
Does AGENTS.md Really Help? - Analysis of a Paper Verifying the Impact of Context Files on Coding Agents

- AI in Game Development: Insights from 2,165 Messages - A Developer's 47-Day Log
- Claude Opus 4.5 → 4.6 Transition: Performance, Tokens, Workflow Changes Experienced by a Game Developer
- Does AGENTS.md Really Help? - Analysis of a Paper Verifying the Impact of Context Files on Coding Agents
- Claude Memory Goes Free, /simplify & /batch — and the Hidden Cost of CLAUDE.md
- Complete Guide to Installing Claude Code on Windows — With Real-World Troubleshooting
- 게임 기획자를 위한 Claude Code 완전 활용 가이드 — 사양서부터 밸런싱까지
- While context files like AGENTS.md and CLAUDE.md have been adopted by over 60,000 repositories, LLM-generated context files can actually degrade performance and increase costs by more than 20%.
- The primary cause is redundancy with existing documentation — when documents were removed, context files showed a +2.7% performance improvement, proving that information overload is the issue.
- Only minimal context files directly written by developers show a slight positive effect, and specific tooling requirements are more useful than general codebase overviews.

Introduction
When using Claude Code, writing a CLAUDE.md file has become a near-default workflow. OpenAI’s Codex recommends AGENTS.md, and Anthropic’s Claude Code suggests CLAUDE.md. These context files have now been adopted by over 60,000 open-source repositories.
But do these files really improve agent performance? Researchers from ETH Zurich and Anthropic conducted the first large-scale empirical study on this question. The results are quite different from industry conventional wisdom.
Paper: “Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?” Authors: Thibaud Gloaguen, Niels Mündler, Mark Müller, Veselin Raychev, Martin Vechev (ETH Zurich / Anthropic) arXiv: 2602.11988
1. Background: What are Context Files?
Context files for coding agents are Markdown files located at the repository root. They serve to inform the agent about the project structure, build methods, coding rules, and more.
| Agent | Filename | Developer |
|---|---|---|
| Claude Code | CLAUDE.md | Anthropic |
| Codex | AGENTS.md | OpenAI |
| Cursor | .cursorrules | Cursor |
| Windsurf | .windsurfrules | Codeium |
Common components of these files:
- Codebase Overview: Directory structure, descriptions of key modules.
- Build/Test Commands:
npm test,bundle exec jekyll serve, etc. - Coding Conventions: Naming rules, style guides.
- Project-Specific Requirements: Use of specific tools, precautions.
The industry has expected that providing these files would help agents understand projects better and generate more accurate code. But is that actually the case?
2. Experimental Design
2-1. Evaluation Pipeline
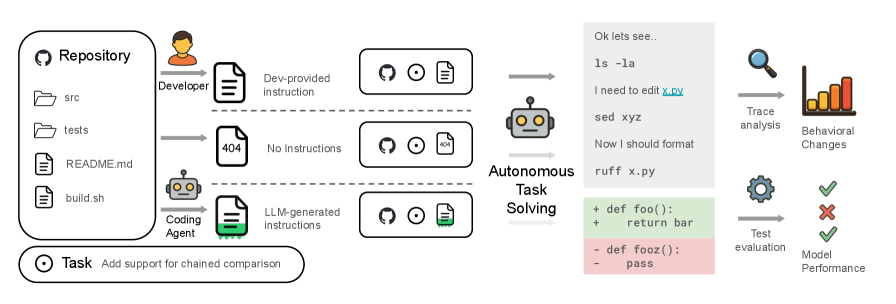 Figure 1. Overview of the evaluation pipeline. The agent solves tasks under three conditions (Developer-written context / No context / LLM-generated context), and the generated patches are evaluated with unit tests.
Figure 1. Overview of the evaluation pipeline. The agent solves tasks under three conditions (Developer-written context / No context / LLM-generated context), and the generated patches are evaluated with unit tests.
The researchers compared three conditions:
- None — Working without a context file.
- LLM — Providing a context file automatically generated by an LLM.
- Human — Providing a context file directly written by a developer.
2-2. Benchmarks
SWE-bench Lite (Existing Benchmark)
- 300 tasks from 11 popular Python repositories.
- Well-known projects like Django, scikit-learn, and sympy.
- Since original repositories lacked context files, only None vs. LLM could be compared.
AGENTbench (Newly created for this paper)
- 138 instances from 12 niche Python repositories where developer-written context files actually exist.
- Allows comparison across all three conditions: None, LLM, and Human.
- Carefully curated from 5,694 PRs.
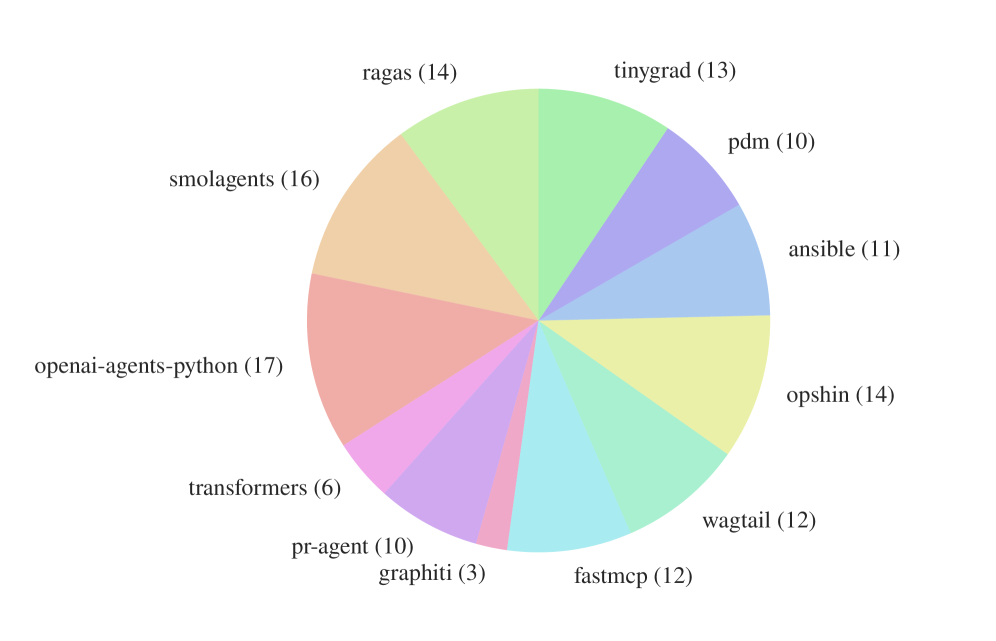 Figure 2. Distribution of AGENTbench instances across 12 open-source repositories. Compared to SWE-bench, it is more evenly distributed across repositories rather than being biased toward specific ones.
Figure 2. Distribution of AGENTbench instances across 12 open-source repositories. Compared to SWE-bench, it is more evenly distributed across repositories rather than being biased toward specific ones.
AGENTbench Statistics
| Metric | Average | Minimum | Maximum |
|---|---|---|---|
| PR Body Length (words) | 415.3 | 5 | 4,961 |
| Issue Description (words) | 211.6 | 96 | 500 |
| Codebase File Count | 3,337 | 151 | 26,602 |
| PR Patch Line Count | 118.9 | 12 | 1,973 |
| Files Modified | 2.5 | 1 | 23 |
| Test Coverage | 75% | 2.5% | 100% |
| Context File Length (words) | 641.0 | 24 | 2,003 |
| Context File Section Count | 9.7 | 1 | 29 |
2-3. Agents Tested
| Agent | Model | Developer |
|---|---|---|
| Claude Code | Sonnet-4.5 | Anthropic |
| Codex | GPT-5.2 | OpenAI |
| Codex | GPT-5.1 mini | OpenAI |
| Qwen Code | Qwen3-30b-coder | Alibaba |
They evaluated 4 major coding agents across 2 benchmarks and 3 conditions — testing a total of 20 experimental combinations.
3. Key Results: The Context File Paradox
3-1. Impact on Performance
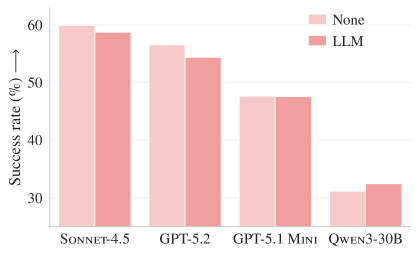 Figure 3a. Resolve rate on SWE-bench Lite. Across all four models, the LLM-generated context file (orange) shows an equal or lower success rate compared to no context (blue).
Figure 3a. Resolve rate on SWE-bench Lite. Across all four models, the LLM-generated context file (orange) shows an equal or lower success rate compared to no context (blue).
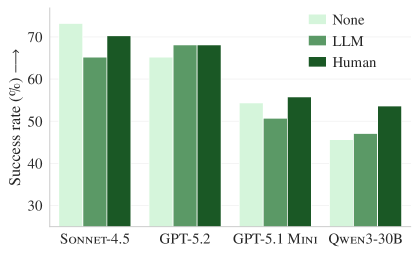 Figure 3b. Resolve rate on AGENTbench. Developer-written context (green) shows slight improvement, but LLM-generated context (orange) still degrades performance.
Figure 3b. Resolve rate on AGENTbench. Developer-written context (green) shows slight improvement, but LLM-generated context (orange) still degrades performance.
Summary of Results:
| Condition | SWE-bench Lite | AGENTbench |
|---|---|---|
| LLM-Generated Context | -0.5% Success Rate ↓ | -2% Success Rate ↓ |
| Developer-Written Context | (Not testable) | +4% Success Rate ↑ |
Context files automatically generated by LLMs degraded performance on both benchmarks. Even files written directly by developers showed only a marginal improvement. These results directly conflict with the industry recommendation to “always write context files.”
3-2. Costs Certainly Increase
On the other hand, costs definitely increased.
| Model | Dataset | Cost (None) | Cost (LLM) | Cost (Human) |
|---|---|---|---|---|
| Sonnet-4.5 | SWE-bench | $1.30 | $1.51 (+16%) | — |
| GPT-5.2 | SWE-bench | $0.32 | $0.43 (+34%) | — |
| Sonnet-4.5 | AGENTbench | $1.15 | $1.33 (+16%) | $1.30 (+13%) |
| GPT-5.2 | AGENTbench | $0.38 | $0.57 (+50%) | $0.54 (+42%) |
| GPT-5.1 mini | AGENTbench | $0.18 | $0.20 (+11%) | $0.19 (+6%) |
| Qwen3-30b | AGENTbench | $0.13 | $0.15 (+15%) | $0.15 (+15%) |
An average cost increase of over 20%, but without a corresponding performance gain. In other words, context files have a negative return on investment (ROI).
4. Why are Context Files Harmful?
4-1. Information Redundancy with Existing Docs
This is the most critical discovery of the paper.
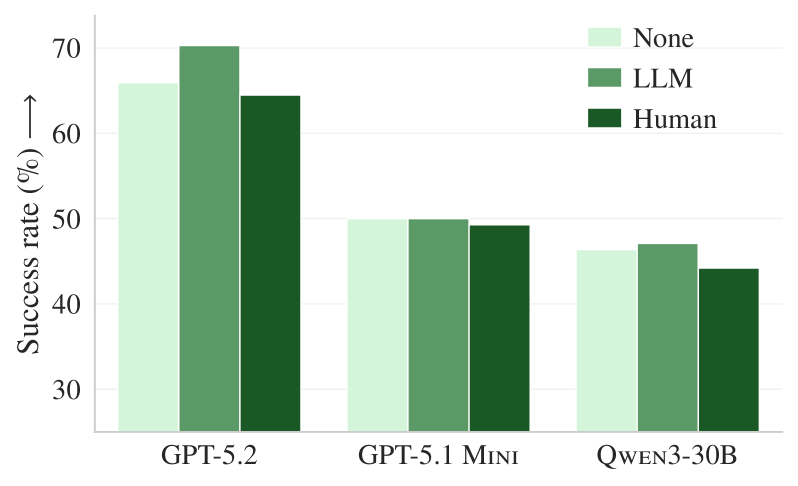 Figure 5. AGENTbench results after removing existing documentation. When documents are absent, the LLM-generated context file (orange) shows an average +2.7% performance improvement, outperforming even the developer-written file (green).
Figure 5. AGENTbench results after removing existing documentation. When documents are absent, the LLM-generated context file (orange) shows an average +2.7% performance improvement, outperforming even the developer-written file (green).
The researchers re-ran the experiment after removing all .md files, example code, and docs/ folders from the repositories. The results:
- With docs: LLM context file causes a -2% performance drop.
- Without docs: LLM context file provides a +2.7% performance improvement.
This proves that context files generated by LLMs contain nearly the same information as READMEs and documentation already present in the repo. Redundant information confuses the agent.
To use a game development analogy, it’s like loading the same texture twice under different names. It only wastes memory without improving rendering quality.
4-2. No Improvement in File Discovery Speed
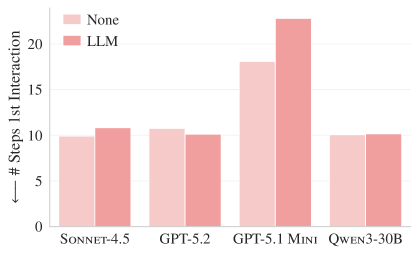 Figure 4a. Number of steps taken by the agent to first interact with a relevant file on SWE-bench Lite.
Figure 4a. Number of steps taken by the agent to first interact with a relevant file on SWE-bench Lite.
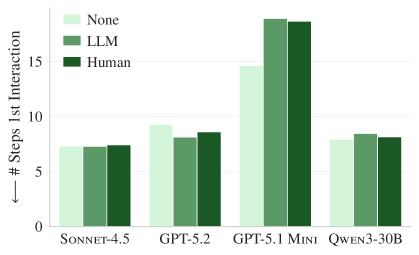 Figure 4b. The same pattern on AGENTbench. Having a context file does not help find relevant files any faster.
Figure 4b. The same pattern on AGENTbench. Having a context file does not help find relevant files any faster.
One might expect that a codebase overview in a context file would help an agent find relevant files faster, but in reality, it took 15 to 25 steps regardless of the presence of a context file. This means codebase overviews do not contribute to file exploration efficiency.
4-3. Increased Tool Use but Static Accuracy
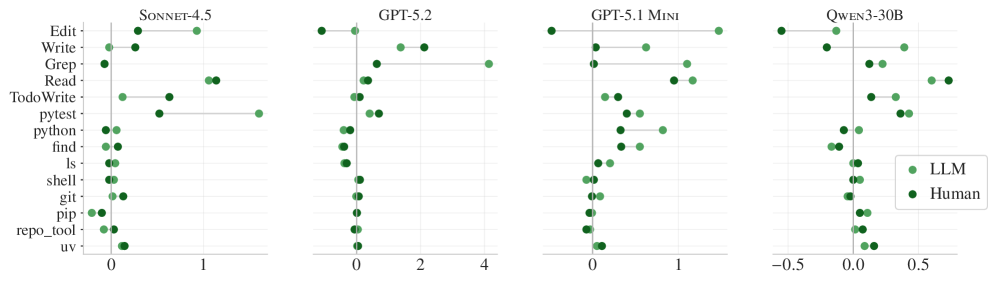 Figure 6. Average increase in tool use when context files are included. Use of almost all tools, including grep, tests, and file reading, increases, but the success rate does not.
Figure 6. Average increase in tool use when context files are included. Use of almost all tools, including grep, tests, and file reading, increases, but the success rate does not.
Agent behavioral changes when context files are present:
- grep use: +30-50% increase.
- test execution: +40-100% increase.
- repo-specific tools: Used 2.5x more when mentioned in the context file.
- package managers (e.g., uv): Used 1.6x more when mentioned.
Agents faithfully follow the instructions in the context file. The problem is that following those instructions does not lead to better results. It’s a form of “diligent inefficiency” — more searching and more testing, but without getting any closer to the correct answer.
4-4. Increased Reasoning Token Consumption
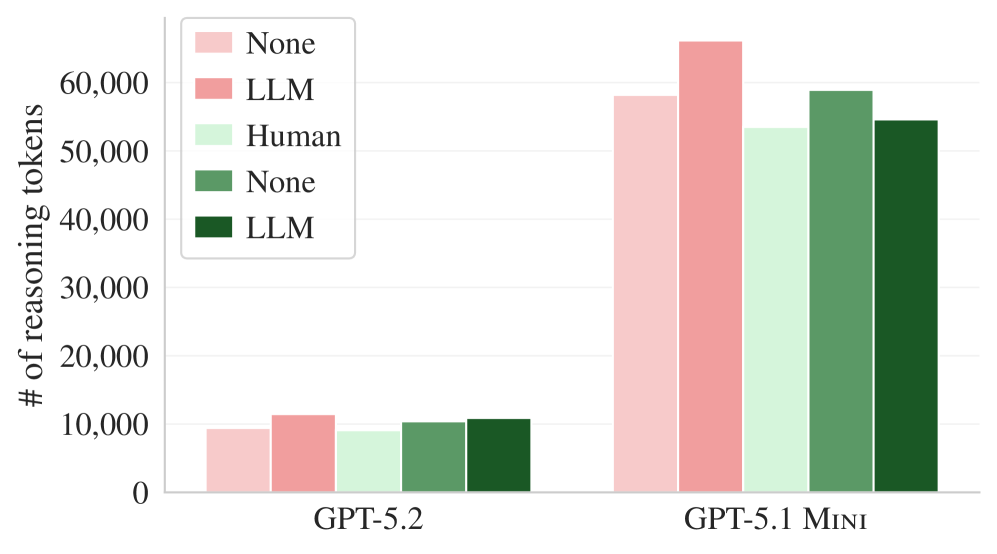 Figure 7. Average reasoning token usage for GPT-5.2 and GPT-5.1 mini. When a context file is present, more tokens are consumed for reasoning.
Figure 7. Average reasoning token usage for GPT-5.2 and GPT-5.1 mini. When a context file is present, more tokens are consumed for reasoning.
| Model | Reasoning Token Increase (LLM Context) | Reasoning Token Increase (Human Context) |
|---|---|---|
| GPT-5.2 | +22% | +20% |
| GPT-5.1 mini | +14% | +2% |
Agents consume more tokens as they process the context file and reflect its instructions in their reasoning. Since this extra reasoning doesn’t lead to better results, it is pure waste.
5. Why Did This Happen?
Synthesizing the findings of the paper reveals the following mechanism:
1
2
3
4
5
6
7
8
9
10
11
Context File Provided
├── Agent faithfully follows instructions ✅
│ ├── More tool use (grep, test, etc.)
│ ├── Wider exploration range
│ └── More reasoning tokens consumed
│
├── But information is redundant ❌
│ ├── Same content as README, docs/
│ └── Information the agent can already access
│
└── Result: Cost ↑, Performance ↔ or ↓
Key Insight: The issue isn’t a lack of “instruction-following ability” in agents, but rather the information quality of the instructions themselves. Repeatedly telling an agent information it can already discover on its own only broadens the exploration scope and increases costs.
6. So, What Should We Do?
Recommendations from the Paper
For Repository Maintainers:
| What NOT to do | What to do |
|---|---|
| Auto-generate context files with LLMs | Manually write only minimal essential information |
| Describe the entire codebase structure | Describe only project-specific unique requirements |
| Write long and detailed context files | Provide short and specific instructions |
For Agent Developers:
- Reconsider recommending automatic context file generation.
- Focus on improving the utilization of existing context rather than generating more context.
How to Write Effective Context Files
Based on the paper’s conclusions, here is a summary of what is worth including in a context file and what is not:
Information worth including (unique to the repo, not in docs):
1
2
3
4
5
6
7
8
9
10
11
# Build Commands (Project-specific)
bundle exec jekyll serve # Local development
JEKYLL_ENV=production bundle exec jekyll build # Production
# Special Tool Requirements
- Use 'uv' as the package manager
- Always run tests with 'pytest-asyncio'
# Project-specific Rules
- Use '.en.md' and '.ja.md' suffixes for translation files
- Store images under 'assets/img/post/{category}/'
Information to exclude (already in documentation):
1
2
3
4
5
6
7
8
9
# ❌ Codebase Structure Overview (Agent can explore directly)
src/
components/ — React components
utils/ — Utility functions
...
# ❌ General Coding Rules (LLM has already learned these)
- Use camelCase for variable names
- Functions should follow the Single Responsibility Principle
7. Limitations and Future Research
This paper is not the final word. Some limitations include:
- Focused on Python projects: The results are from Python repos well-represented in training data. Context files might be more useful in niche languages like Rust or Zig, or in specialized domains like game engines.
- Measured only task resolve rate: Other metrics like code quality, security, and style consistency were not evaluated.
- Single-task basis: The cumulative effect of repeatedly working on the same repo in a long-term project was not verified.
- Limitations of SWE-bench: Since it focuses on popular repos, the LLM may have already encountered the code in its training data.
Future Research Directions
- The impact of context files in niche programming languages.
- Evaluation of impact on code efficiency and security.
- Methods for automatically generating a truly useful minimal context file.
8. Applying This to This Blog
This blog (Epheria) is a Jekyll-based static site, and I have a fairly detailed CLAUDE.md file. Applying the paper’s conclusions:
Information worth keeping:
- Build commands like
bundle exec jekyll serve— Project-specific. jekyll-polyglotmultilingual rules (.en.md,.ja.mdsuffixes) — Unique project rules not in standard documentation.- Post front matter format — Non-standard settings due to Chirpy theme customization.
assets/img/post/{category}/image rules — Project-specific convention.
Information to reconsider:
- Listing the entire directory structure — Agent can explore this directly.
- Statistics on the number of posts by category — Informative, but may not contribute to agent performance.
- General coding style rules — Already defined in
.editorconfig.
However, since this blog is a niche project with many Jekyll + Chirpy customizations rather than a “popular Python repo,” it’s more reasonable to refine the context file with project-specific information rather than following the “omit context file” recommendation literally.
Conclusion
The conclusion of this paper can be summarized in one sentence:
“Don’t tell the agent what it already knows.”
Context files themselves are not bad. Including redundant information is what’s bad. Minimal context files containing only project-specific information, written directly by developers rather than auto-generated by LLMs, still showed a slight positive effect.
When writing a context file, ask yourself: “Can the agent figure this out on its own by exploring the repo?” If the answer is “yes,” it’s better not to include it in the context file.
References
- Gloaguen, T., Mündler, N., Müller, M., Raychev, V., & Vechev, M. (2026). Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? arXiv:2602.11988. https://arxiv.org/abs/2602.11988
- OpenAI. (2026). Custom instructions with AGENTS.md. https://developers.openai.com/codex/guides/agents-md/
- Anthropic. (2026). Claude Code Documentation — CLAUDE.md. https://docs.anthropic.com/en/docs/claude-code