを生成する。
Step 4: 簡潔性のレビュー
「この説明はClaudeに本当に必要か?」→ 不要な説明を削除
Step 5: テストと反復
新しいインスタンス(Claude B)でスキルを使って実際のタスクを実行し、観察結果を元のインスタンス(Claude A)にフィードバックする:
1
2
"Claude Bが地域別売上レポートを作成したけど、テストアカウントフィルタリングを忘れた。
スキルには記載されているけど、目立たないみたいだ。"
Step 6: チームフィードバックの反映
チームメンバーにスキルを共有し、使用パターンを観察する:
- スキルが期待したタイミングでトリガーされるか?
- 指示は明確か?
- 抜けはないか?
まとめ
Skills 2.0の核心は「スキルもソフトウェアのようにテストし管理せよ」ということだ。
| 従来 | Skills 2.0 |
|---|---|
| SKILL.mdに指示を記述 | 4つのモード(Create・Eval・Improve・Benchmark) |
| トリガー有無を感覚で判断 | 自動最適化ループ + 数値ベースの判断 |
| スキルの良し悪しを主観的評価 | A/Bテスト + ブラインド比較 + 統計レポート |
| モデルアップグレード時に祈る | ベンチマークでリグレッション検出 + 廃止判断 |
| フロントマターはname/descriptionのみ | context、model、effort、hooks、agentなど精密な制御 |
1つのスキルをしっかり作っておけば、数千、数万回の反復タスクで一貫した品質が保証される。そして今、その「しっかり作る」プロセス自体が自動化された。
参考資料: